
[ Insights - Product Development ]
The False Economy of the Quick MVP
Learn how engineering shortcuts during validation create compounding costs that exceed the price of building correctly from day one.
Read time: 9 minutes
The technology industry has adopted a dangerous misreading of the Minimum Viable Product. Teams across startups and enterprises default to low-cost, fragile architectures to validate concepts quickly. For complex systems such as applications with real user data, multi-step workflows, or integration dependencies, this approach generates compounding operational costs that exceed the price of sound engineering from day one.
A throwaway MVP means paying for the same software twice: once for the prototype that cannot scale, and again for the production system that replaces it. The gap between those two payments is filled with slow deployments, manual testing, engineer attrition, and stalled feature delivery.
There is a more effective sequence which involves validating the market with high-fidelity mockups and user research, then engineering a production-grade core architecture from the first commit.
Financial traps and why "quick" architecture costs more (a lot more!)
A common belief among technical leaders persists that the earliest iteration of a product should cost as little as possible, because the market might reject it. This reasoning leads to systems built as single-codebase monoliths, without deployment automation, state management, or test coverage. The logic makes intuitive sense - why invest in a robust system if customers might not want the product?
The answer lies in how software costs compound. Building an application shares structural logic with building a house. You can adjust finishes, reduce square footage, and select less expensive materials - but you still need a sound foundation with load-bearing walls and a weatherproof roof. By cutting the foundation, you are scheduling a more expensive repair - maybe in 2 months, maybe in 3 months - but it is coming.
Software behaves in a similar manner, where a codebase without automated tests, deployment pipelines, or modular boundaries accumulates what engineers call technical debt. Each new feature built on a fragile base takes longer to ship, breaks more existing functionality, and requires more manual verification. The costs do not stay flat. They compound.
Let's consider a practical scenario where a team builds an MVP in 12 weeks with no automated testing and no CI/CD pipeline. We have seen this in the past, where six months later, every feature release takes three weeks instead of three days - two of those weeks spent on manual regression testing and firefighting deployment failures. By the end of this firefighting ordeal, the engineering team will recommend a full rewrite, and the business has now paid for the same product twice, with a 9-month gap of degraded velocity in between.
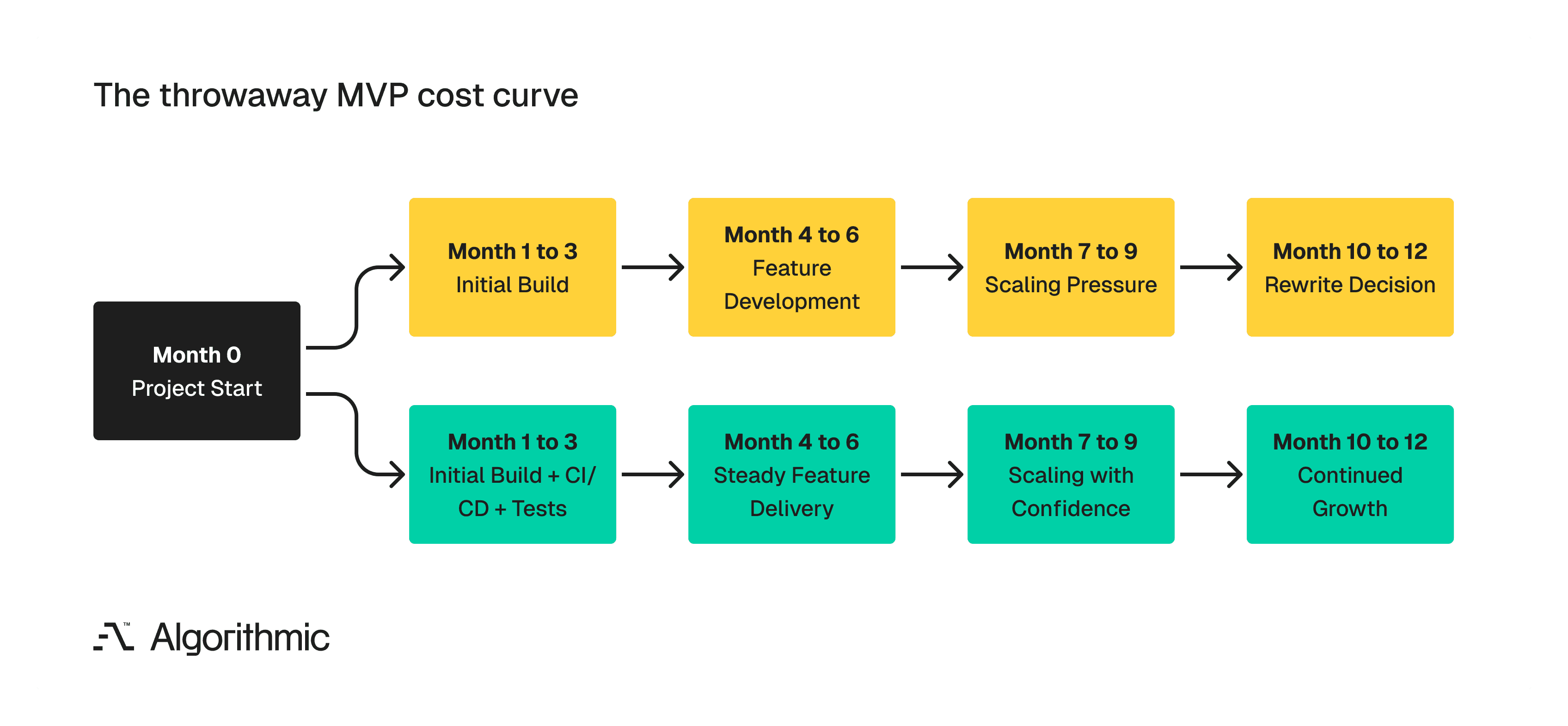
