
A $2 million annual data platform decision can start and end in one 60-minute vendor meeting. The first architecture question is often “warehouse or lake”. CTOs, data architects, and procurement leaders should start with operating requirements before platform taxonomy. Data warehouse versus data lake is a storage and processing discussion. The operating model comes first. Leaders need to decide who owns data products, which workloads need guaranteed latency, where governance controls sit, and how costs behave under production load. Data infrastructure architecture should follow those decisions, not precede them.
Across 35 complex engineering engagements, including platforms serving more than 14 million end users, we have seen one recurring failure, where teams commit to Snowflake, Databricks, BigQuery, Redshift, or a lakehouse platform before they list the decisions the platform must support.
The outcome is predictable. The chosen platform satisfies a technology preference, then strains under unclear ownership, uncontrolled compute spend, duplicated ingestion pipelines, and late governance controls. By the second-year renewal, the architecture has shaped team behavior. It has also shaped data trust, production support, and operating cost.
Teams should approve the operating contract that the platform imposes on engineering, analytics, finance, security, and product teams. The vendor name on the invoice should matter after those obligations are clear.
The binary framing fails the operating model
Warehouses, lakes, lakehouses, and hybrid patterns serve different operating models. A warehouse favors governed analytics with structured data, dimensional models, and predictable business intelligence usage.
A lake favors raw data retention, lower storage cost, machine learning workloads, and flexible processing. A lakehouse combines object storage with table formats such as Apache Iceberg, Delta Lake, or Apache Hudi.
A lakehouse supports SQL analytics, machine learning pipelines, and open compute engines when teams engineer it with discipline. The architecture still needs named owners, data contracts, access control, observability, and cost management. Several comparison articles define the technology categories well. The LakeOps guide to data lakes, warehouses, and lakehouses correctly notes that these architectures fail in different ways and impose different operating costs.
Many selection processes still skip the decision inventory that should precede platform comparison. The vendor shortlist then becomes a substitute for architecture. A company with 150 engineers and 12 data-producing product teams has a different problem from a 40-person SaaS company. The smaller company builds executive dashboards from Stripe, Salesforce, HubSpot, and PostgreSQL.
The larger organization needs domain ownership, contract enforcement, lineage, and self-service data product publishing. It also needs release rules for event changes, dataset retirement, and analyst-facing metric definitions.
The same platform fits one context and creates unnecessary cost in another. Architecture must match the team that will operate it.
A data stack designed for 12 analytics engineers fails when a large team of analysts, product managers, and data scientists run workloads without controls. The failure shows up in queue time, duplicate models, unclear metrics, and unmanaged spend.
A warehouse-centered design serves a finance-led analytics group well. That design becomes expensive when data scientists scan raw clickstream events daily for feature discovery. A lake-centered design serves research and model development well. That design creates dashboard trust issues when revenue, customer count, and churn definitions live in notebooks. A lakehouse reduces duplication across SQL and Spark workloads. It requires table format discipline, catalog governance, file layout rules, and engine-level cost controls. A hybrid design fits many mature companies. It fails when teams treat integration as secondary work and create separate definitions for the same customer, transaction, or product.
The operating model should answer three questions before the platform discussion starts. Which teams produce trusted data, which teams consume it, and which failures require incident response? Those answers define the architecture more accurately than a warehouse-versus-lake debate. They also give finance and procurement a better way to assess vendor proposals.
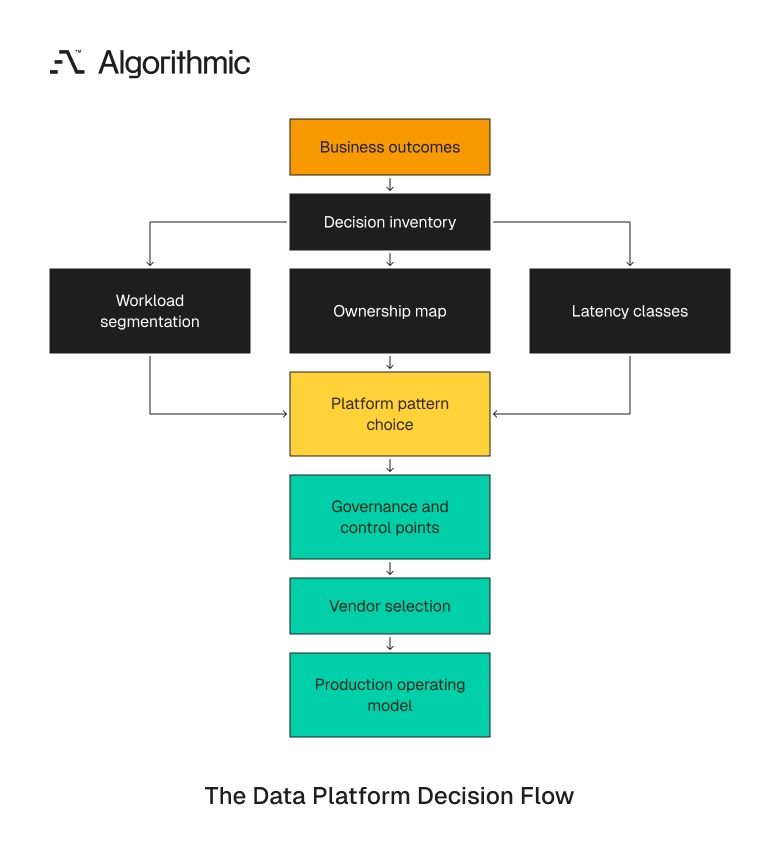
Start with a decision inventory before platform taxonomy
A decision inventory lists the business and technical decisions the data platform must support. It prevents teams from selecting storage, compute, catalog, orchestration, and governance tools before they understand usage.
