
One customer call can delete a dozen tickets. Across more than 35 complex engagements, one 45-minute customer session has replaced 6 to 12 planned backlog items. The replacement is usually one API change, one workflow revision, one state model correction, or one data ownership rule. Senior engineers make better architecture decisions when they hear the customer’s operating constraint directly.
Product teams often shield engineers from customer exposure to protect focus. That choice creates filtered context, unnecessary complexity, and repeated implementation cycles. Teams then build against surface requests while the operating constraint remains unresolved. This problem affects non-technical founders, enterprise product owners, and teams working with an external engineering studio. The collaboration model determines the quality of input engineers receive. Practices like continuous product discovery put the team building the product in front of customers regularly, rather than learning through summaries. Production-ready software requires raw operating context, including sequence, authority, exception frequency, and data meaning.
Filtered customer context creates avoidable architecture
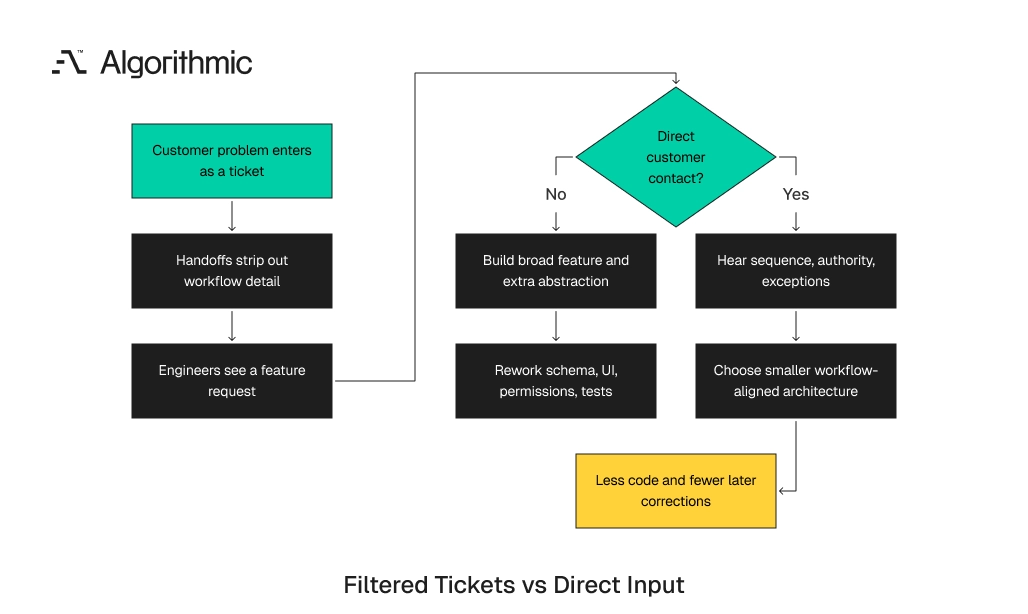
A ticket records a request. It rarely describes the work the customer must complete. By the time a customer problem reaches engineering, it has often passed through support, account management, product management, and prioritization meetings. Each handoff removes detail, changes emphasis, or compresses the operating context into a feature label. The final ticket looks tidy because the difficult parts have been removed.
A ticket can say, “Add bulk edit for contract terms”. The customer constraint can be more exact. Their finance team receives contract changes every Thursday and must preserve approval state across 200 active records. Those inputs produce different engineering decisions. The ticket points toward a broad editing interface. The customer constraint points toward state management, validation, and controlled batch processing.
A broad bulk edit feature creates a large UI surface, a form of speculative generality that adds cost before it earns its place. It also adds permission rules, audit changes, and exception handling across several screens. A narrower design can use a batch import endpoint, validation states, a review interface, and a data model that separates proposed terms from approved terms. The second design creates less code and matches the work pattern. It also gives support teams a clearer explanation when a record cannot move forward. The architecture serves the workflow instead of preserving a generic feature request.
 Click to expand
Click to expand Ticket aggregation tools still have a place. A unified pipeline for support, roadmap, and backlog items reduces duplicate intake and shows repeated pain. That pipeline organizes signals; senior engineers still need direct observation before they set architecture boundaries. The distinction matters during early architecture work. Once a team sets a data model, every later feature inherits its assumptions. A poor abstraction compounds through APIs, reports, permissions, tests, analytics events, and migration scripts.
In one contract-management build, the original backlog contained 47 tickets. Twelve tickets described bulk actions, role exceptions, approval state, and reporting gaps. One customer session reduced that group to three architecture decisions. The team split proposed and approved terms. It stored approval history as an event stream. It exposed a batch validation endpoint for controlled contract changes.
That change reduced planned UI work by four screens. It also removed two permission models that would have created conflicting authority rules. The customer still received the required behavior because the team solved the work sequence. The same pattern appears in internal operations software. A product owner asks for a dashboard because teams cannot see delayed work. Direct customer contact reveals that delays come from one missing handoff state between operations and finance.
