
Most enterprise SaaS products eventually reflect their contract history more than their product strategy. A major account asks for a custom approval flow. A regulated buyer needs field-level audit controls. A strategic deal depends on a legacy ERP integration. Each request is reasonable, revenue-backed, and shipped fast behind a conditional tied to an account ID.
These are sound decisions at the moment of sale. They turn expensive once the product has no formal way to hold variation, and every exception settles into the codebase as hidden state. The first few are easy to carry. After a dozen, releases slow because no one can list every account-specific behavior that might break, and support starts tracking customers by name in place of product rules.
This is customization debt, and it behaves as an operating cost across three areas: architecture that resists change, QA that grows with every customer, and support that lives in the memory of senior engineers. No single team sees the full bill, so the cost stays out of view until release dates slip or support margins thin.
Containing it depends on a product architecture that treats variation as a governed, first-class concept, with owners, tests, and a decision gate that every exception clears before signature. The sections below put a number on the cost, then set out the modular architecture, the four-gate framework, and the four-to-eight-week program that brings it under control.
Customization debt starts with rational exceptions
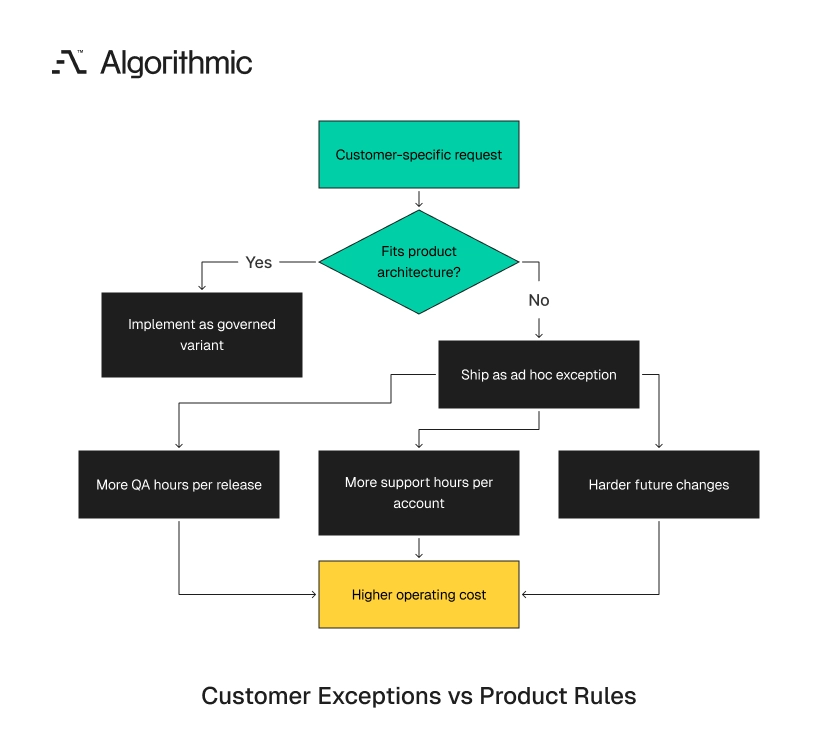
The first customer-specific patch is defensible in many early enterprise deals. The contract is material, the build looks narrow, and the engineering estimate is 3 days. The patch ships behind a conditional branch tied to an account ID.
That decision becomes expensive when it repeats without a product architecture review. One exception creates local complexity. Twelve exceptions create a release-management problem.
 Click to expand
Click to expand Rich Mironov’s discussion of customization debt frames the product risk well. Enterprise software firms accept bespoke requirements to win revenue. Support, release planning, and roadmap clarity then degrade as the exception base grows. The same pattern appears in engineering reviews. Code paths reveal a history of commercial exceptions in place of deliberate product design. The product starts reflecting the contract archive more than the product roadmap.
A sequence choice becomes debt when it raises the future cost of adding the next variant. Shipping iOS before Android is deferred work if the product architecture remains portable. Hard-coding customer-specific entitlement checks into 14 service methods creates debt because every future entitlement rule becomes harder to add, test, and remove. The distinction matters. Engineering leaders should not label every tradeoff as debt. They should model incremental cost, including QA hours, support hours, release risk, and future change cost.
A useful test is reversibility. A deferred Android release can be funded later through a defined product backlog. A set of account-specific entitlement checks requires code discovery, behavioral comparison, regression analysis, and customer communication before removal. That removal work rarely fits into the original estimate. The 3-day patch becomes 2 weeks of cleanup after the customer leaves, the feature becomes standard, or a new entitlement model replaces the old one.
The same pattern appears in integration work. A custom NetSuite export takes 4 days during procurement and becomes permanent operational surface area. Two years later, the team must retest it during every billing change, even after the original sponsor has left the customer organization.
The inflection point arrives when sales outpaces consolidation
Customization becomes dangerous when the business closes exceptions faster than engineering consolidates them. CTOs and product executives should watch this operating threshold. It surfaces first in release planning, then in customer support, then in sales qualification.
A team can absorb 2 or 3 customer-specific cases during early market entry. It can document them in a runbook, add targeted tests, and manage the risk manually. That approach fails when the exception rate exceeds the consolidation rate for 2 or 3 quarters. The exact number varies by product surface area. A workflow platform with permissions, approvals, and integrations reaches the threshold faster than a single-purpose reporting tool. The governing metric is the rate of new variants minus the rate of variant consolidation.
