
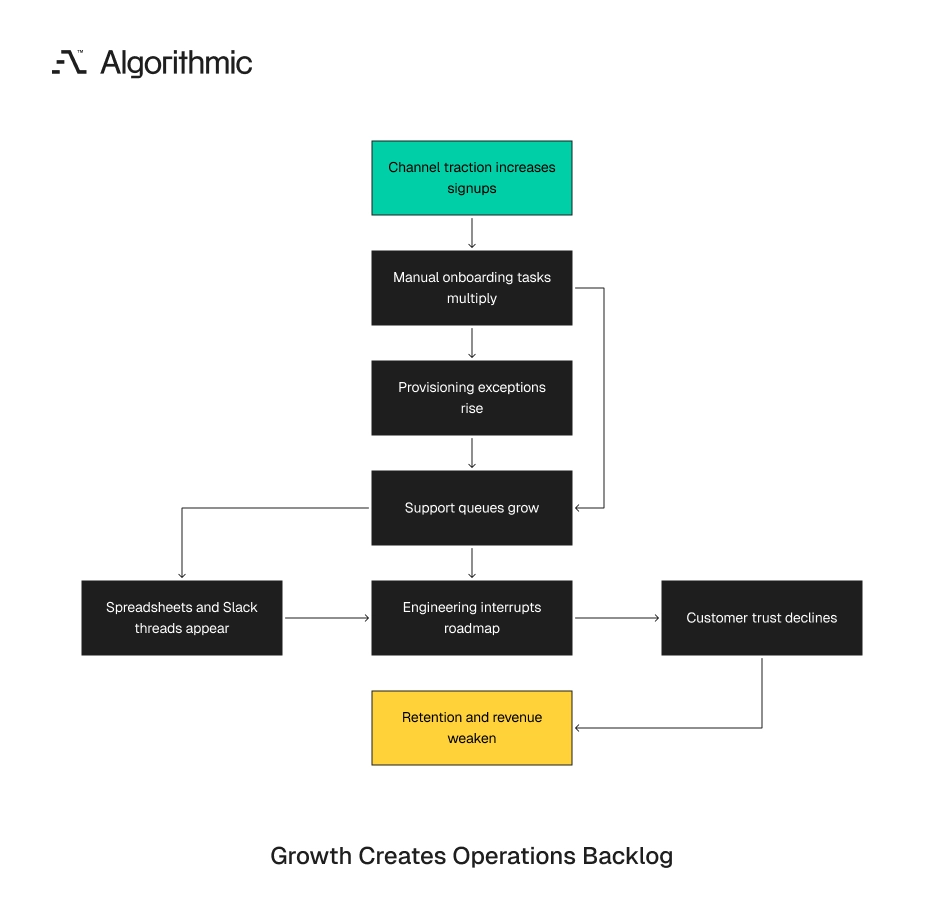
A product that moves from 100 to 500 weekly signups multiplies every manual task by five when the operating model stays unchanged. Onboarding reviews, provisioning exceptions, support handoffs, billing checks, and escalation paths rise with demand. Growth exposes the work that early traction allowed the team to handle by hand.
This failure pattern appears often in growth-stage products after early channel traction. Paid search starts converting at a lower acquisition cost. Outbound produces qualified meetings. Partnerships send traffic that sales and product teams did not forecast. Creator distribution, marketplace placement, and product-led referrals can also send demand into workflows built for a smaller company. The channel creates volume. The product operating model determines whether that volume becomes revenue, backlog, churn, or engineering interruption.
The team celebrates the leading indicator. Then support queues double, activation falls, customer success creates spreadsheets, and engineering spends two sprints writing emergency scripts. The acquisition channel performed; the product operating system failed under volume. The sequencing error is specific. Demand scales before onboarding, provisioning, support, and escalation can absorb the new work. A channel that looks efficient in a marketing dashboard can damage retention, roadmap velocity, and customer trust within one month.
For founders moving from MVP traction to scaled product operations, this is both a technical decision and an operating decision. A successful channel can harm the product when account setup, entitlement assignment, support routing, and escalation still depend on human judgment. Growth creates pressure; manual operations convert that pressure into queues. The pattern usually starts with a reasonable decision. A founder approves a manual review because the first ten customers need attention. A backend engineer edits a customer record because the admin console does not exist. A customer success manager reconciles Stripe and HubSpot because the billing integration lacks the required fields.
Those decisions are defensible during discovery. They become liabilities when a channel sends hundreds of accounts through the same path. The product then carries hidden labor in every signup, trial, invite, import, and billing event. The result is a product that acquires faster than it can serve. Customers experience the gap as delay, repeated questions, inconsistent account state, and unclear ownership. Internally, the gap appears as Slack threads, private scripts, spreadsheet trackers, and calendar meetings about queues.
Growth exposes the manual steps hidden in early traction
Early traction often masks operational fragility because small numbers make manual work appear acceptable. A founder can personally onboard the first 20 customers. A product manager can review every failed import and still ship roadmap work that week.
 Click to expand
Click to expand A backend engineer can adjust customer permissions directly in PostgreSQL. A customer success lead can monitor Slack and HubSpot, Intercom, and Stripe each morning. At 20 customers, these practices feel controlled because one person can remember the exceptions. At 200 customers, the same practices create queues. At 2,000 customers, they become product defects. Customers experience the defect as delay, confusion, duplicate requests, and inconsistent account state. A common example is a SaaS company that sells team workspaces. In the first month, the founder manually creates each workspace, assigns the plan, invites the admin, and checks Stripe. That process works while the company signs five customers per week. The same process fails when a partner sends 400 signups in a week. Some users receive the wrong plan. Others wait for an invite. Several contact support because the product says their account exists while Stripe shows no subscription.
A second example appears in data products that require customer imports. During early pilots, a product manager reviews CSV files, fixes column headers, and asks engineering to rerun failed jobs. The company reads those interventions as customer learning. The same import flow fails under channel volume. A template mismatch that affected one customer per week now affects 70 accounts in two days. Support sees duplicate tickets, customer success asks for status updates, and engineering stops feature work to restart jobs.
A useful test examines every event after acquisition:
- Account creation
- Identity verification or approval
- Workspace provisioning
- Data import or integration setup
- Billing plan assignment
- User invitation
- Activation tracking
- Support intake
- Escalation routing
- Refund, cancellation, or account change
If three or more steps require a person to inspect, decide, or modify data, the product is unprepared for scaled acquisition. The team has built demand generation on top of manual operations. The first channel ramp will reveal that design choice. This pattern appears in commerce, SaaS, and marketplaces. Pipe17’s analysis of omnichannel operational excellence describes how brands lose control as channel count rises. The same failure mode appears inside software products when one channel sends volume into incomplete workflows.