A dashboard would report the delay after it occurred. A workflow state prevents the delay from disappearing between teams. The better architecture is usually a smaller one when engineers hear the operating sequence.
What senior engineers hear in customer conversations
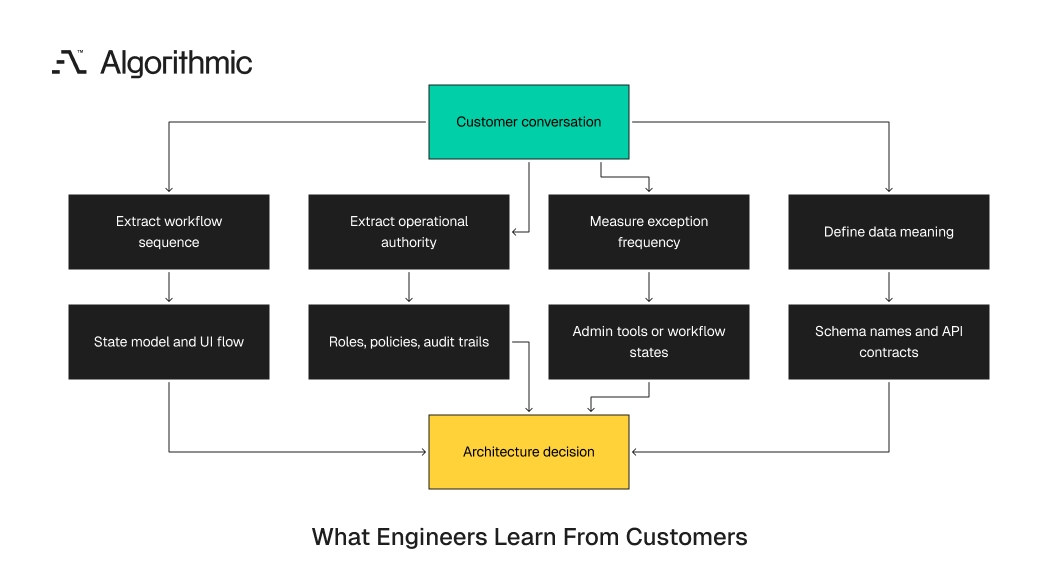
Senior engineers listen for constraints that rarely survive summarization. They hear sequence, exception handling, authority, latency, data meaning, and failure cost, all architecture inputs. A strong engineer records more than feature requests. They identify where the system must preserve state, enforce rules, recover from errors, and explain decisions to users. Those details determine the architecture.
Customer conversations also expose the vocabulary of the business. Two customers can use the same word for different records, events, or approvals. Engineers need that language before they name tables, events, and APIs.
 Click to expand
Click to expand Workflow sequence
Customers describe work in order. Tickets often describe desired outputs. A logistics user can request “better shipment search”. In conversation, the engineer hears the dispatch pattern. Dispatchers search by customer nickname, filter by dock assignment, then call the warehouse when results exceed 20 rows.
That context changes the technical answer. The system can need a saved operational view, a denormalized search index, or a role-specific dashboard. A new search field alone leaves the dispatch process unchanged. The decision sequence drives the design. It tells the engineer where latency matters, where precision matters, and where the interface must reduce judgment calls. A two-second delay can work during reporting and fail during live dock assignment.
Workflow sequence also exposes batch timing. A user who processes changes every Thursday has different constraints from a user who works continuously throughout the day. The same feature label hides different timing models. In a field-services scheduling product, two customers requested “calendar improvements”. The first customer needed a weekly planning board for 40 technicians and 600 service appointments. The second customer needed same-day rescheduling after failed access attempts.
Those requests belonged to different architectures. The weekly planning use case needed capacity planning, route grouping, and drag-and-drop reassignment. The same-day use case needed mobile status updates, notification windows, and conflict detection. A single calendar backlog item would have blended both cases. Direct engineer contact separated the planning model from the dispatch model. The final design used one shared appointment entity, two workflow surfaces, and one status transition table.
Sequence also changes test design. A team testing only the final output misses failures that occur between handoffs. A test suite must cover the order of decisions, not only the final record state. For example, appointment scheduling often includes request, confirmation, travel, arrival, service start, completion, and invoice creation. Each state has a different owner. Each transition can fail for a different reason.
When engineers hear that order directly, they avoid false shortcuts. They can design state transitions, event logs, and notification rules around the work as performed. That structure reduces later correction work.
Operational authority
Enterprise workflows depend on who can approve, reverse, escalate, or override an action. Customers often treat these rules as obvious because they live with them daily. Tickets usually compress them into one line. A product owner can specify, “manager approval required”. A customer call reveals the rule set. Regional managers approve up to $25,000, finance approves deferred revenue, and legal reviews contracts containing two named clauses.
That context changes the data model and workflow engine. Approval becomes a policy structure with thresholds, conditions, roles, and audit requirements. It also changes test coverage because each approval path needs verification. Retrofitting authority rules after release is expensive. It touches database schema, API design, permissions, audit trails, fixtures, and regression tests. The cost rises when customer data already exists under the earlier model.
