
[ Insights - Machine Learning ]
MLOps - Driving structural value from AI investments
Stop losing AI ROI to technical debt. Discover the 6-stage MLOps framework to automate deployment, monitor data drift, and ship resilient ML models.
Read time: 13 minutes
In the current enterprise landscape, a high-performing model is not a high-performing product. ML development begins with the experimentation phase, which is often characterised by large-scale experimentation and static validations. It is also where business value is seen plateauing.
In the last two years, we have seen a handful of SMEs content with a significant implementation gap, which manifests as a structural friction between a successful "proof of concept" and a well-tested, revenue-generating production system.
According to research by MarketsandMarkets, the MLOps market is projected to reach $5.9 billion by 2027, growing at a CAGR of 41%. This rapid expansion is a direct response to the reality that nearly 85% of machine learning models historically fail to reach production. Organizations are shifting their strategic focus from model development to operational excellence, recognizing that the primary bottleneck to AI adoption is the infrastructure required to sustain it.
Defining the operational base of what is MLOps
MLOps (Machine Learning Operations) is the engineering discipline that standardises the machine learning lifecycle. It moves the organisation from "bespoke" manual deployments toward a robust, automated framework. A machine learning model is a living system. It depends on data distributions that shift, user behaviours that evolve, and business requirements that pivot over its lifetime. A model that drove high ROI six months ago may silently drift in performance over time. MLOps provides the infrastructure to detect drift, trigger retraining, and redeploy, enabling the organisation to scale from isolated experiments to enterprise-wide AI adoption.
The limitations of traditional DevOps in non-deterministic systems
Traditional DevOps manages one primary codebase where the logic is deterministic, and the inputs are predictable. Machine learning introduces three dimensions of complexity that traditional DevOps frameworks cannot resolve. Google researchers defined it as "Hidden Technical Debt in Machine Learning Systems":
Data as a first-class dependency: ML models are shaped by the data they consume. A change in data distribution can degrade a model's performance even when the underlying code remains identical. DevOps pipelines lack native mechanisms for dataset versioning or detecting distribution shifts.