The first signal is release fear. Engineers delay releases because no one can list every account-specific behavior that will regress. QA plans expand from feature verification to account-by-account regression analysis. The second signal is support escalation by account name. Tickets read “Customer A cannot use the new billing screen” in place of “approval workflow validation fails for delegated approvers.” Support teams learn customer histories in place of product rules.
The third signal is sales dependency on engineering exceptions. Sales cannot describe the product without promising account-specific behavior. Product management becomes a negotiation layer between revenue pressure and codebase integrity.
A fourth signal appears in planning meetings. Engineers ask whether a feature applies to “standard customers” or “Customer B customers.” That phrase means the product model has fractured.
A 2025 IcePanel architecture survey reported 75 respondents, with 57% architects and 29% engineers or developers. The survey found continued concern about architecture communication as systems grow. The sample is small, and the pattern matches field experience: undocumented architecture decisions create local certainty and global confusion. The same confusion appears in incident response. During a production issue, teams spend the first 30 minutes identifying which customers use the affected path. That time should be spent isolating the defect, reviewing telemetry, and confirming rollback safety.
The inflection point also changes hiring needs. A team that once hired product engineers starts hiring staff who can remember account exceptions. That shift is a warning sign because memory has replaced architecture. A fifth signal appears in roadmap language. The team stops estimating features by product area and starts estimating by affected accounts. Planning then becomes a customer-by-customer impact review, which slows every material release.
The cost is measurable
A useful model has 4 variables:
- A: number of account variants
- R: releases per month
- Q: QA hours per variant per release
- S: support hours per variant per month
Monthly variant cost = (A × R × Q) + (A × S)
For 18 variants, 2 releases per month, 3 QA hours per variant, and 5 support hours per variant, the monthly cost is 198 hours. At a loaded engineering and QA cost of $115 per hour, the visible cost is $22,770 per month.
This excludes opportunity cost. If 4 engineers spend 25% of their time reasoning about hidden variants, a 12-person product engineering team loses the output of 1 full engineer. At a $190,000 loaded annual cost, that is another $15,833 per month.
The combined monthly burden reaches $38,603 before customer success, product management, and incident response are counted. Over 12 months, the visible and engineering opportunity cost exceeds $463,000. That amount funds a focused modularization program and a meaningful tranche of QA automation.
Finance teams miss this cost because it is distributed across departments. QA absorbs part of it. Engineering absorbs part of it. Support absorbs part of it. No single cost center sees the complete variant tax. The CFO sees headcount growth, the CTO sees slower delivery, and the CRO sees enterprise commitments as isolated wins. The system cost remains hidden until release dates slip or support margins deteriorate.
The same cost model works before approval. A proposed exception with 2 QA hours per release and 4 monthly support hours costs 8 hours per month at a 2-release cadence. At $115 per hour, that is $920 per month before engineering discovery or incident response.
For a $20,000 ARR account, the economics fail quickly. For a $300,000 ARR account, the work can make sense if it becomes a governed variant. The commercial decision should include revenue, build cost, and recurring operating cost. The cost model should also include incident exposure. If a variant causes one Sev-2 incident per quarter with 6 engineers involved for 4 hours, that adds 96 engineering hours per year. At $115 per hour, the incident load adds $11,040 before customer credits or executive escalation time.
The accounting should remain simple enough for deal review. ARR, expected gross margin, variant run-rate, and removal cost give executives the right decision surface. A custom request with no recurring cost estimate should not receive approval.
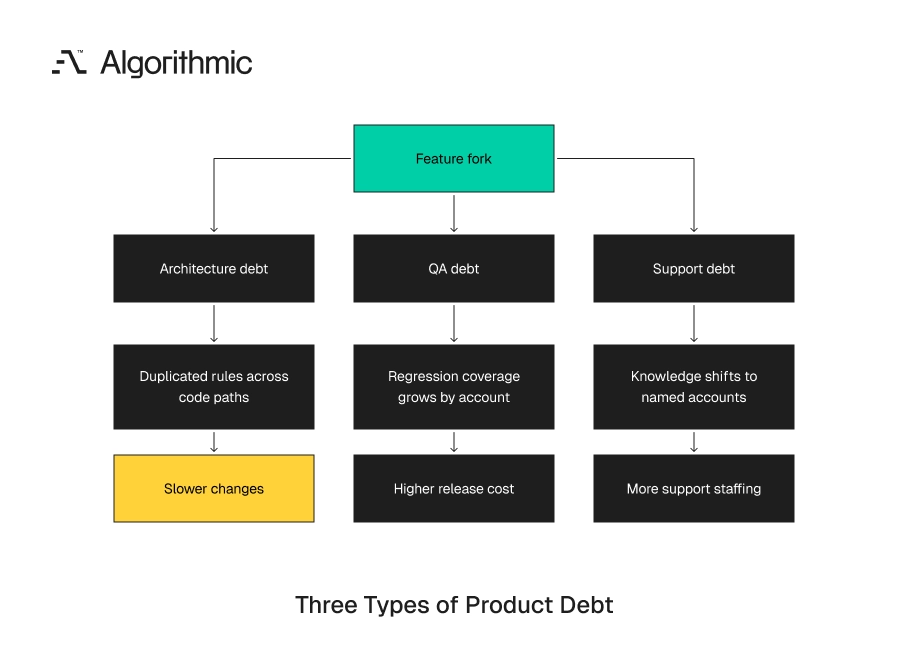
Feature forks create three forms of product debt
Feature forks are often discussed as code quality problems. That framing understates the cost. They create debt across architecture, QA, and commercial operations. These three debt types behave differently. Architecture debt slows changes. QA debt increases release cost. Support debt changes the staffing model.