Authority rules also affect product support. When the system cannot explain why a user lacks approval rights, support teams absorb avoidable tickets. Clear rules inside the architecture reduce those contacts. In one enterprise procurement workflow, the first design treated approval as a single boolean field. The customer session exposed six approval states, three override paths, and two finance audit reports. The team replaced the boolean with an approval event table before implementation started.
That decision prevented a later migration across purchase orders, invoices, and budget reports. It also gave the support team an exact answer to customer questions. Support could see who approved, when they approved, what rule applied, and which user changed the state. Authority also determines how systems handle reversals. A user who can approve an order does not automatically have the right to reverse it. Reversal often carries a different audit obligation and a different notification path.
Engineers need those rules before they design permissions. A single “admin” role becomes expensive when production use requires finance administrators, regional managers, legal reviewers, and support operators. Role design must reflect the authority model, not the org chart alone.
Exception frequency
Teams overbuild for rare exceptions and underbuild for common exceptions when they rely on processed requests. Frequency determines whether an exception belongs in an admin screen or the central workflow. A customer can request an admin tool for “occasional corrections”. During direct discussion, engineering learns corrections occur in 18% of transactions during month-end close. That volume makes correction handling part of normal operations.
This distinction shapes system design. A rare correction needs controlled access and logging. A frequent correction needs a state machine, validation, observability, and reporting. Exception frequency also affects data integrity. If operators use manual workarounds every week, the system accumulates inconsistent records. Direct customer contact shows where workarounds have become routine.
A finance workflow provides a common example. If reconciliation exceptions occur twice a quarter, a supervised admin path works. If exceptions occur every Friday across 300 invoices, reconciliation needs dedicated states, bulk review, and a report that separates timing differences from data errors. The architecture decision changes because the work frequency changes. An admin screen hides repeated work from the product. A state model makes repeated work visible, measurable, and controllable.
Frequency should be measured during discovery. Engineers should ask how many records hit the exception, how often it occurs, and which team clears it. They should also ask what happens when the exception waits for 24 hours. Failure cost matters as much as volume. A low-frequency exception in a payment, compliance, or safety workflow can still deserve first-class treatment. Direct customer contact exposes the operating consequence of each failure.
Data meaning
Customers use the same word for different data states. Engineers need to hear the usage before they name database fields, API resources, and analytics events. “Status” is the usual failure point. In one customer’s workflow, status means legal approval. In another, it means inventory readiness. In a logistics system, it can mean dock assignment, carrier pickup, or proof-of-delivery receipt.
A ticket that requests “status visibility” gives engineering too little information. A customer session identifies which status matters, who changes it, who trusts it, and which downstream action depends on it. Those details define the data model. Poor naming creates long-term cost. Once an API exposes a vague status field, reports, integrations, and customer exports adopt that language. Correcting the field later requires migration work and customer communication.
Senior engineers press for the exact meaning early. They ask which user owns the field, which system produces it, which event changes it, and which decision uses it. The answer often removes several planned features because one well-named field replaces a chain of explanations. Data meaning also affects analytics. A metric called “active customer” can include paying accounts, enabled accounts, accounts with recent usage, or accounts with open contracts. Each definition produces a different executive dashboard.
The same risk appears in integration design. If one system treats “contract” as a legal document and another treats it as a commercial term set, synchronization fails. Engineers must define the source of truth before they design the integration boundary. A precise data model reduces later negotiation. Teams spend fewer hours debating reports because the record definitions already exist. Support teams also answer customer questions with less interpretation.
The economics of delayed engineering contact
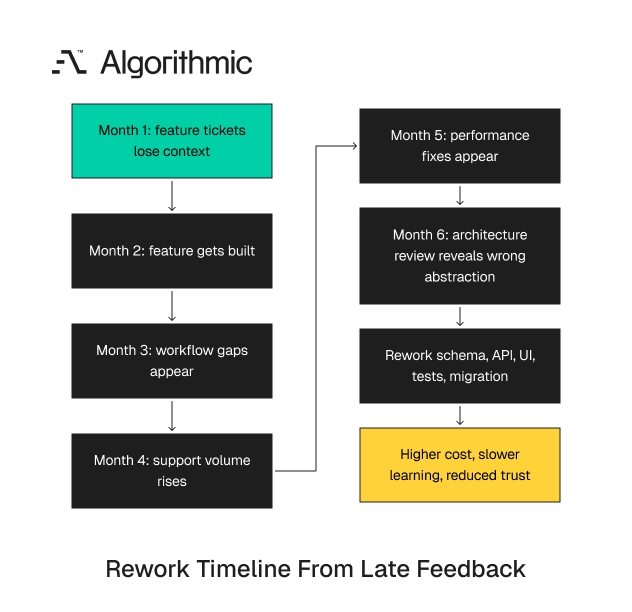
Complexity compounds over the months. A decision made without customer context in month 1 becomes a rework program in month 6. That is the same false economy as a rushed quick MVP. A typical sequence looks like this:
| Month | Team action | Cost created |
|---|---|---|
| 1 | Product converts customer pain into feature tickets | Context loss begins |
| 2 | Engineering builds the requested feature | Data model reflects the ticket instead of the workflow |
| 3 | Customer reports workflow gaps | Team adds exception handling |
| 4 | Support volume rises | Product adds configuration options |
| 5 | Performance issues appear | Engineering adds indexes, queues, and background jobs |
| 6 | Architecture review finds the workflow model was wrong | Rework affects schema, API, UI, tests, and migration scripts |
 Click to expand
Click to expand The engineering team worked throughout the cycle. The waste came from solving the wrong abstraction. Activity created code, tests, and releases without resolving the operating constraint. This pattern appears often in B2B and industrial software. Configured products create extra pressure because sales, product, and technical teams carry product rules in documents, spreadsheets, and personal knowledge. Those manual steps later become software requirements, integration work, and support load.