The damage comes from uninstrumented handoffs, unclear ownership, and tools that require staff to bridge product gaps. The team sees the symptoms in Slack threads and support queues. The customer sees the symptoms as a product that cannot complete basic work consistently. Manual work also distorts management judgment. A founder sees revenue growth and assumes the process works. A support manager sees rising queue age and knows the process is failing. A marketing leader sees cost per signup falling and misses the cost per activated account.
These reports disagree because each team measures a different layer. Growth measures acquisition. Product measures activation. Support measures tickets. Finance measures revenue and refunds. The operating system connects those measures, or the company manages growth through partial truth.
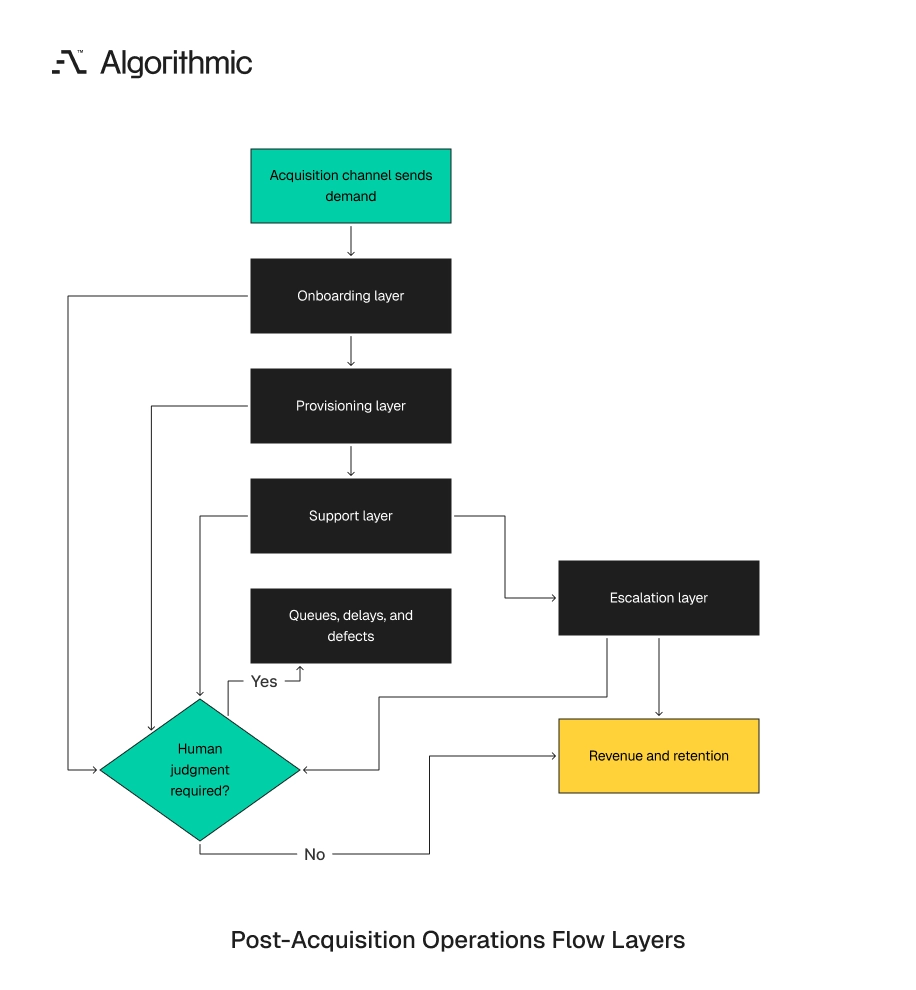
The post-acquisition system has four failure points
A growth channel sends work into the product. That work enters four operating layers: onboarding, provisioning, support, and escalation. Each layer needs explicit ownership, software support, and metrics before demand increases. These layers are separate. Onboarding measures how users reach first value. Provisioning creates the account state required for use. Support routes customer issues. Escalation resolves exceptions that front-line teams cannot handle safely.
Leadership should review the four layers before approving a channel ramp. Marketing performance is one input. The operating system behind the product determines whether demand becomes revenue or backlog. The review must include error paths. Standard success paths rarely break the company. Exceptions break the company because they require judgment, system access, and cross-functional ownership.
A product can appear ready when the happy path works in a demo. The same product can fail when 12% of accounts hit duplicate workspaces, expired tokens, billing mismatches, or failed imports. Readiness requires evidence from production behavior, not only a successful walkthrough.
 Click to expand
Click to expand Onboarding fails when activation depends on human follow-up
Manual onboarding often begins as a strength. A founder or customer success lead speaks with every customer, learns objections, and shapes the product. Those conversations produce the language, workflows, and priority list for the early product. That model has a limited shelf life. When activation depends on a person sending setup instructions, activation becomes a staffing problem. Weekend signups wait until Monday, enterprise trials wait for sales engineering, and self-serve users leave after one failed import.
At scale, onboarding needs instrumented paths. Teams need event tracking for first login, first workspace created, first integration connected, first meaningful action, and first invite sent. These events should be recorded in a product analytics system and tied to account, channel, and plan. Those events should feed operating dashboards in Metabase, Looker, or Mode. The dashboard should show cohort views by acquisition channel, plan type, signup date, and first-value milestone. A product team should see the health of a new channel within one business day.
A product that cannot show activation by channel within 24 hours cannot judge the quality of new demand. It cannot separate a productive channel from a channel that creates avoidable work. It also cannot explain whether a conversion drop came from traffic quality, product friction, or operations delay. Good onboarding also needs failure reasons. A failed import, missing permission, expired token, duplicate workspace, or unclear setup step should create a measurable event. Each event needs a timestamp, account identifier, channel source, and recovery path.
Without those events, the team reads support tickets and guesses. Guessing becomes expensive once paid media, partner commitments, or sales targets depend on the channel. A $25,000 monthly channel test should not run on anecdotal support feedback. Onboarding also needs decision rules. A standard self-serve account should move through product-led steps without staff involvement. An enterprise account with custom integration needs, security review, or contractual setup can move into a managed path.
Those paths should be explicit. A hidden rule in a customer success manager’s memory does not scale. A field in Salesforce, HubSpot, or the product database can route the account to the right onboarding path. Activation definitions must be narrow enough to manage. “User completed onboarding” is too broad for operations. “Workspace created, one integration connected, and first report viewed within 24 hours” gives the team a measurable target.
The definition should match the product’s value moment. For a scheduling product, first value can be the first external booking. For a data integration product, it can be the first successful sync. For a marketplace seller, it can be the first published listing.
Provisioning fails when internal tools lag behind the product
Provisioning breaks when a product requires manual database edits, admin console work, or developer intervention to create a customer environment. The earliest warning sign is a Slack message asking an engineer to “set up the account”. The second warning sign is a SQL script that only one backend engineer knows how to run.