Treating them as one issue hides the operating damage. The remediation plan also becomes weaker because each debt type needs a different control.
 Click to expand
Click to expand 1. Architecture debt from duplicated rules across code paths
The simplest warning sign is a conditional branch that checks customer_id, tenant_id, or account_type inside business logic. One branch is tolerable. Repeated branches across controllers, services, workers, and frontend components create inconsistent product behavior.
Common examples include:
if customer_id == "enterprise_a"inside billing logic- environment variables that control behavior for one customer
- duplicated React components for the same workflow
- forked API routes with slight differences in validation
- one-off database columns used by a single account
- background jobs with customer-specific schedules inside shared worker code
- reporting exports with account names embedded in SQL templates
- exception lists stored in admin notes in place of configuration tables
- permission overrides maintained in scripts in place of product settings
- Terraform variables tied to one tenant instead of one product configuration
- cron jobs named after customers instead of a reusable integration process
- API validation rules that branch by plan name and account ID together
These patterns make the next change slower because engineers must inspect every variant before editing shared logic. The work also becomes senior-engineer dependent. New team members cannot trust the product model because the rules live across scattered branches. The damage increases when the same concept receives different names in different locations. A “delegated approver” in the backend becomes “secondary signer” in the frontend and “proxy approver” in support documentation. That naming drift turns one product rule into three disconnected concepts.
Architecture debt also weakens code review. Reviewers cannot judge a change by reading the modified file because the behavior depends on branches elsewhere. A small pull request then requires institutional memory that no static analysis tool can infer. The highest-risk pattern is duplicated authority. A rule lives in the database, another version lives in application code, and a third version lives in a support runbook. During a production incident, the team has to determine which source governs current behavior.
Architecture debt also distorts ownership. One team owns billing screens, another owns entitlement services, and a third owns data export jobs. A customer-specific billing exception then cuts across all three teams without a single owner.
2. QA debt when regression coverage grows by customer count
Bespoke behavior multiplies test cases. A feature with 5 states and 4 customer variants creates 20 behavior combinations before role permissions, plan entitlements, and integrations are included. Add 3 roles and 2 integration states, and the theoretical matrix reaches 120 combinations. Pairwise testing can reduce coverage burden, and contract tests can protect module boundaries. Those methods require explicit variant modeling. Ad-hoc forks force QA teams to test by account history.
Feature velocity slows in mature products for this reason. Releases become harder when teams manage dependencies implicitly through shared code. Clear architectural boundaries make regression scope smaller and more predictable. QA debt also changes how release risk is discussed. Teams stop asking whether the workflow meets acceptance criteria. They start asking whether Customer A’s workflow still behaves the same.
That distinction affects every release note, test plan, and rollback decision. A product acceptance test becomes an account preservation exercise. The release process accumulates manual checks because the product lacks a reliable model of difference. Automated tests do not solve this alone. A large test suite that encodes account-specific behavior without clear ownership becomes another undocumented system. Tests need variant metadata, module ownership, and removal rules.
A strong test name should explain the product rule, not the account name. delegated_approval_requires_two_finance_approvers gives engineering and QA a rule. customer_a_special_case_still_works gives the company an obligation with no product model. QA debt also slows incident recovery. If the rollback plan has to preserve 7 customer-specific flows, the release manager needs more time to approve the rollback. In high-change products, that extra time increases customer-visible downtime.
A mature QA model separates shared-path tests from variant tests. Shared-path tests verify the common workflow, API contract, and persistence behavior. Variant tests verify the selected policy, connector, entitlement rule, or export format.
3. Support debt when knowledge moves from product rules to named accounts
Support teams should resolve issues through product behavior, entitlement state, and data conditions. Feature forks move support knowledge into account-specific institutional memory. This changes staffing, onboarding, escalation, and renewal planning. That creates a linear support model. Each bespoke account adds context, escalation paths, runbook entries, and release caveats. The company then needs more support staff for every tranche of custom revenue.
This is the clearest executive-level cost. Product debt has become an operating model constraint. The margin profile of enterprise revenue declines as support cost follows the account count. Support debt also weakens customer success planning. CSMs become responsible for remembering which features were custom, which were temporary, and which were later productized. Renewal conversations then depend on private knowledge in place of product telemetry and contract terms.
The risk compounds when a CSM or senior support engineer leaves. A runbook entry that says “Confirm with Priya before changing this account” is not a control. It is a dependency on one employee’s memory. A mature support model needs labels, configuration state, known failure codes, and documented product rules. The support team should diagnose a variant from a ticket, a log query, and a module registry. They should not need to read application code or search Slack history.
Support debt also affects onboarding. A new support analyst can learn product rules through training, documentation, and case review. Account-specific knowledge requires shadowing, private notes, and repeated escalation to senior staff. Support debt changes renewal economics as well. Customers with custom behavior require more preparation before business reviews. The account team must verify which exceptions remain active, which are contractual, and which have been absorbed into the standard product.
Modular architecture turns exceptions into governed variants
Modular architecture gives teams formal places to put difference. The goal is controlled variation. Teams need an architecture that accepts product variation without scattering account-specific decisions across the codebase. Designing that structure deliberately is SaaS platform engineering work, not an afterthought handled one deal at a time. A modular product can support multiple approval flows, partner integrations, pricing models, and compliance rules. Each variation belongs behind a named interface, configuration schema, or feature flag. The shared product path remains understandable.