Manufacturing CPQ shows the same pattern. A sales team asks engineering for quote support because product rules are inaccessible or unclear. The software answer often includes a configurator, product-rule normalization, spec taxonomy cleanup, and a pricing API. The customer-facing symptom appears in sales. The architecture work sits in data, rules, and validation. Senior engineers need access to the customer scenario before they select the technical boundary.
Delayed contact also changes team behavior. Product teams add options to cover gaps. Engineers add background jobs to protect performance. Support teams create internal instructions that become unofficial product logic.
By month 6, the organization owns several partial solutions. Each one has a maintenance cost. A single customer session at the start would have exposed the workflow model before those costs appeared. The financial effect is direct. A 6-person engineering team spending two sprints on rework burns 480 engineering hours before product management, QA, and customer support time. At a blended cost of $125 per hour, that rework consumes $60,000 before opportunity cost.
The same cost often appears again during migration. Data cleanup, customer communication, and support scripts add another 80 to 160 hours. The team pays twice because it built the wrong abstraction first and then trained customers around it. For an early-stage company, that cost delays market learning. For an enterprise product owner, it pushes a launch into the next planning cycle. For an external engineering studio, it erodes trust because visible progress turns into correction work. The remedy is inexpensive, since the responsible senior engineer joining before the architecture locks costs under a day. It often prevents weeks of rework.
The risk profile also changes after release as production data hardens assumptions. Customers build spreadsheets, operating procedures, and training materials around the first version. A later architecture correction then affects more than code. It affects customer enablement, internal support scripts, data migration, security review, and release communication. The longer the delay, the more departments participate in the correction.
Engineering leaders should treat early customer contact as cost control. It is cheaper to rename a field in week 2 than migrate a public API in quarter 3. It is cheaper to model approval states before launch than explain inconsistent approvals to ten enterprise accounts.
Customer contact needs structure
Engineer-to-customer contact fails when it becomes unbounded meeting load. It works when teams define moments, roles, and decision rights before the engagement starts. For an external engineering studio, this structure belongs in the operating model. It belongs in the statement of work, the delivery cadence, and the acceptance process. The structure protects engineering focus while giving architects the context they need.
Direct access does not mean open access. The customer should know when engineers join, why they join, and which decision the session will address. That discipline keeps meetings short and protects delivery pace.
Four moments where engineers should meet customers
-
Discovery of ambiguous workflows. Senior engineers should attend calls where the workflow is unclear, high-value, or constrained by operations. One 60-minute session can change the domain model before implementation starts.
-
Architecture validation before build. When the team proposes a data model, API boundary, or workflow state machine, a customer review should test the abstraction against real operations. The discussion should use customer examples, production documents, and current workarounds.
-
Release acceptance. Engineers should observe customers using the release candidate against real scenarios. A scripted demo hides sequencing errors, permission gaps, and data-entry shortcuts.
-
Post-release review. Within 30 days of launch, engineering should review production usage, support tickets, and customer feedback in one session. This practice stops small deviations from becoming backlog programs.
These moments do not require every engineer. They require the engineer responsible for the architecture decision. Attendance should match the technical risk in the work. A payment workflow needs the engineer who owns billing logic. A compliance workflow needs the engineer responsible for auditability and permissions. A recommendation engine needs the engineer responsible for labels, feedback loops, and failure handling.
The right meeting load is small. In a 12-week build, an architect usually needs four to six customer sessions. Each session should have a decision attached to it, such as a state model, permission rule, data boundary, or acceptance scenario. If a session produces only preference notes, the meeting design failed. The engineer needs a decision to make or verify. The customer needs a scenario specific enough to test that decision.
The session agenda should fit on one page. It should state the decision, the customer scenario, the evidence needed, and the next artifact. Anything else belongs in product discovery or account management.
Roles that prevent confusion
Customer ownership must be explicit before work begins. Ambiguity creates duplicated asks, inconsistent commitments, and acceptance disputes.