Other signs include manual feature-flag changes in LaunchDarkly, private spreadsheets with entitlement rules, and support agents copying values between Stripe, Salesforce, and the product database. Each copy step increases the chance of incorrect plan state, missing permissions, or duplicate records. These errors appear small until channel volume turns them into daily incidents.
Most provisioning flows need a narrow set of engineered primitives. Those primitives include tenant creation, role assignment, plan mapping, default configuration, integration token handling, and audit logs. They also need idempotent behavior when a user retries setup.
Idempotency matters because users retry failed steps. A user clicks “Create workspace” twice. A webhook arrives twice. A Stripe event is replayed after a timeout. Without idempotency, retries create duplicate tenants, double invites, or inconsistent plan states. Support then spends time reconciling records across systems. Engineering becomes the only team trusted to repair the account.
The first version does not require a large internal platform. A guarded admin workflow can remove most manual provisioning work within 2 to 4 weeks. The workflow should expose approved actions and prevent direct production edits. That workflow needs permission checks, field validation, idempotent retries, and an audit trail. These controls protect the product from accidental privilege changes and duplicate customer records. They also give operations a safe way to resolve known account issues without waiting for engineering.
Provisioning work should start with the standard account path. Most products have a small number of account shapes that represent most demand. The company should encode those account shapes before building a broad administration layer. For example, a B2B SaaS product often has free trial, self-serve team, sales-assisted business, and enterprise account types. Each type should have defined roles, limits, billing states, default settings, and feature entitlements. Those definitions should live in code or controlled configuration, not in a private spreadsheet.
Billing and entitlement state deserve special attention. Stripe, Chargebee, Salesforce, and the product database often disagree after manual changes. A growth ramp turns those disagreements into support incidents and revenue leakage. A strong provisioning flow treats billing status as a controlled input. It also records which system owns the customer’s plan, payment state, trial end date, and renewal terms. Support should see that source of truth without asking engineering.
Support fails when intake has no routing logic
Support backlog grows when every issue enters the same queue. A password reset, failed data sync, billing dispute, and production defect have different owners and service levels. Treating them as one queue wastes senior time and delays urgent work. Routing rules are a high-return engineering investment. A basic classifier can use plan tier, error code, customer age, account value, feature area, and channel source. The first implementation can live in Zendesk, Intercom, HubSpot, Linear, or a small webhook processor.
The goal is to remove human sorting from the critical path. A person should not read every ticket to decide whether it belongs to support, billing, engineering, or customer success. That triage step fails as soon as volume doubles. A useful first service level is owner assignment within 15 minutes during business hours. The next step is automatic severity tagging for production defects, payment failures, and blocked onboarding. Those categories should page the right owner or open the right queue without manual review.
Routing should also carry context. A support ticket should show the customer’s plan, signup channel, last failed event, last successful event, and account owner. An agent should not open five systems to understand whether the customer failed setup or found a defect. A $120,000 annual contract account with a failed data pipeline requires a different path from a free user with a documentation question. Both deserve a response. They should not compete in the same undifferentiated queue.
Support routing also protects engineering time. Without classification, support forwards too many tickets to engineering “for a quick look”. Those requests fragment senior engineers’ calendars and create undocumented fixes. A better path attaches telemetry to the ticket. The ticket should include error code, request ID, account ID, plan, feature area, and the last five product events. Engineering then receives a defect report, not a vague escalation.
Support categories should stay small at first. Billing, authentication, provisioning, integration failure, product defect, documentation, and cancellation cover many growth-stage products. A taxonomy with 40 categories creates its own administration burden.
Escalation fails when engineering becomes the exception handler
Emergency engineering work begins when operations has no safe way to resolve known issues. Engineers then become the default escalation path for account fixes, data corrections, import restarts, billing adjustments, and missing permissions. This creates two costs at the same time. Product roadmap work slows. Customer issues also wait for engineering capacity. The team pays twice: once through missed product work and once through slower customer recovery.
The fix is controlled delegation. Operations teams need tools that execute approved actions safely. These actions should address known exceptions with narrow, logged workflows. Common actions include restarting an import, re-sending an invite, reassigning a plan, triggering a webhook replay, and marking a duplicate account. Each action should be specific, logged, and reversible where practical. Broad admin power creates new risk and should be avoided.
Every action needs role-based access control, validation, logging, and rollback where feasible. Without those controls, internal tooling creates security and data integrity risk. A support agent should not have a text box that can change arbitrary account fields in production. A mature escalation model separates known exceptions from unknown defects. Known exceptions belong in operational tools and runbooks. Unknown defects belong in engineering triage with product telemetry attached.
The distinction changes engineering behavior. Engineers stop handling repetitive account repairs. They focus on defects that require code changes, architectural decisions, or new instrumentation. Escalation also needs time limits. A blocked onboarding issue for a paid enterprise trial should not sit behind low-severity requests. A failed billing event that prevents activation needs a defined owner and response path.
Runbooks should state the condition, action, owner, and evidence required. For example, “If import job failed with timeout and no schema error, operations can restart once from the admin console”. The runbook should also state when to stop and escalate to engineering. Escalation metrics should be reported by channel. If one partner channel creates five times more engineering escalations per 100 accounts, leadership needs to see that cost. The issue can sit in partner qualification, account setup, product fit, or integration quality.
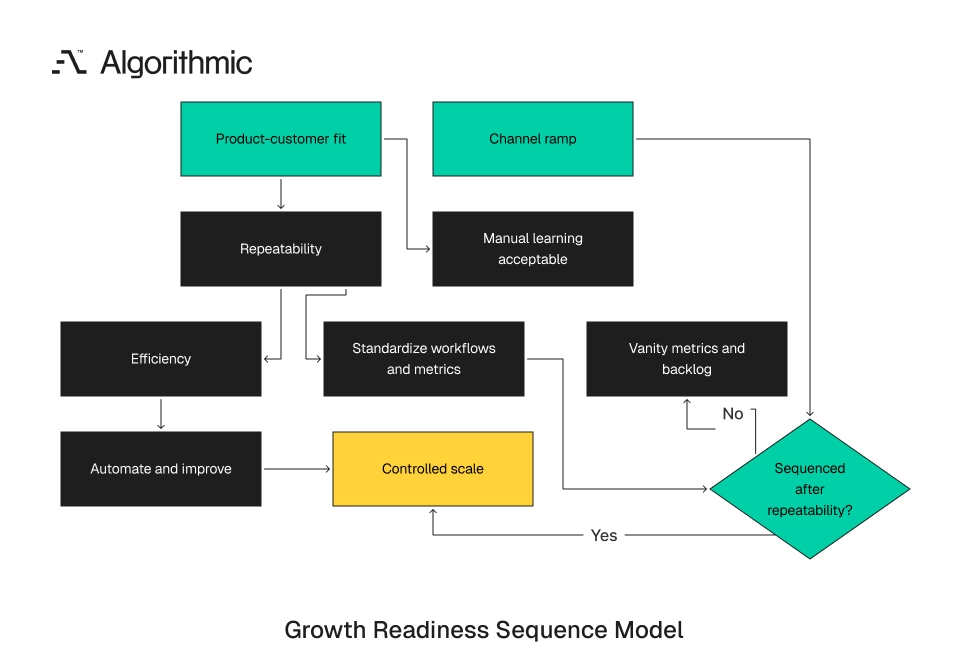
Demand, satisfaction, and efficiency must be sequenced
Early products cannot improve demand, satisfaction, and efficiency at the same time. One axis should move at a time. This sequencing keeps the team from scaling a process it has not defined. The first phase is product-customer fit. Teams learn whether a small set of customers receives enough value to stay, pay, and refer. This phase tolerates manual work because learning matters more than repeatability.