Tripartite versioning: In ML, a "release" is a specific combination of code, training data, hyperparameters, and the resulting model weights. Tracking this requires a Model Registry.
Systemic observability: DevOps tracks system uptime. MLOps must track Model Vitality, which assesses whether the model remains accurate and whether the business metrics tied to it are holding steady.
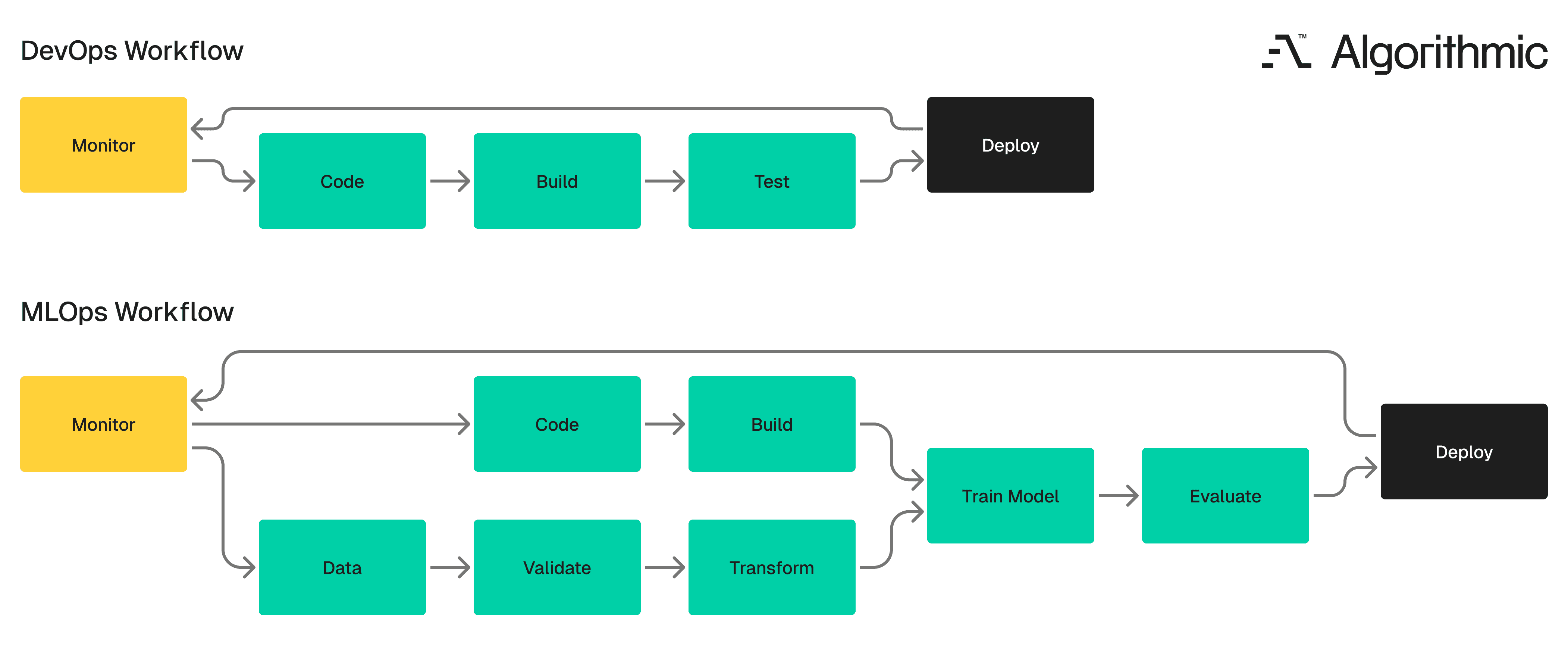
The MLOps workflow extends the DevOps pipeline by adding parallel tracks for data validation, model training, and performance monitoring. Teams that try to force ML systems into a pure DevOps framework eventually hit operational bottlenecks such as deployments that cannot be reproduced, models that degrade without warning, and debugging sessions that take weeks because no one tracked which data version produced which model.
Discover the key ways MLOps adds value and enhances your strategies
Organisations that achieve MLOps maturity capture specific, measurable operational advantages:
Faster development-to-deployment cycles: Automated pipelines remove the manual steps between training a model and releasing it. Teams that previously spent weeks on deployment can compress that timeline to hours when the pipeline is working.
Reliable production performance: Continuous monitoring detects accuracy degradation, data drift, and latency spikes before they reach end users. Instead of discovering a problem through customer complaints, the system catches it and initiates corrective action automatically.
Reproducibility across teams and projects: Systematic tracking of code versions, data versions, model configurations, and experiment results enables any team member to reproduce previous results. This eliminates the "it worked on my machine" problem that plagues ML teams operating without version control for their full stack
Auditability and compliance: Regulated industries require strict documentation of data provenance and model decision-making to comply with frameworks like the NIST AI Risk Management Framework or the EU AI Act. MLOps generates this audit trail systematically.
Scalable Architecture: MLOps provides the centralised governance required to manage fifty models with the same operational overhead as one.
The six stages of an MLOps pipeline
The journey from raw data to a model serving real users follows a structured sequence. Each stage has specific inputs, outputs, and quality gates. Skipping any stage introduces risk that compounds downstream.