Use this checklist before sprint planning, milestone planning, or a fixed-scope build:
- Who speaks for the customer during discovery?
- Who can invite engineers into customer sessions?
- Who decides whether a customer request changes scope?
- Who signs acceptance for workflow behavior?
- Who owns post-release adoption metrics?
- Who communicates tradeoffs back to the customer?
- Who documents architecture decisions after customer sessions?
- Who has authority to reject a feature request that adds unnecessary complexity?
This checklist prevents informal access paths from driving scope. It also protects the customer from receiving different answers from product, delivery, and engineering. The customer should see one operating model, not three competing channels. For founders and product owners, the practical point is direct. Customer contact needs named owners and controlled decision rights. A studio that cannot describe this model will struggle when customer feedback conflicts with scope, timeline, or architecture.
A mature studio can name the customer owner, engineering owner, product owner, and commercial owner. It can also explain which person decides scope change, which person records the architecture decision, and which person owns acceptance. That clarity keeps the customer conversation useful. The customer owner should control invitations. The engineering owner should control technical questions. The commercial owner should control scope changes and budget decisions.
Those roles reduce confusion during difficult conversations. Customers can describe operational pain without receiving an implied commitment. Engineers can ask direct questions without making commercial promises.
Decision rights matter more than attendance
Attendance alone does not improve software. The team must know which decisions the conversation can change. Otherwise, the session becomes a courtesy call. Before the session, define the decision category. Examples include data model, workflow state, permission boundary, integration boundary, reporting definition, or release acceptance. Each category has a different owner and a different cost profile.
A data model decision belongs to the architect. A scope decision belongs to the commercial owner and product owner. A release acceptance decision belongs to the customer owner with engineering evidence. This separation reduces meeting noise. Engineers can ask precise questions without negotiating commercial terms. Product owners can manage scope without filtering the technical facts that shape the architecture.
Decision rights should appear in the project record. A customer session that changes the workflow state model should produce an architecture decision record. A session that changes scope should produce a change order or a revised release plan. The two records serve different purposes, where technical records protect architecture and commercial records protect scope, cost, and timeline.
One metric keeps contact from becoming feature intake
Engineer-to-customer sessions should never become unfiltered feature intake. Teams need one governing metric that turns customer exposure into better decisions.
The metric must be specific enough to resolve tradeoffs. Examples include:
- Reduce time-to-value from 14 days to 3 days for new customers.
- Increase expansion ARR by 12% in the enterprise segment.
- Reduce invoice reconciliation defects by 40% within 90 days.
- Cut average support handling time from 18 minutes to 9 minutes for a named workflow.
A single metric prevents local decision-making. Support wants fewer tickets, sales wants more configuration, product wants roadmap breadth, and engineering wants cleaner architecture. Those goals can conflict during one decision. A governing metric tells the team which tradeoff serves the business result. It also reduces debate during scope review.
For example, a team targeting faster time-to-value should prefer guided onboarding, default templates, and fewer required setup decisions. A team targeting fewer invoice defects should prefer validation, audit trails, and reconciliation reports. Those choices create different systems. Direct customer context is useful when tied to a measurable business result. Without that metric, every customer session becomes a source of new requests. With that metric, the team can separate useful context from scope expansion.
The metric also gives engineers permission to remove features. If a proposed configuration option does not reduce reconciliation defects, it should wait. If a new dashboard does not cut handling time, it should not enter the build plan. This discipline matters in fixed-scope work. External teams often face pressure to absorb small changes after customer calls. A governing metric gives both sides a fair test for whether a request belongs in the release.
The metric must appear in the architecture decision record. A decision that cannot connect to the metric needs a stronger reason, such as compliance, security, or data integrity. Otherwise, the work belongs in a later product discussion. Metric selection should happen before discovery ends. The metric should have a baseline, a target, an owner, and a measurement source. If the team cannot measure it, the metric will not govern tradeoffs.
A weak metric creates weak decisions. “Improve onboarding” does not guide architecture. “Reduce first successful invoice upload from 9 days to 2 days” tells engineers which workflow deserves attention. The best metric also identifies the user population. Enterprise onboarding, self-serve onboarding, and partner onboarding require different product paths. A metric without a named user group leaves teams arguing about priorities.
Four signals senior studios should capture before build
A senior engineering studio should not rely on generic discovery notes. It should extract four architecture signals before implementation begins. These signals are sequence, authority, exception frequency, and data meaning. This framework keeps customer contact disciplined. It also gives non-technical founders a way to judge whether an engineering partner understands production work. If the partner cannot explain these four signals, it has not heard enough.
| Signal | Customer evidence | Architecture decision |
|---|---|---|
| Sequence | The ordered steps users follow to complete work | Workflow states, UI flow, job timing, latency targets |
| Authority | Who approves, reverses, escalates, and overrides | Roles, policies, audit trails, permission boundaries |
| Exception frequency | How often the workflow leaves the expected path | Admin tools, state machines, reports, observability |
| Data meaning | What each business term means in operation | Schema names, API resources, events, integration contracts |
Sequence prevents teams from designing screens in the wrong order. Authority prevents teams from treating policy as text on a page. Exception frequency prevents teams from burying common work in admin tools. Data meaning prevents the most expensive mistake: vague fields that spread across the system. Terms like status, owner, contract, active, complete, and approved require exact definitions. Each term should have one owner, one source, and one change path.