Founder-led calls, manual imports, and direct support reveal the shape of the product. The team learns which setup steps confuse buyers, which integrations carry value, and which account states create risk. Manual work is useful here because it teaches the team what the product must later support. The second phase is repeatability. Teams define the onboarding path, activation metrics, support categories, and escalation rules. The product operating system starts to take shape during this phase.
The team standardizes the steps that led early customers to value. It decides which accounts qualify for self-serve onboarding and which accounts need review. It names failure reasons and creates owners for each queue. The third phase is efficiency. Teams remove recurring manual work through self-serve provisioning, automated routing, operational dashboards, and internal tools. The work shifts from heroics to repeatable execution.
 Click to expand
Click to expand A channel ramp belongs after the second phase starts. Earlier ramps buy volume before the business has the machinery to process volume. That purchase produces vanity metrics, support backlog, and engineering interruption. LeanData’s 2026 B2B State of Martech and Revenue Operations report found that 82% of enterprise B2B leaders agree on one point: clean data and reliable routing must come before scaling AI. The same report found that fewer than 1 in 3 have enforcement mechanisms in place.
The same principle applies to product operations. Routing, data quality, and ownership rules must exist before automation runs at scale. Automation without these rules moves errors faster through the business. Fullcast’s 2026 GTM benchmarks report found that overloaded pipelines cost organizations 57% in win rate. That statistic comes from sales operations. The mechanism maps directly to product-led growth.
When demand exceeds processing capacity, conversion quality falls. Users wait longer, hit more errors, and receive less precise support. The channel still produces signups, while the product loses the accounts after acquisition. Sequencing also protects the product roadmap. Growth teams often ask engineering to support campaigns, landing pages, tracking, and partner integrations at the same time. Those requests compete with the internal systems needed to process the resulting demand.
A disciplined sequence puts operating readiness into the growth plan. The channel plan should include expected signups, activation targets, support load, provisioning load, and escalation limits. It should also state which metric triggers a pause. A pause condition is an operating control, not a lack of ambition. For example, a company can state that the ramp stops if activation drops by 10 percentage points for two consecutive days. It can also stop if support tickets per 100 accounts exceed a defined threshold. These controls turn growth into an engineered process. They also reduce conflict between marketing, product, support, and engineering. Each team knows the target and the stopping rule before the campaign begins.
The channel readiness gate
Before increasing spend or partner volume by 3x to 5x, leadership should run a channel readiness review. This review is a technical gate. Marketing performance is only one input. The gate should test whether the product can absorb demand without exceptional human effort. It should examine the path from signup to first value, including errors and internal handoffs. It should also quantify how much engineering time the channel consumes after acquisition. The following matrix gives founders and growth-stage executives a practical way to assess readiness.
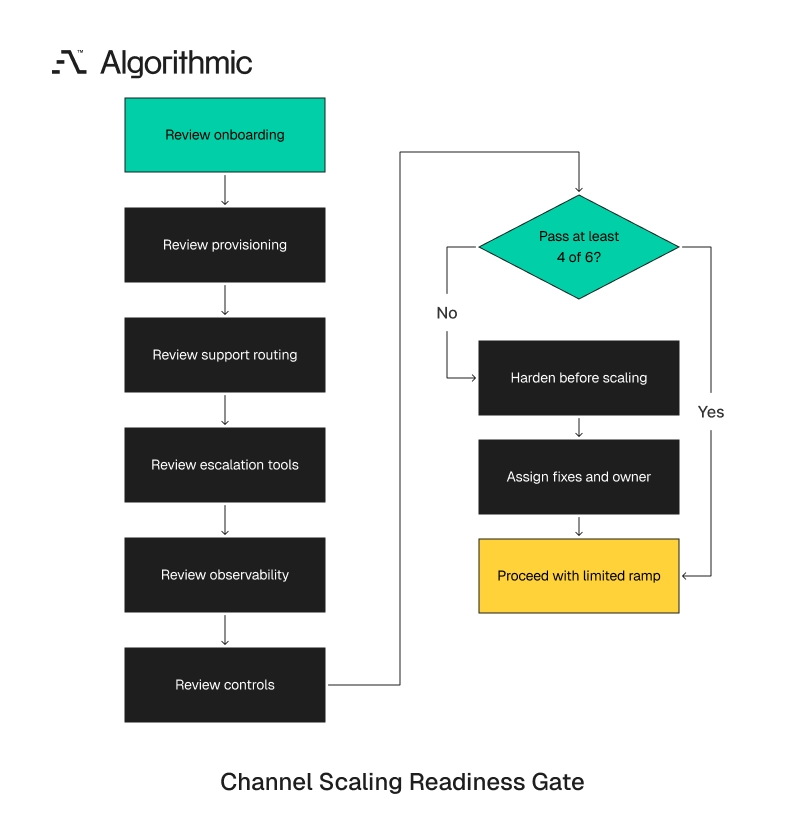 Click to expand
Click to expand | Operating layer | Readiness question | Minimum standard before scaling demand | Failure signal |
|---|---|---|---|
| Onboarding | Can a qualified user activate without staff involvement? | 80% of standard accounts reach first value through self-serve steps | Activation falls as signup volume rises |
| Provisioning | Can the system create accounts, roles, plans, and defaults safely? | Provisioning is idempotent, logged, and exposed through a guarded admin workflow | Engineers modify production data for setup |
| Support | Are issues routed by severity, plan, product area, and customer state? | 90% of tickets receive an owner without manual triage | One shared queue grows daily |
| Escalation | Can operations resolve known exceptions without engineering? | Top 10 recurring issues have approved tools or runbooks | Engineers handle repetitive account fixes |
| Observability | Can leadership see channel health within 24 hours? | Dashboards show signup, activation, failure, ticket, and churn metrics by channel | Growth reports and support reports disagree |
| Controls | Can automation fail safely? | Every automated action has permissions, validation, retries, and audit logs | Staff rely on spreadsheets and private scripts |
A product should pass at least four of these six checks before channel volume increases materially. A product should pass all six before a board-level growth target depends on one acquisition channel. This standard prevents the company from committing to demand it cannot process. The gate also prevents a common hiring error. When operations strain under demand, leaders often approve more support headcount. More headcount can help when the process is sound and the queue requires judgment.