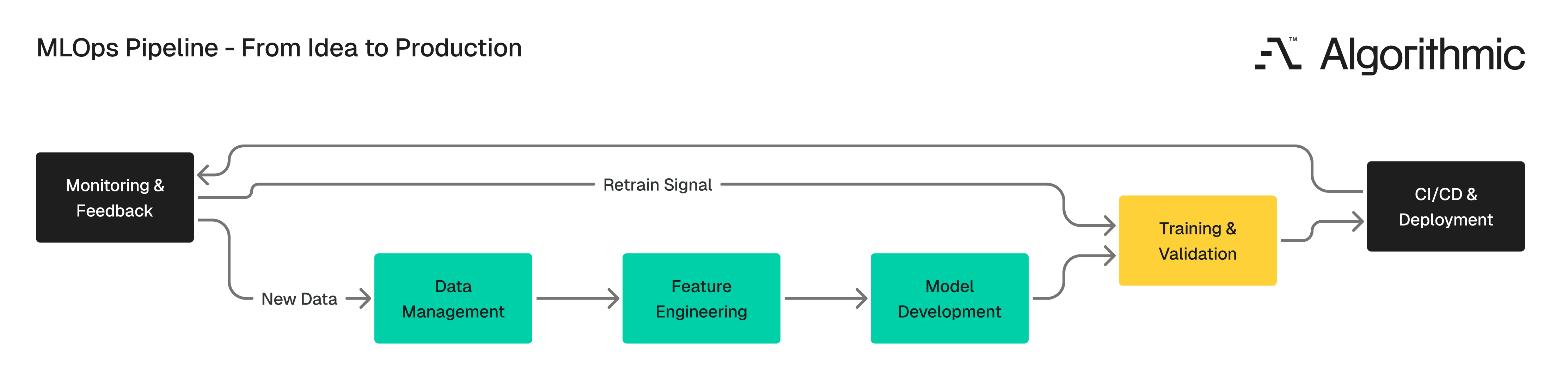
Stage 1 - Data management and feature engineering
Data quality strictly determines model quality. This phase standardises data collection, cleaning, and storage. Utilising a Feature Store (a concept pioneered by Uber's Michelangelo platform) consolidates engineered features for reuse across the enterprise, preventing duplicated engineering effort. Version control for datasets is just as important as for code. When a model's accuracy drops, the first question is often "Did the data change?". Without data versioning, a team cannot pinpoint the true cause of model failure.
Stage 2 - Model development and experimentation
Data scientists and ML engineers experiment with different model architectures, algorithms, and hyperparameters during this stage. The key operational practice is experiment tracking, which involves recording which combination of code, data, and configuration produced which results.
Tools like MLflow and Weights & Biases make this tracking systematic. Without them, teams rely on spreadsheets, naming conventions, and memory, all of which break down as the number of experiments grows. Reproducible development environments are very helpful here. Whether teams use Jupyter notebooks, cloud-based IDEs, or containerised setups, the goal is that any team member should be able to rerun an experiment and get the same result.
Stage 3 - Model training and validation
Automated training pipelines are central to this stage. Instead of manually configuring training runs, teams define pipelines that handle data loading, training execution, hyperparameter tuning, and validation in sequence.
Cloud platforms like AWS SageMaker, Google Vertex AI, and Azure ML provide the compute infrastructure to scale training up or down based on the job's requirements. A model that takes 12 hours to train on a single GPU might finish in 90 minutes on a distributed cluster and the pipeline manages that resource allocation automatically. A model registry stores trained model artefacts along with their performance metrics, training data references, and configuration details. When it's time to select a model for deployment, the registry provides a clear comparison of the candidates.
Stage 4 - Continuous delivery for machine learning (CD4ML)
Pioneered by thought leaders like Martin Fowler, CD4ML extends standard software CI/CD. It introduces rigorous validation layers:
Data validation: Checks whether input data conforms to expected schemas, distributions, and quality thresholds. A model trained on data with 50 features should not silently accept data with 48 features.
Performance validation: Checks whether the retrained model meets accuracy, precision, recall, or other metric thresholds before deployment. If a newly trained model performs worse than the current production model, the pipeline blocks the release and alerts the team.
Deployment strategies borrowed from software engineering, such as canary releases or blue/green deployments, can be applied here. A canary deployment routes a small percentage of traffic to the new model, while the rest continues to hit the existing version. If the new model performs well, traffic gradually shifts. If it degrades, the rollback is automatic.