The confusion starts at the point of feature scope vs. engineering quality
This failure pattern persists because teams conflate two separate variables where what you build and how you build it. "Minimum" in Minimum Viable Product describes scope - the smallest set of features that tests your market hypothesis. What it does not describe is the engineering rigour and the product's overall design aesthetics. A product can have three features and still have automated test coverage, a CI/CD pipeline, and a modular codebase. A product can also have 30 features and still lack those qualities.
The distinction matters because scope and quality have different cost profiles. Reducing scope saves time linearly - fewer features, fewer development hours. Reducing engineering quality saves time in week one and costs multiples of that time by month six.
The compounding cost of manual processes
We have delivered over 30 products in the last three years, and we have observed three specific engineering shortcuts that create the majority of throwaway-MVP debt. Each one saves a small amount of time upfront and generates a high, recurring cost downstream.
1. No automated testing
When developers skip automated unit and integration tests, every subsequent code change becomes a manual verification exercise. Without automated tests, no one knows whether that change broke the notification system, the reporting module, or the user authentication flow. The team discovers these breaks in production - or worse, their customers do (which is quite embarrassing). Over a six-month period, the engineering hours spent on manual testing and bug-fixing routinely exceeded the hours it would have taken to write automated tests from the start. The math is straightforward, where writing a test once allows it to run thousands of times at near-zero marginal cost. Manual testing costs the same number of hours every single time.
2. No continuous delivery pipeline
Without automated deployment, every release becomes a high-stakes manual event. One analogy is that a developer packages the code, a team lead reviews the deployment steps, someone runs the migration scripts by hand, and the team holds its breath during the push to production. We have seen this process create two problems, almost always. First, it makes deployments risky, which makes teams deploy less frequently, which makes each deployment larger and riskier - a self-reinforcing cycle. Second, it creates a bottleneck in which only engineers who understand the deployment process can execute it, and they spend an increasing share of their time on releases rather than on features.
Continuous delivery (includes automated build, test, and deploy pipelines triggered by code commits) converts deployment from a high-risk event into a routine, repeatable operation. Implementing it from day one costs a few days of setup. Retrofitting it into a fragile codebase after six months of manual deployments costs weeks.