In many growth-stage products, a two-person engineering pod for 30 days produces a higher return. The pod should include one senior backend engineer and one product-minded operations owner. That pod can remove more queue time than three new support hires when it targets the right bottlenecks. The work is specific. Measure the queue, remove the top constraint, and instrument the result. A pod that reduces manual provisioning from 30 minutes to 3 minutes changes unit economics within the same month.
A team should assign one executive owner for the gate. Without a single owner, marketing, product, support, and engineering each treat the failure as someone else’s metric. The result is a channel that every department reports differently. The executive owner should have authority to slow the ramp. That authority matters when paid campaigns, partner commitments, or board expectations create pressure. A paused channel is less expensive than a month of poor activation and avoidable churn.
The gate should sit in the same calendar as the campaign approval. It should not run after budget has been committed and partner dates have been announced. Readiness checks have value when leadership can still change the ramp. A useful gate meeting lasts 60 to 90 minutes. The team reviews the six checks, the current operating metrics, the top five failure reasons, and the expected channel volume. The meeting ends with one of three decisions: proceed, harden before ramp, or pause. The decision should be written. A one-page record prevents later debate about why the company slowed, proceeded, or paused. It also creates accountability for the fixes required before the next attempt.
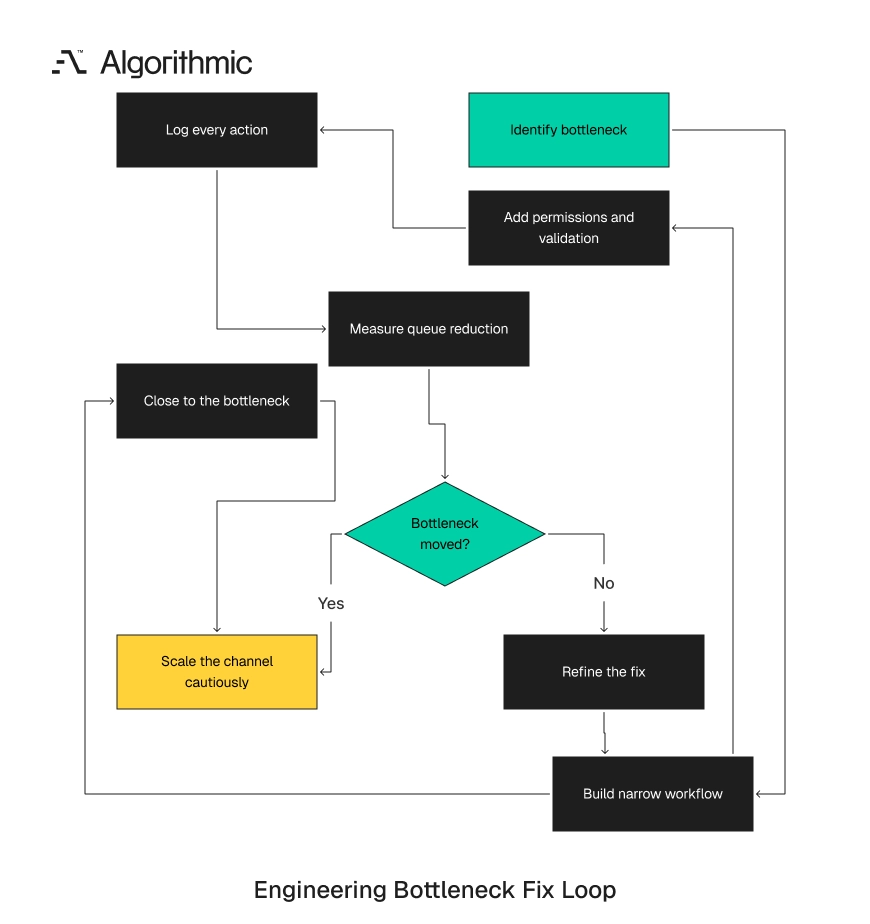
The engineering response should be small, guarded, and close to the bottleneck
The right engineering response is seldom a full internal platform. It is a sequence of small systems that remove the current constraint without creating long-term maintenance burden. The team should build close to the bottleneck. If imports fail, build retry and diagnostics tools. If provisioning blocks activation, build a guarded admin flow. If support triage consumes time, add routing rules and ticket enrichment.
Each fix should reduce a measured queue within the same month. A useful fix changes a number that leadership already tracks. A weak fix creates infrastructure without shortening the customer’s wait time. This work requires disciplined scope. The first version should solve the standard case, expose exceptions, and log every action. The team can extend it after the channel proves it can generate profitable demand.
The engineering team should resist broad abstractions during the first hardening cycle. A clean internal platform can be valuable later. The current need is a controlled workflow that reduces one bottleneck under live demand. The work also needs product management. Internal tools affect customer experience, security, billing, and data quality. A senior operations owner should define the workflow with engineering and test it against real accounts.
 Click to expand
Click to expand Self-serve provisioning
Self-serve provisioning should cover the standard customer path first. That includes account creation, plan selection, workspace setup, default permissions, user invitations, and billing status. The path should work without Slack messages, manual Stripe checks, or database edits. Exceptions should remain visible. If 15% of accounts need manual review for enterprise rules, compliance checks, or custom integrations, route them explicitly. Give each exception a status, owner, reason code, and target response time.
Those accounts should not live in Slack threads. Slack is useful for alerts and discussion, yet it is a poor system of record. It does not provide state, ownership, reporting, or reliable audit history. A good first target is reducing manual provisioning time from 30 minutes per account to under 3 minutes for standard cases. At 300 new accounts per month, that saves 135 staff hours monthly. Those hours return during the exact period when support, billing, and customer success volume also rise.
The first self-serve flow should include retry behavior. Users should recover from a failed token, expired invite, or duplicate workspace without waiting for staff. Recovery paths should be visible in the product, not buried in support macros. The flow should also write audit events. An account creation event, role assignment event, billing plan event, and integration event should share identifiers. Those identifiers allow support and engineering to reconstruct the account timeline within minutes.
The product should expose provisioning status to the user. “Workspace pending” without a reason creates tickets. “Integration token expired; reconnect Google Workspace” gives the user a clear next step. Internal teams need the same status with more detail. Support should see whether provisioning failed because of billing, permissions, identity verification, or an integration timeout. Engineering should receive request IDs and error traces when the failure requires code investigation.