Enterprise products need variation. A regulated bank, a public-sector agency, and a mid-market software company will use different approval rules. The product should represent those differences as governed variants with owners, tests, and telemetry.
A governed variant has six properties:
- a named product concept
- a clear owner
- a documented interface
- a typed configuration model
- test coverage at the contract boundary
- telemetry that support teams can read
Those properties turn custom work into product structure. They also give sales and customer success a precise way to discuss variation with buyers. A governed variant also has a lifecycle. It starts as an approved exception, moves into a named extension point, and receives review at renewal or roadmap planning. The owner decides whether it stays, becomes standard, or retires.
Feature flags control exposure
Feature flags manage access to behavior by tenant, cohort, plan, or rollout stage. Mature teams use systems such as LaunchDarkly, Unleash, or OpenFeature in place of building flag logic into application code. Governance discipline determines whether flags reduce risk or create a new control plane. Flags need governance. Every flag should have an owner, creation date, default state, expiry date, and removal condition. A flag registry should be searchable by product area and tenant.
Flags without lifecycle rules become another form of debt. A product with 200 active flags and no removal process has replaced hard-coded forks with configuration risk. Engineers then debug runtime state across flags, plans, entitlements, and customer records. A production-grade flag policy also defines blast radius. A new workflow flag should start with internal tenants, then 2 pilot customers, then a defined cohort. Each stage needs rollback ownership and telemetry thresholds.
The flag policy should distinguish release flags from permission flags and experiment flags. A release flag controls staged rollout. A permission flag controls entitlement. An experiment flag supports measurement and must have a planned end date. Mixing these categories creates confusion. A flag named new_approval_flow_customer_a does not explain the product rule, rollout stage, or removal condition. A flag named approval_policy_delegated_v2_release gives engineering, QA, and support a shared reference.
Flag review should happen during release readiness. The release manager should know which flags changed, which tenants are exposed, and which rollback steps exist. That review should take minutes because the registry already contains the required fields. Flags also need ownership after launch. A release flag that stays open for 14 months becomes permanent product state without product governance. Each quarterly engineering review should retire expired flags and move long-lived behavior into modules or entitlement rules.
Modules isolate variant behavior
Modules should contain a complete unit of variation: interface, implementation, tests, observability labels, and configuration. Approval workflows are a clear example. A shared approval-policy contract can define the small set of operations every variant implements: how it evaluates a request, who the required approvers are, what audit events a decision emits, and how it reports a failure reason. A standard approval flow, a delegated approval flow, and a compliance approval flow then implement that same interface. The calling service does not need to know which customer requested which version. It only needs the policy selected for the tenant.
This approach works in a modular monolith, a service-oriented system, or a microservice architecture. The deployment shape is secondary to boundary discipline. Spring Modulith, ArchUnit tests, and fitness functions are useful because they enforce module boundaries before service proliferation.
A strong module boundary has three properties. It has a small public interface. It owns its data rules. It exposes telemetry that support and engineering can read without code inspection.
Modules also reduce coordination cost. A team can change the delegated approval module after contract tests pass. Teams no longer need to inspect unrelated billing, onboarding, and notification code for hidden account branches.
The module should also own vocabulary. If the module uses “delegated approver,” the frontend, API, support runbook, and analytics events should use the same term. Shared vocabulary reduces translation errors during incidents and renewal discussions.
A module registry should list active module types, owners, tenant mappings, and version history. Support can then confirm that Tenant 184 uses approval_policy_delegated_v2 and netsuite_connector_standard_v3. Engineering can trace defects to a module version instead of an account name.
Module boundaries also support pricing. If a compliance approval policy requires specialized maintenance, the company can price it as an enterprise feature or paid add-on. Without a module boundary, pricing teams see a custom request while engineering inherits permanent complexity.
Consolidated code paths reduce release risk
Consolidation means shared orchestration with variant behavior behind explicit interfaces. The checkout flow, onboarding flow, or billing cycle remains one product path. Variant rules plug into named extension points.
This reduces regression scope. QA tests the shared path once, then tests each module contract and the variant-specific rules. Support teams diagnose by configuration state and module version in place of customer-specific code history. The outcome is faster release confidence. Teams no longer rely on senior engineers remembering why an exception exists. Releases depend on visible configuration, tested contracts, and documented ownership.
A consolidated path also improves analytics. Product teams can compare adoption, failure rates, and conversion across module versions. That evidence supports productization decisions and retirement decisions. For example, a company can measure whether delegated approval reduces cycle time by customer segment. It can also identify whether a compliance approval module creates more rejection events or support tickets. Those measurements guide roadmap choices better than anecdotal account feedback.
Consolidated paths also improve security review. Security teams can assess one shared workflow and a defined set of extension points. That is easier to audit than 17 customer-specific branches across services and frontend components.
The same principle applies to data models. A single approval_policy table with typed policy configuration gives the product one source of truth. Account-specific columns in unrelated tables create migration risk and reporting confusion.