Use the framework during backlog review. Mark each high-risk item against the four signals. If the team lacks one signal, schedule a customer session before build. The framework also works during project rescue. When a product already suffers from rework, the architect should interview customers against the same four signals. The goal is to find the workflow model that the code failed to express.
A strong partner can show the evidence behind each signal. It can point to a customer transcript, workflow diagram, production artifact, or acceptance scenario. It can also show how that evidence changed the technical plan. A weak partner produces a feature list and calls it discovery. That list can support estimation, yet it cannot protect architecture. Estimation without architecture evidence creates false precision.
The four signals also help founders ask better questions. Ask the studio to explain the state model. Ask who owns each data field. Ask how common exceptions enter the normal workflow.
These questions reveal whether the team understands production use. They also expose architecture gaps while they remain inexpensive to correct.
AI and low-code increase the need for senior judgment
AI app builders, no-code tools, and low-code platforms have changed how quickly teams create software surfaces. They have not reduced the need for correct architecture. Faster generation makes early architecture judgment more important. These tools reduce delivery time for forms, approvals, and internal workflows. They also make it easier to create parallel data models, duplicated business rules, and workflow fragments without senior technical review. A team can create five intake forms in a week.
Six months later, each form can represent a different definition of customer, contract, status, or approval. That inconsistency then appears in reports, integrations, customer exports, and support procedures. The delivery speed becomes a governance problem. Engineer-to-customer contact becomes more important in that environment. If a non-technical team builds from summarized requests, the first version appears quickly. The long-term cost appears when the workflow needs permissions, auditability, integrations, reporting, and error recovery.
A loan approval flow illustrates the risk. A low-code form can collect borrower data and route approval tasks. The production system still needs identity controls, document retention, exception handling, regulator-visible audit trails, and integration with the loan system of record. AI support analysis has the same limit. A system can process thousands of interactions and group repeated language patterns. Volume identifies where customers get stuck.
Senior engineering contact explains why those patterns exist. It also identifies which abstraction removes the repeated problem. A support cluster can show that users ask about “status”. Customer observation shows whether status means legal approval, finance approval, inventory readiness, or shipment timing. Those four meanings require different owners, events, and reports. A language summary alone cannot choose the right boundary.
AI tools summarize language, but engineers must translate operating reality into durable software boundaries. That work requires direct contact with the workflow, especially when automation accelerates implementation. The more quickly a team can generate screens, the more rigor it needs before it names the data. Speed increases the cost of weak architecture because poor choices spread faster. Senior engineers should enter the process before generated software turns into production dependency.
This applies to internal tools as much as customer-facing products. A generated approval app can become the system of record within weeks. Once teams trust it for daily work, correction requires migration and retraining. AI also raises the cost of poor labels. In an ML system, labels reflect human decisions, incentives, and exceptions. Engineers need to observe the decision workflow before they design feedback loops.
A recommendation engine for sales actions provides a clear example. If account managers mark tasks complete to clear a queue, completion data will not mean customer progress. The model will learn the wrong signal. Direct customer and operator contact exposes that behavior early. The ML engineer can adjust the label, capture the downstream outcome, or change the feedback prompt. Those choices shape model quality before training data accumulates.