Stage 5 - Deployment and serving
Deployment makes the model available to users through APIs, batch processing jobs, or edge devices. The infrastructure typically involves Docker containers for packaging and Kubernetes for orchestration, the same tools used in modern software deployment, applied to model serving.
Managing multiple deployed model versions is a practical concern at this stage. Production environments often run several model versions simultaneously - an A/B test comparing two approaches, a legacy model serving one region while a newer version serves another, or a fallback model that activates if the primary model fails. Operational efficiency matters here since model serving consumes compute resources, and inefficient serving configurations can drive cloud costs higher than the model's business value justifies. Right-sizing infrastructure and optimising inference latency are ongoing tasks.
Stage 6 - Observability and closed-loop feedback
Monitoring in MLOps tracks three distinct layers.
Model performance: This includes accuracy, precision, recall, latency, and throughput. These metrics tell you whether the model is still doing its job.
Data health: This includes input data distribution compared to training data distribution. When these diverge beyond a defined threshold (a condition called data drift), the model's predictions become unreliable even though the model itself has not changed.
Business impact: This includes the downstream metrics that the model is meant to influence. A recommendation model might track click-through rates. A fraud detection model tracks false-positive rates and the dollar amounts of fraud it catches. If the model's business metrics decline, that signal is as important as a drop in accuracy.
These three layers create a closed feedback loop. As detailed in Google Cloud's Practitioners Guide to MLOps, detecting drift should automatically trigger the retraining pipeline, creating a self-healing system.
The MLOps tool ecosystem
Selecting the right tools depends on your pipeline's maturity, your team's skills, and the cloud infrastructure you already use. The ecosystem is divided into six categories, each mapped to a pipeline stage. These include:
Experiment tracking platforms such as MLflow and Weights & Biases log parameters, metrics, and artefacts from training runs. They enable systematic comparison of experiments and the reproduction of past results.
Data management tools such as DVC (Data Version Control) and Delta Lake handle dataset versioning, change tracking, and collaborative data workflows. Feature stores like Feast centralise engineered features for reuse.
CI/CD platforms such as Jenkins, GitHub Actions, and GitLab CI automate integration testing, model validation, and deployment for both code and model artefacts.
Orchestration platforms such as Kubeflow and Apache Airflow manage complex, multi-step workflows. They handle dependencies between training, validation, and deployment tasks, and they retry failed steps without restarting the entire pipeline.
Cloud ML services such as AWS SageMaker, Google Vertex AI, and Azure ML offer integrated environments that cover training, deployment, and monitoring within a single platform. These are particularly useful for teams that want managed infrastructure rather than assembling tools individually.
Monitoring tools such as Prometheus, Grafana, and Evidently AI track model health, data drift, and system performance. They trigger alerts when metrics cross defined thresholds.