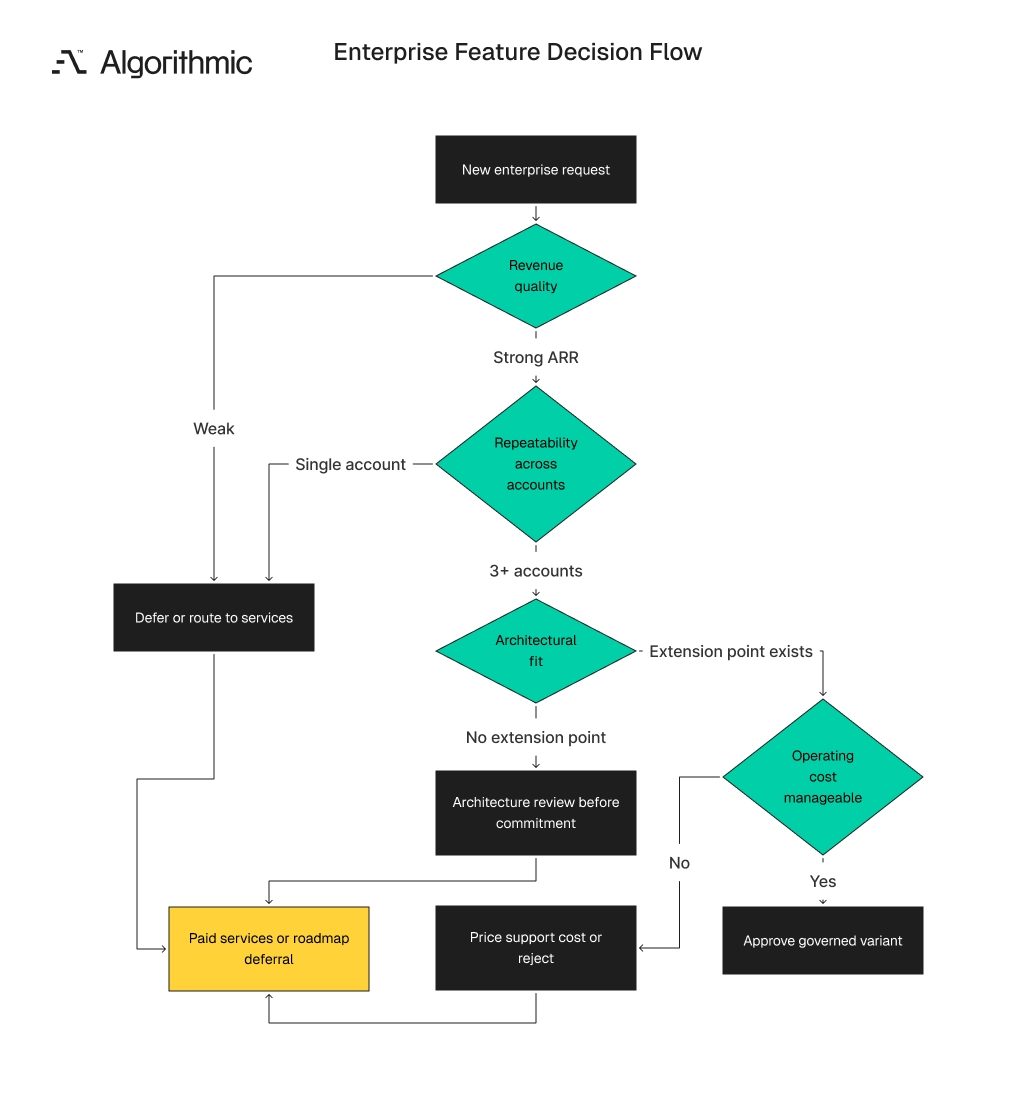
The 4-gate variant decision framework
CTOs need a decision method that sales, product, and engineering can use before accepting custom work. The 4-Gate Variant Decision Framework separates revenue exceptions from architecture decisions. It also gives sales a clear path for pricing and escalation.
| Gate | Decision question | Accept when | Reject or defer when |
|---|---|---|---|
| 1. Revenue quality | Does the work attach to durable revenue? | Contract value exceeds a defined threshold, such as $100,000 ARR, and renewal risk is clear | The request supports a low-margin account or a one-time implementation fee |
| 2. Product repeatability | Will at least 3 accounts need this within 12 months? | Product has evidence from pipeline, churn analysis, or existing support tickets | The behavior reflects one customer’s internal process |
| 3. Architectural fit | Can the variation live behind a flag, module, or configuration schema? | The team can define a stable interface before build starts | The change requires account checks across unrelated services |
| 4. Operating cost | Can QA and support handle the variant through standard tools? | Test cases, runbooks, logging, and support labels can ship in the same release | Support needs customer-specific escalation knowledge |
 Click to expand
Click to expand A request that fails Gate 3 should trigger a software architecture review before any delivery commitment. A request that fails Gate 4 should include explicit support cost in the commercial model. This changes the economics before the contract is signed.
This framework changes the conversation. Sales can still pursue enterprise revenue. Engineering gains a disciplined way to price the future cost of difference.
The framework also protects account teams. A salesperson can tell a buyer that the company supports governed variants through defined extension points. That answer is stronger than an informal promise to customize the product after signature.
For example, a $250,000 ARR buyer asks for a custom approval policy tied to its procurement hierarchy. The request passes Gate 1. It passes Gate 2 if 4 pipeline accounts have similar delegated approvals. It passes Gate 3 only if the policy fits the approval module contract. It passes Gate 4 when support can diagnose the policy through logs, labels, and runbooks. The request then becomes a governed variant.
A different buyer asks for a custom billing screen that mirrors its internal cost-center taxonomy. The request has revenue value. It fails repeatability when no other account has asked for the same workflow. That request should move to a paid services path, an export workflow, or a roadmap deferral. If the buyer requires the screen inside the product, the commercial model should include build cost, maintenance cost, and a defined support term. The framework works best when it becomes part of deal review.