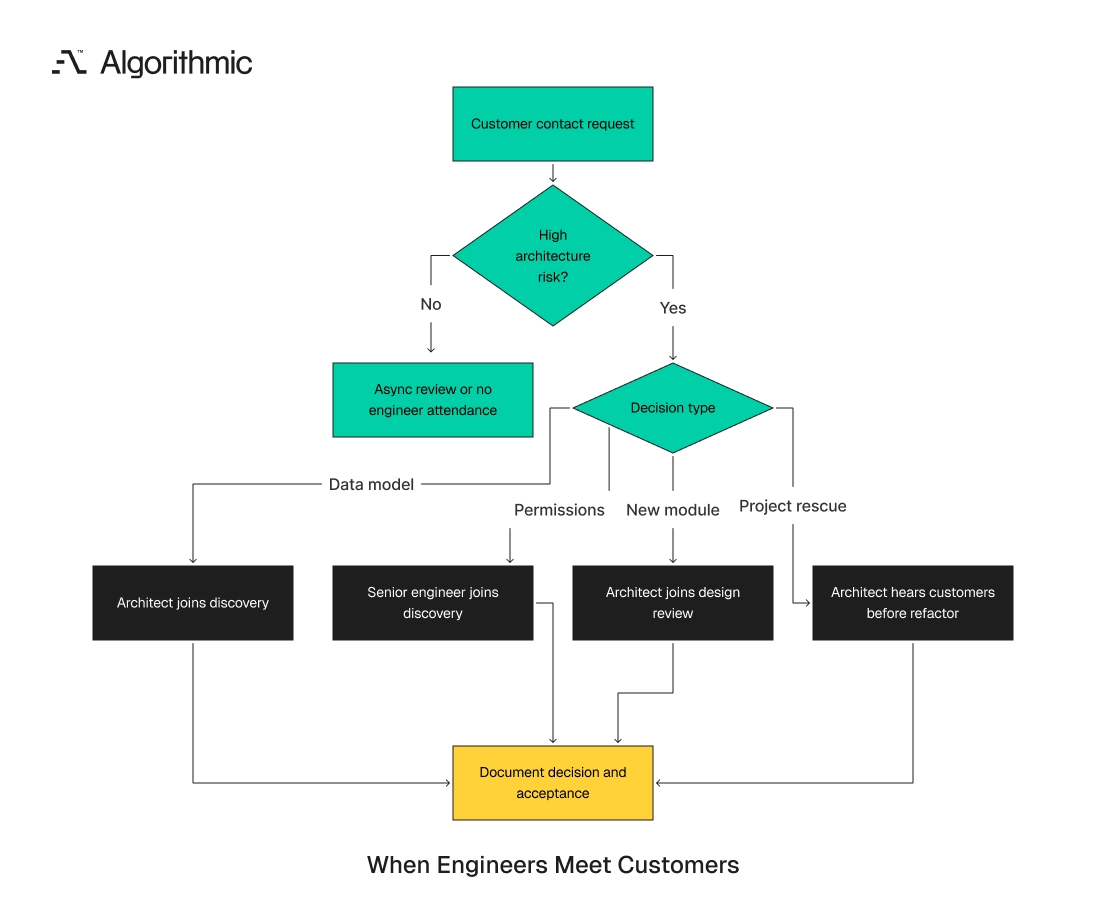
A decision matrix for engineer-to-customer contact
Engineering leaders do not need every engineer in every customer meeting. They need a clear threshold for direct contact. The threshold should be based on architecture risk, not meeting preference.
Use this matrix when planning a product build, software rescue, or enterprise workflow implementation:
| Situation | Engineer contact level | Reason |
|---|---|---|
| Cosmetic UI change with clear acceptance criteria | None or async review | Architecture risk is low |
| Workflow change affecting 1 role and 1 data object | 30-minute customer review | Sequence and terminology need confirmation |
| Feature affecting permissions, billing, compliance, or reporting | Senior engineer in discovery and acceptance | Rework cost is high |
| New product module or full product build from scratch | Architect in customer discovery, design review, and post-release review | Domain model decisions are being formed |
| Software project rescue or inherited codebase correction | Architect listens to customers before refactor planning | Rework must target workflow failures instead of code symptoms |
| ML system in production or recommendation engine development | ML engineer observes decision workflow and feedback loop | Model accuracy depends on labels, incentives, and failure cost |
 Click to expand
Click to expand This matrix is intentionally narrow. It protects engineering focus while preserving access to context that shapes architecture. It also gives product owners a practical rule for when direct customer contact is required. For non-technical founders, the matrix creates a concrete way to evaluate a custom software development company. Ask how engineers will hear customer context. Ask who will attend, how decisions will be documented, and how scope changes will be controlled.
The answers reveal the maturity of the delivery model. A senior studio can name the moments when engineers meet customers. It can also explain how those conversations change architecture decisions. A weaker delivery model keeps engineers behind tickets until rework becomes unavoidable. That model can produce output for several months. It then creates cost when the software meets production use.
The matrix should sit next to the backlog. During planning, each item receives a contact level before estimates are finalized. Items with high architecture risk should not enter implementation until the customer session has occurred. This practice protects both sides of the engagement. The customer receives fewer surprises during acceptance. The engineering team avoids building features that later collapse under real workflow demands.
The matrix also clarifies staffing. A senior architect should attend high-risk sessions. A junior engineer should not carry responsibility for extracting domain rules from an enterprise customer. The contact level can change as evidence improves. A workflow item can move from high-risk to normal delivery once the state model, authority rules, and acceptance scenario are clear. The record should show why the risk changed.
Engineering leaders should review the matrix during estimation. An estimate without required customer contact is incomplete. Architecture risk affects cost, schedule, and acceptance criteria.
What a senior engineering studio should document after customer contact
Direct conversation has value only if it changes the build plan. The team should produce artifacts that connect customer reality to technical decisions.
A strong engineering partner documents four items after each material customer session:
- Observed workflow. The actual sequence of work, including roles, handoffs, approval points, and exception paths.
- Constraint register. Compliance rules, latency requirements, data ownership, approval limits, operating deadlines, and integration dependencies.
- Architecture decision record. The selected design, rejected alternatives, tradeoff analysis, and reason for the decision.