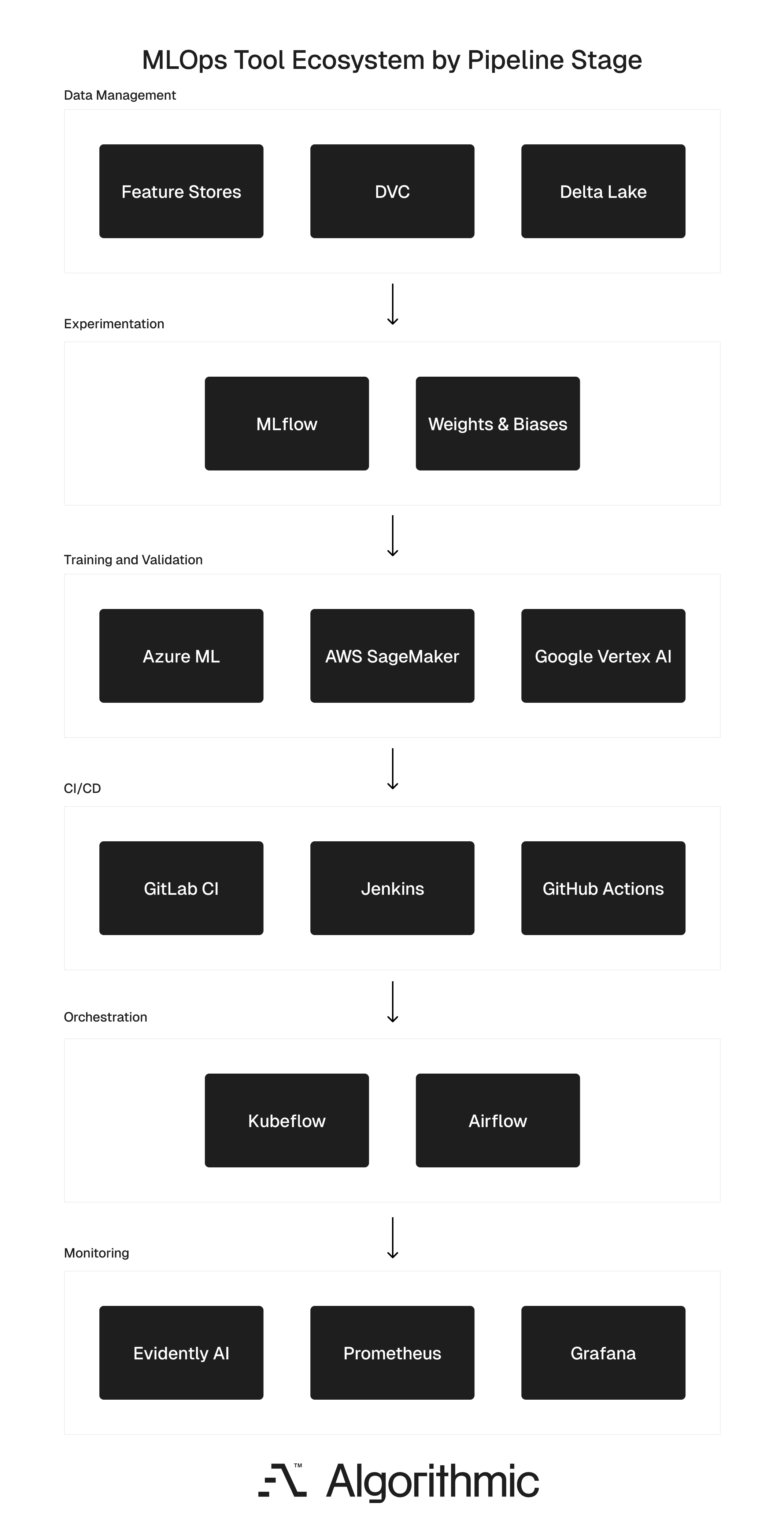
No single tool covers the entire pipeline. Most production MLOps stacks combine tools from several categories, connected through orchestration and CI/CD layers.
What works and what slows teams down
Below is a set of best practices that we use internally at the studio, and also advise our clients, to accelerate the development lifecycle and adoption:
Start with one model and pipeline: Teams that try to build an organisation-wide MLOps platform before deploying a single model through it tend to over-engineer the system and under-deliver results. A pilot project with a single, well-understood model reveals the real operational gaps without the complexity of managing dozens of models simultaneously.
Automate in steps, but do so early: Manual steps in a pipeline are failure points since each manual step, such as data preparation, model validation, or deployment, is a place where errors creep in and tend to increase timelines. Automating these steps one at a time (particularly starting with the most error-prone), builds a reliable pipeline without requiring a massive upfront investment.