Product and engineering should review enterprise commitments before signature. A signed contract with unpriced variation leaves architecture teams negotiating from a weak position. The gates should have named approvers. Revenue quality belongs to sales leadership and finance. Repeatability belongs to product management. Architectural fit belongs to engineering leadership. Operating cost belongs jointly to QA, support operations, and customer success. The approval record should live with the account and the product backlog. Six months later, the team should see why the variant was accepted, who owns it, and what review date applies. Without that record, governance decays into undocumented institutional knowledge.
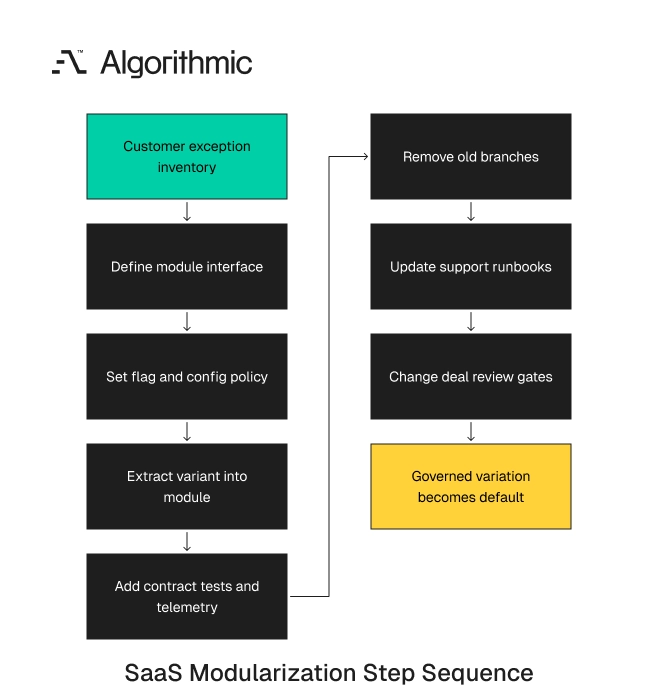
A practical modularization program takes 4 to 8 weeks
A productization effort does not need to pause the roadmap for a quarter. In a typical B2B SaaS codebase with 10 to 25 customer variants, a focused modularization program takes 4 to 8 weeks with 3 to 5 senior engineers. The team should include one staff engineer or architect, one product manager, one QA lead, and one support operations lead.
The effort should be scoped around the highest-change product area. Billing, permissions, approval workflows, partner integrations, and reporting exports are common starting points. Choose the area with the most releases, the most support tickets, and the highest variant density. The team should define success in operational terms. Good targets include a 30% reduction in variant regression hours, removal of 10 account-specific branches, or migration of 80% of one workflow into governed modules. These targets keep the work tied to release cost and support cost.
The program should produce working architecture: removed branches, added tests, improved diagnosis, and usable extension points. Each week should remove branches, add tests, improve support diagnosis, or create a usable extension point. A visible operating result keeps the work credible with executives. The program also needs a freeze rule. During the 4-to-8-week effort, new exceptions in the selected area should pass architecture review before commitment. Without that rule, the team removes debt while sales creates replacement debt.
 Click to expand
Click to expand Week 1 inventory variants and map code paths
Create a variant inventory with 6 fields: customer, feature area, entry point, code location, support owner, and revenue source. Use static search for tenant_id, customer_id, plan names, environment variables, and forked routes. Add SQL searches for account names and one-off columns. The output should be a map of variant density. If 60% of account-specific logic sits in onboarding and billing, do not start with reporting exports. Start where the release risk and support load concentrate.
The inventory should also identify ownership gaps. A variant with no product owner, no support owner, and no removal condition is uncontrolled product behavior. Those cases deserve priority because no team has active responsibility for them. The inventory should include support artifacts. Search Zendesk, Intercom, Salesforce notes, Jira labels, and implementation plans for customer-named behavior. Code tells one part of the story; support records reveal how the behavior operates in production.
A useful output is a heat map with product area on one axis and variant count on the other. Add monthly ticket count, release touch count, and ARR exposure. This gives executives a ranked backlog instead of a general architecture concern. The inventory should include contract references. A variant required by a master services agreement carries different risk than a variant created during implementation. Legal status affects removal timing and renewal strategy.
The team should also mark variants by type. Common categories include workflow policy, entitlement rule, integration, data export, reporting format, UI behavior, and compliance control. Categories help product managers identify repeated demand across customer names.
Weeks 2 to 3 define interfaces and flag policy
Select one product area and define the module interface. Write architecture decision records for the boundary, flag policy, and test model. ADRs work because they capture the decision at the moment it is made.
Research on architecture decision records continues to study adoption and developer engagement. The practical value is direct: future engineers can read why the boundary exists. They do not need to infer intent from commit history. Set up or refine the feature flag platform during this phase. Define flag naming, ownership, expiry, default behavior, and rollback process. Add required fields for tenant exposure and customer impact.
The team should also define the configuration schema. A variant should have a typed configuration object, allowed values, validation rules, and defaults. Free-form JSON fields become a second codebase without compiler checks. The schema should include migration rules. If a variant becomes standard, the configuration should move to default behavior through a planned release. If the variant is retired, the configuration should expire with a tracked removal issue.
Architecture decision records should remain short. A useful ADR states the problem, decision, alternatives considered, consequences, owner, and review date. Two pages are enough for most product variant decisions. The interface design should include failure modes. For an approval policy, failure codes can include missing_required_approver, approval_limit_exceeded, and delegation_expired. Support can then diagnose behavior through logs and customer-facing messages.