- Acceptance scenario. A concrete scenario the customer can use to validate the release against real work.
These artifacts prevent memory loss between discovery and delivery. They also give product owners a way to challenge implementation choices without reopening every decision. The record becomes part of the build. This discipline matters from MVP development through production. Early-stage teams often treat customer calls as product input and architecture as an internal engineering matter. Production-ready software requires those records to meet.
A founder building a scheduling product needs more than customer preference notes. The engineering team must understand appointment states, cancellation rules, payment timing, provider availability, notification windows, and data ownership. Those items belong in the architecture record. A senior software development team should be comfortable with that exposure. Engineers who can defend an API boundary, database schema, or workflow engine in customer terms usually build smaller systems. They also create systems that change with less rework.
Documentation also controls scope, because when a customer requests a change, the team compares it with the observed workflow and governing metric. That comparison separates necessary workflow correction from optional product expansion. A useful architecture decision record is short. It should fit on one page and state the decision, the customer evidence, the rejected options, the tradeoff, and the acceptance scenario. Long records fail because no one reads them during delivery.
The acceptance scenario matters most. It turns the customer conversation into a testable release condition. “Finance can apply 200 contract term changes on Thursday without losing existing approvals” is stronger than “bulk edit works”. The record should also identify open questions. Some questions require another customer session. Others require technical proof through a spike, load test, or integration check.
A good record avoids meeting transcripts. It captures the decision, evidence, and consequence. Delivery teams need concise records they can use during design review and QA. For fixed-price work, the record protects the commercial relationship. It shows why a requested change belongs inside scope or outside it. That evidence reduces subjective debate during acceptance.
What this looks like in a 12-week build
A practical 12-week engagement needs direct customer contact at four fixed points. The structure is light enough for delivery and strong enough for architecture. It gives the team a repeatable operating rhythm. In week 1, the architect joins discovery for high-risk workflows. The goal is to capture sequence, authority, exception frequency, and data meaning. The team should leave with a draft domain model and a list of unresolved decisions.
In week 2, the team validates the architecture with customer scenarios. The customer walks through two normal cases and two exception cases. The architect records which model changes before implementation starts. In weeks 4 through 8, engineers build against the recorded decisions. Customer questions still go through the named product owner. Direct engineer contact occurs only when a new architecture-affecting constraint appears.
In week 9 or 10, the engineer observes release acceptance. The customer uses real scenarios, current data samples, and known exception paths. The team records defects against workflow behavior, not demo impressions. Within 30 days after launch, the architect reviews usage data and support tickets with the customer owner. The team compares production behavior against the governing metric. Any backlog changes must reference that evidence.
This cadence prevents uncontrolled meeting load. It also prevents architecture from being set by secondhand summaries. The team gets enough customer reality to build with confidence and enough structure to maintain delivery pace. The same cadence works for a smaller MVP if the team compresses the timing. Week 1 still needs direct contact for high-risk workflows. The acceptance session still needs real customer scenarios, even when the release is narrow.
A larger enterprise program can repeat the cadence by module. Payments, reporting, onboarding, and compliance each need separate architecture validation. Combining them into one discovery phase creates false agreement. The key is fixed decision points. Customer contact should happen before architecture locks, before implementation starts, before release acceptance, and after production usage begins. Those points match the moments when evidence changes cost.
How to apply this in the next engagement
For the next external build, add one operating rule before work starts. Every ambiguous workflow, high-value feature, and architecture-affecting request gets one direct customer session with the responsible senior engineer. This discipline is the heart of feasibility and discovery work, where the goal is to size the real problem before code hardens. Pair that rule with named customer ownership, one governing metric, and written architecture decision records. Review the first 10 backlog items against the decision matrix above. Schedule customer sessions before implementation begins.
The operating rule should appear in the statement of work. It should name who can request the session, who attends, who documents the decision, and who approves any scope change. That clarity prevents customer access from becoming uncontrolled intake. Start with the highest-risk backlog items. Look for permissions, billing, compliance, reporting, integrations, and state transitions. Those categories create the highest rework cost when the customer workflow is misunderstood.
Run each customer session with a specific agenda. Ask the customer to walk through the work in sequence. Capture roles, handoffs, exceptions, deadlines, approvals, and data definitions. The engineer should leave the session with one decision to make or verify. That decision can be an API boundary, a state model, a permission rule, or a data ownership rule. If the session produces only general preference notes, the structure was too loose.
After the session, update the architecture decision record within 24 hours. Link the decision to the governing metric and acceptance scenario. Share the record with product, delivery, and the customer owner. This practice changes the software before expensive code exists. It reduces rework, limits unnecessary features, and gives engineers the context required for production decisions. Put the responsible engineer in the customer conversation before architecture hardens.
Algorithmic puts senior engineers in discovery and feasibility work before architecture hardens, so the build matches the real workflow. If your backlog is filling with broad feature requests, bring us into your next customer session.