Build cross-functional teams: MLOps sits at the intersection of data science, software engineering, and infrastructure operations. Teams that keep these disciplines segregated struggle with handoffs. Take, for example, a data scientist who just develops models and passes them to an engineer who lacks the depth and context on how and why the model was developed in that specific way. All the assumptions, limitations, and practical base knowledge aren't transferred to the team. But in case we have a cross-functional team, then they all share ownership of the model, starting from the experiment all the way to production.
Treat data quality as a first-class concern: A model trained on inconsistent or poorly validated data will produce unreliable results regardless of how sophisticated the architecture is. Investing in data validation, cleaning, and governance at the start of the pipeline pays returns at every stage that follows.
Document processes as you build them: Standardised, documented workflows enable reproducibility and simplify onboarding for new team members. More importantly, when your codebase gets large, how is one even supposed to manage all of that code base and know where to start? Documentation shouldn't be considered as an overhead and instead looked at as a product of a well-functioning pipeline.
Some common obstacles
Even with a clear architectural roadmap, organisations frequently encounter systemic friction when scaling AI operations. Overcoming these barriers requires leadership to address both technical debt and organisational design simultaneously.
Architectural Fragmentation and Integration Risk: The current MLOps ecosystem is highly saturated with point solutions. Adopting tools in a decentralised, ad hoc manner inevitably yields a brittle, "Frankenstein" stack. As noted by the AI Infrastructure Alliance, connecting these disparate tools requires deliberate architectural design. Organisations must prioritise interoperable, loosely coupled frameworks to prevent catastrophic pipeline failures when a single vendor updates or deprecates a tool.
The Multidisciplinary Talent Deficit: True MLOps maturity requires a rare hybrid profile: professionals fluent in both the non-deterministic nature of machine learning and the strict deterministic rigour of software engineering. Because this talent pool remains exceptionally scarce, high-performing organisations frequently leverage strategic consulting partnerships to bridge immediate deployment gaps while systematically upskilling their internal teams.
Misaligned Operational Incentives: The most persistent bottleneck in AI deployment is cultural, not technical. Data Science teams are inherently incentivized to maximize model accuracy (driving a desire for weekly updates), whereas Infrastructure Engineering teams optimize for system reliability (driving a preference for stable, monthly releases). As highlighted in Harvard Business Review, resolving this requires dismantling silos, establishing cross-functional ML pods, and defining unified KPIs that balance innovation velocity with enterprise stability.
Technological Obsolescence Risk: The operational tooling landscape is hyper-dynamic - a cutting-edge orchestration solution can become legacy infrastructure within 18 months. Enterprise teams must actively manage the tension between adopting new capabilities and maintaining production stability. The strategic countermeasure is to build abstracted pipelines that allow individual tools to be swapped out without requiring a complete rewrite of the underlying infrastructure.
Our strategic outlook and what we think about the future of MLOps
As predictive models and Generative AI transition from experimental sandboxes to mission-critical enterprise workloads, operational rigour is becoming the primary market differentiator. The inherent complexity of modern AI systems dictates that MLOps is a foundational prerequisite for deployment.
Organisations that achieve MLOps maturity capture a distinct competitive asymmetry. They benefit from compressed deployment cycles, minimised production incidents, and robust, enterprise-grade auditability. Most importantly, they decouple AI scaling from engineering headcount, enabling the management of hundreds of models with the operational footprint historically required for just one.
Treating machine learning as a rigorous engineering discipline and applying the same systemic governance reserved for core infrastructure is the only sustainable way to ship AI products that deliver real-world ROI. If your models are currently stalled between the research lab and the end-user, the path forward requires a structural, operational overhaul.
Architecting that operational shift is precisely what we do at Algorithmic. We are a software engineering studio that partners with founders and enterprise teams across the full product lifecycle to bridge the gap between experimental AI and resilient production systems. Our core areas of focus include end-to-end product development, applied machine learning & AI, and data analytics & infrastructure.
If you’d like to follow our research, perspectives, and case insights, connect with us on LinkedIn, Instagram, Facebook, X or simply write to us at info@algorithmic.co