Self-serve provisioning also needs ownership for configuration changes. If sales can change plan limits, product can change defaults, and support can modify roles, the system needs rules. Those rules should specify who can change which field and what audit record gets written.
Routing rules
Routing rules should classify work using data already present in the product. Useful fields include customer tier, acquisition channel, lifecycle stage, last error code, feature area, payment status, and number of failed attempts. These fields identify the right owner and response path. The system should distinguish a new free user with a basic question from an enterprise account with a failed data pipeline. Both deserve a response, and they require different queues. The routing system should make that difference explicit.
This is practical automation. A Python script, webhook processor, or rules engine can often carry the system for months. A more complete workflow service can come later. The early target is reliable ownership. Architectural elegance should not outrank queue reduction. If a 200-line webhook processor cuts triage time by half, it is the right first system.
Routing rules should create an audit trail. Teams need to know why a ticket was assigned to billing, engineering, customer success, or support. The assignment reason should be visible on the ticket. A good routing event includes the rule name, triggering field, assigned owner, severity, and timestamp. This record helps managers tune rules without guessing. It also prevents disputes over whether an escalation followed the approved path.
Routing rules should start with severity and ownership. Severity determines response speed. Ownership determines the queue. These two decisions remove most human sorting from the first response process. The rules should also account for channel commitments. A partner channel with a contractual service level should carry that commitment into the ticket. An account from a high-touch enterprise campaign should not enter the same flow as an anonymous free signup.
The routing layer should be reviewed weekly during a ramp. The review should compare assigned category, final resolution, owner changes, and response time. High reassignment rates show that the rule set needs adjustment.
Operational dashboards
Growth dashboards and operations dashboards must share identifiers. A leadership dashboard should show signups, activation, support tickets, provisioning failures, onboarding completion, and churn risk by channel. Channel economics are incomplete without operating cost. If TikTok campaigns bring 1,000 signups and 300 support tickets, the channel has a service cost. That cost should appear beside acquisition cost. The same reporting should show whether those users reached first value.
This is where data engineering services often create immediate value. A small data platform build can connect product events, CRM records, billing data, and support tickets. The first version should prioritize trusted joins over visual polish. Common warehouse choices include BigQuery, Snowflake, and Postgres. dbt can transform raw events into channel-level metrics and trusted reporting tables. A daily dbt run can produce enough fidelity for most B2B and prosumer products.
The first dashboard does not need 40 charts. It needs five numbers by channel: signup volume, activation rate, provisioning failure rate, support tickets per 100 accounts, and 30-day retention. Those five numbers reveal whether demand is converting or creating operational debt. The dashboard should update daily during a ramp. For high-volume consumer or marketplace products, hourly updates are justified during launch week. The update schedule should match the speed at which leadership needs to intervene.
The dashboard should also show queue age. A support queue with 200 tickets carries different risk when 180 tickets are under one hour old. A queue with 40 tickets older than three days signals a breakdown in ownership or routing. Metric definitions should be written beside the dashboard. “Activation” should have one definition. “Provisioning failure” should have one definition. “Ticket per account” should specify the time window and ticket source.
Data quality checks matter because channel decisions depend on the numbers. If UTM parameters drop during signup, channel attribution breaks. If billing identifiers fail to join to account IDs, revenue and support cost cannot be connected. The dashboard should include a small data quality panel. Missing channel source, missing account ID, duplicate workspace, and unmatched billing record should be counted daily. These checks prevent leadership from managing the ramp with incomplete data.
Guarded automations
Automations that touch customers, billing, permissions, or data must have guardrails. Each automated action should have five controls: permission checks, input validation, idempotency, audit logs, and alerting on failure. These controls should ship with the workflow. For example, a webhook replay tool should prevent duplicate billing events. It should record the operator, log the payload, and report failures to PagerDuty or Slack. It should also show whether the replay changed account state.
Guarded automation reduces risk. Unguarded automation moves risk from humans into software. The failure mode changes from one incorrect manual edit to hundreds of incorrect automated actions. Marketplace operators face this same issue when seller onboarding, catalog updates, order handling, and disputes remain manual. Mirakl’s article on hidden costs of manual marketplace management covers delayed launches and preventable errors. Software products incur equivalent costs through churn, support backlog, and engineering interruptions.
The costs appear after acquisition, which makes them easy to miss in channel reporting. A channel can show a low cost per signup while carrying a high cost per activated account. Leadership needs both numbers before increasing volume. Guarded automation should also support dry runs for risky actions. A billing change, entitlement update, or data migration should show expected changes before execution. Operators need confidence that the action affects the intended account and fields.
Rollback requirements depend on the workflow. Some actions, such as resending an invite, need no rollback. Others, such as plan reassignment or permission changes, need a reversal path or an approval step. Access should follow the principle of least privilege. Support can restart approved jobs and resend invites. Billing can adjust billing state. Engineering can access lower-level repair tools under audit.
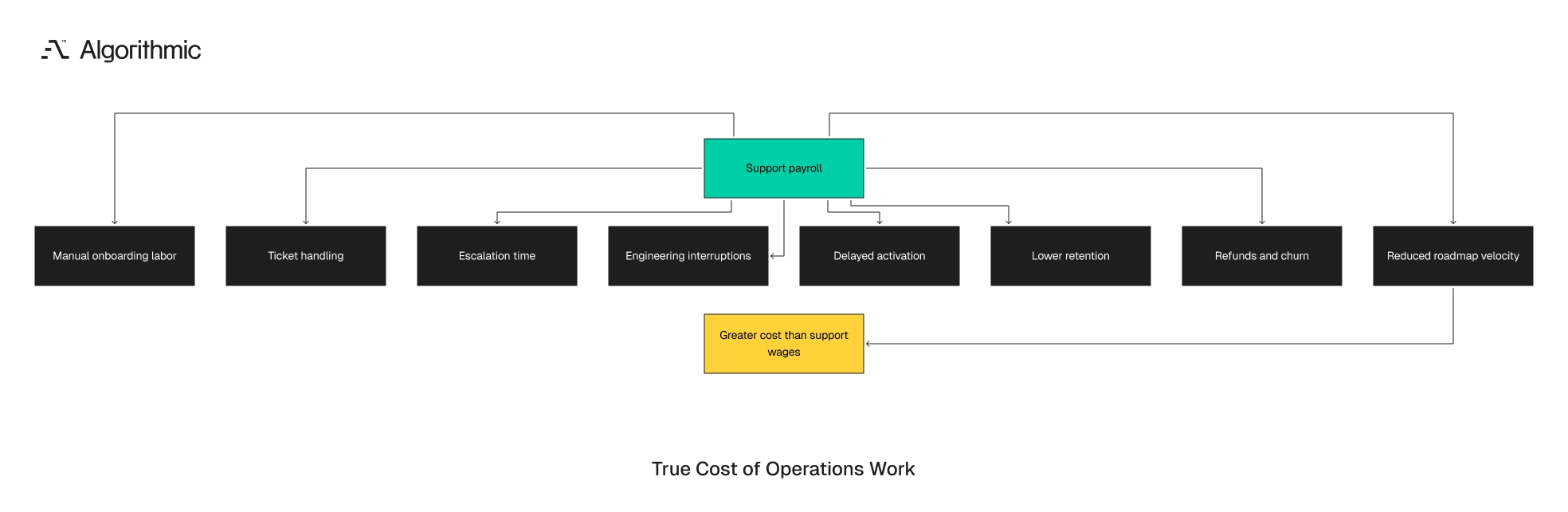
The financial cost is larger than support payroll
Manual operations create direct labor cost, revenue loss, and engineering drag. The visible cost is support time. The larger cost is often delayed activation, lower retention, and interrupted product work.