The flag policy should include emergency controls. A release manager should know how to disable a variant for one tenant, one cohort, or all tenants. Rollback authority should be named before the first customer receives the new path.
Weeks 4 to 6 extract modules and add contract tests
Move variant behavior out of shared orchestration code. Add contract tests for every module implementation. Add integration tests for the shared path and the most material customer configurations.
Instrument the modules with logs and metrics. Every variant execution should expose tenant, module version, flag state, and failure code. This gives support teams a product-level diagnosis path. The extraction work should proceed in thin slices. Migrate one variant, prove parity, remove the old branch, then repeat. Large rewrites increase risk and delay visible progress.
Contract tests should define the behavior every module must satisfy. For an approval module, that includes approver selection, escalation handling, audit event creation, and failure-code mapping. Each module then adds its own specific tests. Parity testing deserves explicit planning. Capture current behavior with approval fixtures, API snapshots, workflow traces, and production log samples. Then prove the new module produces the same expected outcomes for the same inputs.
The extraction team should publish a weekly scorecard. Track branches removed, modules added, contract tests created, flags retired, and support runbooks updated. Executives need operating progress, not architecture terminology. The scorecard should also track release impact. If regression work drops from 42 hours to 29 hours in the selected area, report the reduction in hours and dollars. That converts architecture work into a business result.
Code review standards should change during extraction. New account checks inside shared orchestration should be blocked. Reviewers should require module placement, typed configuration, and test ownership for every new variant.
Weeks 7 to 8 remove old branches and update support operations
Remove account-specific branches after parity tests pass. Update support runbooks, release notes, and customer success documentation. Train support teams to diagnose by flag state and module behavior. The removal step is essential. Leaving both the old fork and the new module creates duplicate authority in the system. Duplicate authority produces conflicting behavior during later changes.
Support operations should receive concrete artifacts. Those include a flag registry link, module behavior table, log query examples, escalation rules, and customer-visible language. A support analyst should identify a variant in production without asking engineering to inspect code. Product management should update the roadmap taxonomy at the same time. The product now has a governed extension point in place of a collection of customer exceptions. Future requests should route through that extension point or receive explicit review.
Customer success should receive renewal guidance. If a former custom behavior becomes a governed module, the contract language should change at renewal. If the behavior remains bespoke, the account plan should include the maintenance cost. The program should end with an executive readout. Show the before-and-after variant map, release test reduction, support diagnosis path, and remaining debt. Then propose the next product area based on measured variant density.
The readout should include decisions, not only status. Executives should approve which variants become standard, which stay paid, and which receive retirement plans. That decision closes the loop between product architecture and commercial policy. The final week should also update engineering standards. Add lint rules, architecture tests, or codeowners policies that block account-named branches in shared code. A modularization program has limited value if the next sprint recreates the same pattern.
Partner integrations need the same discipline
Partner integrations are a common source of feature forks. A customer asks for Salesforce today, HubSpot next month, NetSuite after renewal, then a regional payroll system during procurement. Each request sounds reasonable when tied to a named deal. Engineering teams should create partner tiers before integrations spread across the product. Tier 1 partners complete the platform for the target market and receive deep integration support. Tier 2 partners use a standard connector framework. Tier 3 requests go through export, webhook, or API paths.
This prevents the product from becoming a catalogue of one-off connectors. It also gives sales a clear answer during procurement. Buyers hear which integration paths are standard, which are configurable, and which require paid work. The same rule applies to internal extension points. A product should have named places where variation belongs: identity providers, data exports, workflow policies, billing rules, notification templates, and compliance reporting. Variation outside those boundaries requires architectural approval.
Partner tiers need operational criteria. A Tier 1 integration should have bidirectional sync, monitoring, error handling, support documentation, and version compatibility tracking. A Tier 2 connector should use common authentication, mapping, retry, and webhook patterns. A Tier 3 request should have a clear default answer. Offer CSV export, API access, webhook delivery, or a paid services engagement with defined maintenance terms. Undefined integration promises create long-lived support obligations.
Integration design should also account for vendor change. Salesforce, NetSuite, Workday, and HubSpot change APIs, limits, scopes, and webhook behavior. Each deep integration needs an owner who monitors version changes and support impact. Connector frameworks should standardize 5 areas: authentication, field mapping, retry policy, failure reporting, and data reconciliation. Without those standards, each integration becomes its own mini-product. That structure recreates feature-fork debt outside the main workflow.
Integration tiers should be visible in sales materials. A buyer should know whether Workday is Tier 1, whether BambooHR uses a standard connector, and whether a regional HRIS requires paid services. Clarity during procurement reduces pressure on engineering after signature. The same tiering model should guide deprecation. If a Tier 1 partner loses market relevance or creates excessive maintenance cost, product leadership should review the tier. Deep integrations need recurring investment, so they deserve periodic commercial review.
The executive decision is timing
Modularization consumes delivery capacity. A 6-week effort with 4 senior engineers at a $125 loaded hourly rate represents about $120,000 in engineering cost before product management, QA, and support are included. That cost should be compared with the current variant run-rate. Avoiding the work carries a larger recurring cost when variants accumulate. If the current model burns 198 hours per month in QA and support, and the organization values that time at $115 per hour, the annual run-rate is $273,240. The payback period on a focused modularization effort can be under 6 months.