3. Tightly coupled architecture
When the entire backend lives in a single, interdependent codebase, every component shares the same failure boundary. A bug in the image processing module can cause the checkout flow to crash, or a database migration for the reporting feature can lock the entire application.
Modular architecture, whether through well-defined service boundaries, serverless functions, or simply disciplined code separation, is seen to isolate failure. If the notification service has an issue, the core application continues to function. This isolation also enables independent deployment, where teams can update one service without retesting and redeploying the entire system.
The appropriate architecture depends on the product's complexity, team size, and expected scale. A well-structured modular monolith with clear internal boundaries can serve many products effectively. The point is deliberate structural decisions, made at the start, that prevent the codebase from becoming an undifferentiated mass of interdependent logic.
Organisational costs and what bad architecture does to teams
The financial argument against throwaway MVPs is concrete, and the organisational damage deserves equal attention. Engineers who work in codebases without tests, deployment automation, or structural boundaries experience a specific kind of professional frustration. Every deployment carries risk, every feature request requires navigating accumulated technical debt, and every production incident traces back to a shortcut taken months ago.
Senior engineers, the ones with the experience to build systems correctly, are the first to leave these environments. They have options, and they choose teams where their knowledge and depth are valued. The engineers who remain are seen facing an increasing workload and decreasing morale. The client or stakeholder realises their investment has produced a system that cannot support the business, and the rewrite conversation begins. This cycle is avoidable and existed even before we had AI coding agents.
So.. what is the better sequence? Validate first, then engineer.