 Click to expand
Click to expand Consider a B2B SaaS company with 1,000 monthly signups from a new partner channel. If 25% require manual onboarding at 20 minutes each, the team spends 83 hours per month on onboarding alone. If 10% generate support tickets at 12 minutes each, another 20 hours enter the queue. These numbers exclude escalation time, failed activation, refunds, and churn. They also exclude the management time spent reconciling reports across growth, support, and finance. Manual work creates administrative work around the work itself.
The cost becomes material when engineers are pulled into repetitive support work. A senior engineer costing $180,000 to $240,000 fully loaded should not spend 6 hours per week fixing account states. Over a quarter, that diversion equals about 78 engineering hours removed from product work. An internal tool can handle those account states with safer controls. The tool does not need to be broad. It needs to handle the top recurring actions with logs, validation, and permission checks.
There is also a customer trust cost. A product that acquires users faster than it serves them trains customers to expect delays. That expectation weakens activation, expansion, and referral behavior. In SaaS, this damages activation and retention. In marketplaces, it damages liquidity. In commerce, it damages fulfillment promises and refund rates.
The post-sale bottleneck in enterprise SaaS has been documented in discussions of SaaS execution after closed-won. The same pattern applies to product-led and founder-led growth. Acquiring the user starts the operating burden. A finance team should treat these costs as channel costs. Acquisition cost alone understates the true cost of growth when support and engineering absorb preventable work. A channel that appears efficient in marketing reports can become unprofitable after labor, churn, refunds, and engineering interruption are included.
This is why channel readiness belongs in operating reviews, not only growth meetings. The CFO should see post-acquisition cost by channel. The CTO should see engineering escalations by channel. The CPO should see activation and retention by channel. The COO should see queue age and owner assignment by channel. The CEO should see whether channel growth produces profitable, serviceable customers.
The finance model should include staff time by workflow. Manual onboarding, ticket handling, escalation, billing correction, and refund processing each have a cost. Those costs can be estimated through time sampling before a full activity-based costing model exists. A practical model starts with five inputs: accounts by channel, manual minutes per account, ticket rate, escalation rate, and gross margin by activated account. This model shows how operational drag changes the channel’s contribution. It also gives leadership a basis for engineering investment.
For example, reducing manual setup by 27 minutes across 300 monthly accounts saves 135 hours. At $55 per loaded support hour, that equals $7,425 in monthly labor capacity. The larger gain comes when faster activation improves retention and reduces engineering interruption. Engineering drag is often the most undercounted cost. Six hours per week from a senior engineer can look manageable on a calendar. Over 13 weeks, those hours equal nearly two full engineering weeks removed from product development.
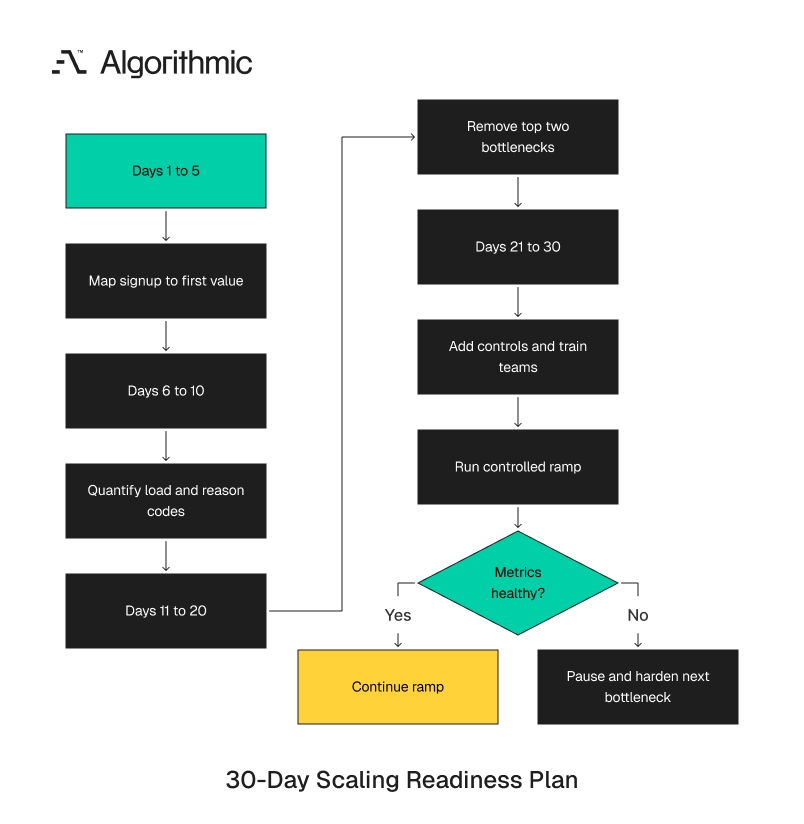
A 30-day operating hardening plan before scaling a channel
A growth-stage product does not need a six-month transformation before increasing acquisition. It needs a focused hardening cycle aimed at the highest-volume manual steps. The work should fit inside one month. Longer programs often lose focus and become platform projects before the urgent queue improves. A 30-day cycle forces the team to measure the constraint, remove it, and test the ramp. It also gives leadership a clear decision point.
The plan should have one executive sponsor, one technical owner, and one operations owner. The technical owner should understand the production system. The operations owner should understand the queue, the customer language, and the manual work. The sponsor should set the decision rule before the work starts. The team should know which metrics approve the ramp and which metrics stop it. A hardening cycle without a decision rule becomes another improvement project with no operating consequence.
The 30-day plan works best with a small fixed team. Adding more people usually increases coordination cost. A senior engineer, an operations owner, a product manager, and part-time data support can complete most first-cycle fixes.