That calculation should appear in roadmap planning. Custom work deserves the same financial rigor as infrastructure spend, cloud cost, or headcount. The CFO should see the recurring cost of unmanaged variation. Architecture debt often arrives through reasonable local choices. The executive risk is waiting until every release requires regression triage across hidden variants. By then, the product roadmap has already ceded capacity to exception maintenance.
The timing decision should use three triggers. Start modularization when active variants exceed 10, when variant QA exceeds 15% of monthly QA capacity, or when support tickets require customer-named runbooks. Those thresholds signal a structural issue. Executives should also examine margin quality. A $300,000 ARR account with 25 monthly support hours and frequent release exceptions has a different margin profile than a standard $300,000 ARR account. Revenue quality includes maintenance cost.
The decision should also consider strategic focus. If the company is moving upmarket, governed variation is part of the product strategy. If the company sells to a narrow segment with standardized workflows, custom variation should face a higher approval bar. A board-level discussion should treat feature forks as product economics. The question is how much recurring engineering, QA, and support cost the company accepts for each dollar of enterprise revenue. That ratio gives executives a practical control point.
Boards should ask for the variant run-rate beside ARR growth. A company adding $2 million of enterprise ARR while adding $600,000 of recurring variant cost has a margin problem. The issue will appear later as slower releases, higher support load, and weaker gross margin.
Timing also affects morale. Engineers will accept tactical exceptions when leadership names the tradeoff and funds cleanup. They lose trust when every custom deal becomes permanent hidden work with no owner and no removal plan.
Replace the checklist with five executive gates
A CTO or product executive needs a high-signal review before approving bespoke customer work. Ten isolated questions create review fatigue. Five gates force the right decision.
Gate 1 commercial quality
Confirm the ARR, renewal risk, expansion value, and contract term tied to the request. A one-time implementation fee does not justify permanent product complexity. Durable recurring revenue can justify a governed variant when the margin remains attractive. The approval record should state the revenue threshold. For many growth-stage B2B SaaS companies, $100,000 ARR is a practical starting point for architecture review. The threshold should rise when support margins tighten or engineering capacity is constrained.
Gate 2 repeatability
Confirm existing demand and pipeline demand. At least 3 accounts within 12 months is a practical threshold for productized variation. A single customer’s internal workflow belongs in paid services, an integration, or a documented deferral. Repeatability should come from evidence. Pipeline notes, win-loss analysis, support ticket clusters, and churn interviews carry more weight than one account executive’s forecast. Product management should own this evidence before engineering starts design work.
Gate 3 architectural placement
Identify the flag, module, configuration schema, or entitlement rule that will hold the variation. Name the shared code paths that will change. If the team cannot name the extension point, the request needs architecture review before commitment. The architecture review should produce a boundary decision. That decision should name the interface, data ownership, telemetry, test model, and removal condition. A custom request with no placement becomes a release risk by default.
Gate 4 test and support readiness
Define the contract tests, integration tests, logs, metrics, and support labels before build starts. Support should diagnose the behavior through tools already used in production. Engineering should not become the permanent escalation path for a named account. Support readiness should include sample cases. A support analyst should see what error codes, log queries, and customer messages apply. That preparation prevents the first production ticket from becoming the documentation process.
Gate 5 lifecycle ownership
Assign the owner, review date, removal condition, and migration path. Every variant should have an expiry trigger or a productization trigger. Long-lived exceptions need explicit commercial approval at renewal. Ownership should survive team changes. The owner should be a role or group, such as the approvals product team, not one engineer. The registry should list current accountable leaders and review dates.
These gates should sit inside enterprise deal review beside security review, legal review, and pricing approval. That placement makes product variation a commercial decision. It also prevents engineering from becoming the last team asked to price the cost of a signed commitment. Deal review should block vague commitments. Language such as “custom workflow support” should be replaced with a named module, bounded configuration, acceptance criteria, and maintenance term. The contract should match the architecture the team intends to build.
The decisive action path
Begin with the codebase and support records. Search for customer_id, tenant_id, plan names, account names, environment variables, and customer-named routes. Build a variant inventory with owner, revenue source, release touch count, and support ticket count.
Then quantify the monthly variant cost. Use releases per month, QA hours per variant, support hours per variant, and loaded hourly cost. Present the number beside ARR so executives can see margin impact.
Next, choose the product area with the highest variant density. In most B2B SaaS products, that area is billing, permissions, approval workflows, partner integrations, or reporting exports. Fund a 4-to-8-week modularization sprint with a named staff engineer, product manager, QA lead, and support operations lead.
The sprint should produce 6 concrete artifacts: a variant registry, a module interface, a flag policy, contract tests, support runbooks, and removed customer branches. Measure success through reduced regression hours, retired forks, and faster support diagnosis. Do not accept architecture work that produces documentation without code changes.
Finally, change deal review. Every new enterprise exception should pass the five gates before signature. Requests that fail architectural placement move to architecture review. Requests that fail repeatability move to paid services or roadmap deferral.
Feature forks are manageable when they are modeled as product variants. They become product debt when they remain hidden inside patches, branches, and account-specific support knowledge. The cost appears in release confidence, support staffing, and roadmap capacity.
Review the current codebase this week. Quantify the variant tax before the next enterprise exception is approved. Fund the highest-density modularization sprint, remove the first 10 customer branches, and make governed variation the only approved path for new custom work.
Algorithmic builds modular SaaS platforms that hold account-specific variation behind governed, tested extension points. If customization debt is shaping your roadmap, book a review of your variant backlog.