The recommended product development sequence separates market validation from engineering investment, ensuring that code is only written after demand is confirmed.
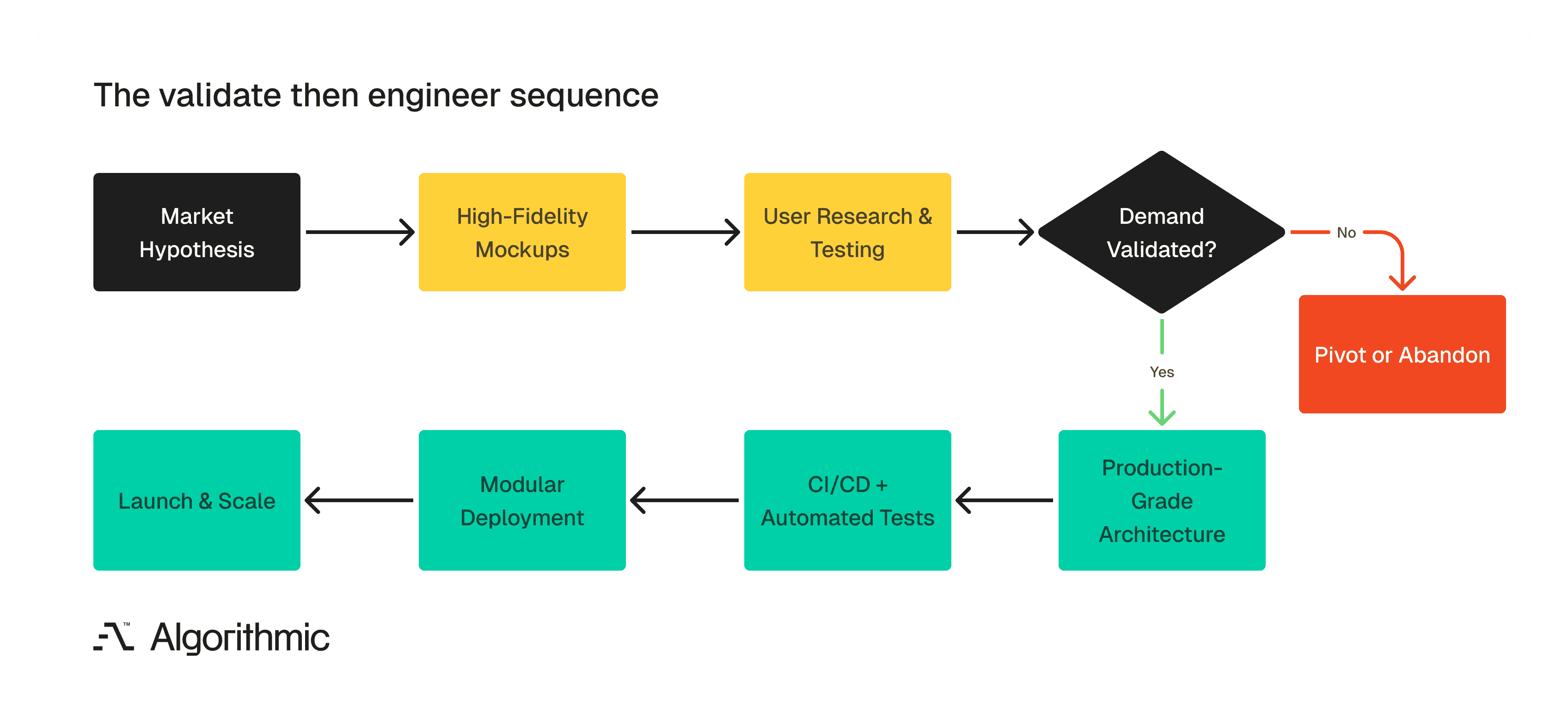
The instinct to validate before committing engineering resources is correct. The typical execution misses an important step. You do not need to write code to validate a business concept. The most capital-efficient way to test a market hypothesis is through high-fidelity mockups and structured user research. A complete set of interactive mockups allows you to simulate the user experience, gather specific feedback on workflows, and validate demand signals - all without a single line of production code.
This approach answers the core question - "Will customers pay for this?" - at a fraction of the cost of even a minimal codebase. If the mockups reveal that the market does not want the product, you have spent thousands instead of tens of thousands. If the mockups confirm demand, you move to engineering with validated requirements and tested user flows.
When the decision is made to build, build with production-grade engineering from the first commit:
Automated test coverage from day one, where every function that handles business logic gets a test.
Continuous delivery pipeline configured before the first feature ships. Deployments should be automated, safe, and frequent.
Modular architecture appropriate to the product's complexity. This must be done by defining service boundaries early, even if everything runs in a single deployment initially.
Infrastructure as code and the environment configuration should be version-controlled and reproducible, preventing the "it works on my machine" class of deployment failures.
This sequence, validated with mockups and then engineered with a clear plan, eliminates the scenario in which a business pays for the same product twice. The system used to serve the first ten customers is the same system that serves ten thousand.
What to ask before you authorise an MVP budget
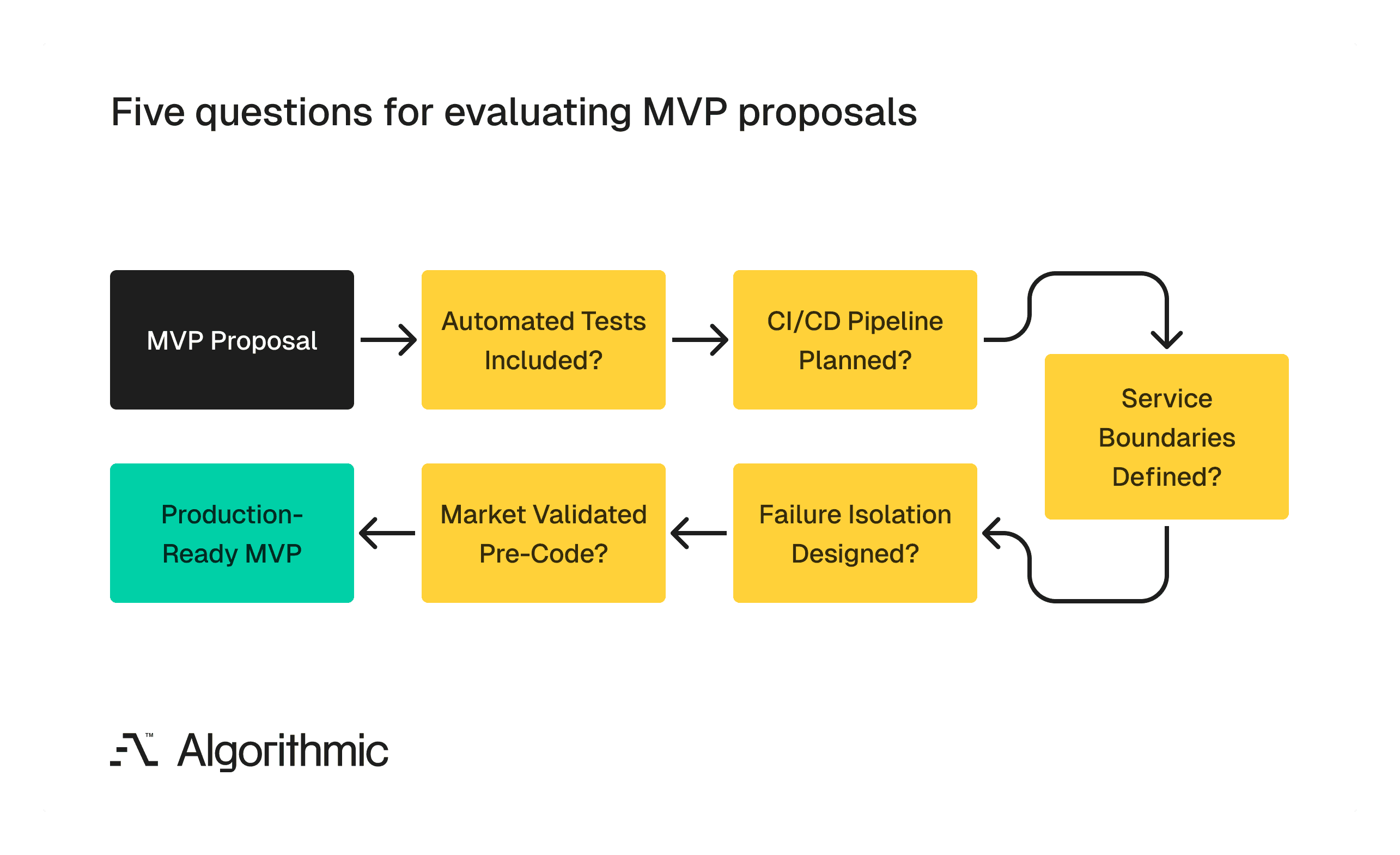
For founders, executives and product leaders evaluating engineering proposals, five questions separate a production-ready MVP from a “quick” one:
Does the proposal include automated test coverage? If testing is described as a "Phase 2" activity, the Phase 1 system will accumulate defects, making Phase 2 significantly more expensive.
Is there a CI/CD pipeline in the architecture plan? If deployments are treated as manual processes, every release will carry risk and consume engineer time that should be devoted to features.
How are service boundaries defined? If the answer is "we will refactor later", the codebase will become increasingly difficult and expensive to modularise as it grows.
What happens when a single component fails? If the answer is "the whole system goes down", the architecture lacks the isolation needed for reliable production operation.
Has the market hypothesis been validated before code is written? If the team is writing code to test whether customers want the product, they are using the most expensive possible validation method.
Use this decision framework to evaluate whether an engineering proposal will produce a production-ready MVP or a throwaway one.
How we build at Algorithmic
The throwaway MVP is a false economy. It promises speed and frugality, and it delivers compounding costs, engineer attrition, and eventual rewrites. The financial and organisational damage of poor foundational engineering exceeds the investment required to build correctly from the start.
Validate your market with mockups and research. Then engineer a core architecture that your first customers and your ten-thousandth customer can rely on. The system you launch with should be the system you scale with.
This is the discipline we bring to every engagement at Algorithmic. We are a software engineering studio that partners with founders and enterprise teams across the full product lifecycle, from validated concept to production system that holds under real-world load. Our core areas of focus include end-to-end product development, applied machine learning & AI, and data analytics & infrastructure.
If you’d like to follow our research, perspectives, and case insights, connect with us on LinkedIn, Instagram, Facebook, X or simply write to us at info@algorithmic.co