 Click to expand
Click to expand Days 1 to 5 map the post-acquisition workflow
List every step from signup to first value. Identify the owner, tool, data source, and average handling time for each step. Include systems such as Stripe, Salesforce, HubSpot, Zendesk, Intercom, LaunchDarkly, Segment, and the product database. Pull 50 recent customers from the target channel and trace their path. Record where they waited, asked for help, failed setup, or needed internal action. Use the same sample for product events and staff actions.
The map should include both software events and human actions. A clean map shows when software stops and human judgment begins. That boundary is where the channel will create pressure. Use actual timestamps. Signup time, first login, first error, first ticket, first response, and first value should sit on one timeline. The timeline should show gaps in minutes or hours, not vague status labels.
The output should be a workflow map with owners and time costs. It should also identify the first point where the account leaves the product and enters staff work. That point is usually the first candidate for engineering. The mapping process should include failed accounts, not only activated accounts. Activated accounts show the intended path. Failed accounts show the operating defects that will grow with demand.
The sample should include at least 10 accounts that opened support tickets and 10 accounts that failed to activate. If the channel is new, use the closest existing channel as a proxy. The proxy should be replaced once new channel data reaches a workable sample.
Days 6 to 10 quantify the operational load
Calculate five channel-level metrics:
- Activation rate within 24 hours
- Manual onboarding minutes per account
- Provisioning failure rate
- Support tickets per 100 accounts
- Engineering escalations per 100 accounts
These metrics should be visible daily. Weekly reporting is too slow during a channel ramp. A failed partner launch can create hundreds of poor customer experiences before the next weekly meeting. The team should also record the top five reason codes behind failures. Examples include missing permissions, failed import, unclear setup step, billing mismatch, and duplicate account. Reason codes turn vague complaints into engineering work.
Reason codes make the work concrete. They prevent teams from treating all failures as generic “onboarding friction”. They also help leadership decide whether the fix belongs in product, operations, billing, documentation, or partner qualification. Each reason code should have volume and time cost. “Failed import” means little without frequency. “Failed import affects 18% of new partner accounts and adds 22 minutes of staff time” creates a clear engineering target.
The team should also calculate queue age. Average age can hide serious problems because new tickets dilute old ones. Use percentiles and count tickets older than the service target. Engineering escalations need their own count. A ticket that requires a developer, database edit, script run, or production investigation should be recorded separately. That count shows how much product capacity the channel consumes. The output for day 10 should be a ranked constraint list. Each item should include volume, handling time, owner, customer risk, and likely fix. The top two items become the focus for days 11 to 20.
Days 11 to 20 remove the top two manual bottlenecks
Choose the two steps with the highest total cost. Total cost equals volume multiplied by handling time, adjusted for churn risk. A low-volume issue that blocks enterprise activation can outrank a high-volume issue with minor inconvenience. Build narrow fixes. Examples include a self-serve setup checklist, an admin provisioning workflow, a webhook retry tool, or a lead-scoring script. Other examples include ticket routing rules and a dashboard that links support tickets to product events.
Each fix should have one owner and one success metric. A provisioning workflow can target manual setup minutes per account. A routing change can target owner assignment time or ticket age. Avoid broad rebuilds during this phase. The objective is absorption capacity within 10 days of engineering work. A good 10-day fix removes one queue or shortens one handoff.
A poor fix creates a new platform without reducing the next customer’s wait time. Teams often fall into this pattern when they name the problem “operations maturity”. The problem should be named as a specific queue, failure reason, or manual step. The two fixes should ship behind controls. If the fix changes account state, it needs logs and permission checks. If it changes customer communication, it needs review, testing, and a clear owner for errors.
Engineering should use production-like test cases. A provisioning tool should be tested against duplicate accounts, expired billing status, missing invite email, and existing workspaces. A routing rule should be tested against real tickets from the prior month. Operations should own adoption. A tool that support does not trust will not reduce queue time. Training, runbooks, and manager review matter as much as the code path.
The fixes should be measured immediately after release. If the top bottleneck does not move within three business days, the team should inspect usage, rule accuracy, and missing cases. A shipped tool has no value until the queue changes.
Days 21 to 30 add controls and prepare the ramp
Add logs, permissions, alerts, and runbooks for the new workflows. Train support and operations on the new tools. The training should include failure cases, not only the happy path. Then run a controlled channel ramp. Increase demand by 25% to 50%, measure the five operating metrics daily, and stop the ramp if activation falls. The team should also stop the ramp if support load rises faster than signups.
That pattern means the channel is creating work faster than the product can absorb it. It also signals that the next bottleneck moved downstream. The right response is another hardening cycle, not a larger campaign budget. This is how teams move from MVP development to production operations without converting growth into organizational stress. It gives leadership a measurable path from early traction to controlled scale. It also gives engineering a focused mandate instead of a stream of emergency requests.
The 30-day plan should end with a written decision. Continue the ramp, hold demand flat, or pause the channel until the next bottleneck is removed. The decision should cite the five operating metrics and the remaining top constraints. The written decision should include ownership for the next cycle. If the ramp continues, the team should state the next volume step and the date for review. If demand stays flat, the team should name the next bottleneck and target completion date.
A pause should include specific restart conditions. “Pause until activation recovers” is too vague. “Restart when 24-hour activation returns above 62% for five consecutive business days” gives the team a measurable target. The final review should include customer examples. Numbers show the trend. Three account timelines show how the product behaved for real customers. Both views help leaders make a grounded decision.
What leaders should do before the next channel push
Before increasing spend, partner volume, or outbound capacity, run a Channel Readiness Gate on the product operating system. Test the product against onboarding, provisioning, support, escalation, observability, and controls. Treat failed checks as growth risks, not back-office concerns. Do not approve a 5x channel ramp while onboarding, provisioning, support, and escalation depend on manual judgment. Assign one senior engineer and one operations owner to remove the top two bottlenecks in 30 days. Give that pair authority to change internal workflows and instrument the result. Removing that manual labor is backend and operations engineering: automated provisioning, typed account state, and logged controls.
Require dashboards that show activation, failures, tickets, and churn by channel within 24 hours. Require owners for each operating layer before the ramp begins. Require logs and permission checks for every workflow that changes account state, billing, or permissions. The executive team should also require a stop rule. A channel that reduces activation, increases unresolved support age, or raises engineering escalations above threshold should pause. This rule protects customer trust and product capacity. Growth should create revenue, learning, and market position. The operating system behind the product determines whether that happens. A company that hardens the post-acquisition path before the ramp can turn channel demand into serviceable, retained customers.
Algorithmic hardens the post-acquisition path with backend and operations engineering: automated onboarding, provisioning, and the controls that keep account state correct under volume. If a channel ramp is coming, have us run a channel readiness gate.