 Click to expand
Click to expand This artifact should be complete before any request for proposal, vendor proof of concept, or cloud marketplace commitment. It becomes the basis for data warehouse architecture, data lake architecture, and data lakehouse architecture. It also gives procurement a factual basis for vendor comparison. Without it, pricing discussions drift toward discounts, credits, and sales engineering claims.
The decision inventory artifact
| Decision area | Required detail | Example answer | Architecture effect |
|---|---|---|---|
| Primary workloads | Top recurring queries, models, and reports | Daily revenue dashboard, churn model, fraud queue | Determines warehouse, Spark, streaming, or hybrid compute |
| Latency classes | Batch, hourly, near real-time, sub-second | Fraud events under 5 seconds; finance daily by 7 a.m. | Determines orchestration, streaming, and serving layers |
| Data ownership | Named producing teams and accountable owners | Payments team owns transaction events | Determines contracts, schemas, and release process |
| Governance control points | Where policies must be applied | PII masked before analyst access | Determines catalog, access rules, and transformation design |
| Cost drivers | Storage, compute, ingestion, egress, vendor minimums | 80 TB stored; 12 TB scanned daily | Determines commercial model and platform fit |
| Failure tolerance | Maximum acceptable delay or error | Finance close cannot miss month-end | Determines monitoring, retries, and incident response |
This inventory should include 20 to 40 decisions for a mid-sized organization. Fewer entries usually mean the team described tools instead of workloads. A long list usually shows duplicated use cases that need consolidation. The inventory should force decision clarity before platform comparison begins. Each entry should name the decision maker, consuming team, latency requirement, source systems, and failure impact. A line item such as “customer churn model” is incomplete.
A stronger entry states that the growth team needs weekly churn scores by Monday 8 a.m. It also states that the model uses product events, billing history, and support tickets. The inventory also exposes decisions that should stay outside the data platform. Some operational checks belong inside application services.
A payment authorization decision with a 200-millisecond latency requirement should run in the product architecture. The warehouse should serve monitoring, reconciliation, and analysis. A fraud analyst queue with a five-second latency target needs streaming ingestion, state handling, and a serving database. A monthly cohort report needs tested transformations, stable definitions, and audit trails.
Those two workloads should not drive the same design by default. They share source data, yet they impose different reliability, ownership, and cost requirements.
The inventory should also record consumption volume. A daily report read by six finance leaders creates a different load profile from a metric used by 2,000 sales representatives. The same distinction applies to model features. A weekly churn score used by account managers has different service requirements from a feature used during checkout.
Ownership decisions carry architectural weight
Data ownership determines where quality is created. If the central data team owns every transformation, the platform becomes a request queue. If product teams publish data products without contracts, downstream consumers inherit schema drift and unclear semantics. Both patterns create slow incident response and declining trust.
A practical ownership model assigns each critical dataset an owner, a contract, a release process, and a support expectation. For example, the payments team owns payment_authorized, payment_captured, and refund_issued events. The analytics team owns the revenue mart derived from those events. Finance owns the recognition rule that decides when revenue becomes reportable.
This distinction changes the platform design. Contract enforcement belongs in Kafka schemas, dbt tests, CI checks, or table-level constraints. The right location depends on where data changes occur and which team controls the change. If product engineers change event payloads, contract checks belong near the application release path.
Ownership also determines incident response. If the revenue dashboard drops 18% after a release, the team needs a named owner for the source event and the derived model. Without that assignment, analysts spend hours comparing pipeline logs, application deploys, and warehouse transformations. The organization pays for the same uncertainty through meetings, rework, and delayed decisions.
The ownership map should include escalation paths. A gold-tier finance table needs a different support model from an exploratory research table. For high-value data products, the owner should publish change notices before breaking schema changes. The notice should include affected fields, expected consumer changes, and a retirement date for the old version.
Ownership also affects staffing. A platform with 40 producing teams needs different governance than a platform fed by four SaaS systems. The team should name stewards for shared entities such as customer, account, order, invoice, product, and employee. These entities become the joins that determine trust in executive reporting.
Latency decisions expose hidden cost
Latency requirements should be grouped before tool selection. A daily dashboard, a 15-minute inventory forecast, and a real-time recommendation system have different compute and reliability profiles.
A single organization needs batch dbt transformations in Snowflake, Spark jobs over Iceberg tables, and Kafka streams for operational features. Combining these workloads under one vendor agreement works only when the workload profile fits the commercial model. Latency creates cost through retries, state management, monitoring, and staffing. A five-second fraud queue needs on-call coverage, dead-letter handling, and backpressure controls.
A daily finance report needs deterministic transformations, audit trails, and month-end runbooks. A customer-facing recommendation service needs load testing, fallback logic, and serving latency metrics. Teams should price latency as an engineering commitment. Sub-second serving requires a different architecture than hourly reporting.
The platform decision should reflect that boundary before a vendor demo shapes expectations. Demo environments rarely show retry storms, late events, schema drift, or month-end load. A practical latency map uses four classes. Batch covers daily or weekly jobs, hourly covers operational reporting, near real-time covers minutes, and serving covers milliseconds.
Each class needs a named path from source to consumer. Each path needs a reliability target, an owner, and a cost estimate. Latency also changes test strategy. Batch workloads need deterministic reconciliation, while streaming workloads need replay tests and ordering checks.
A five-second service target creates staffing obligations. Someone must own alerts at 2 a.m., backlog recovery, and customer communication when a stream falls behind.
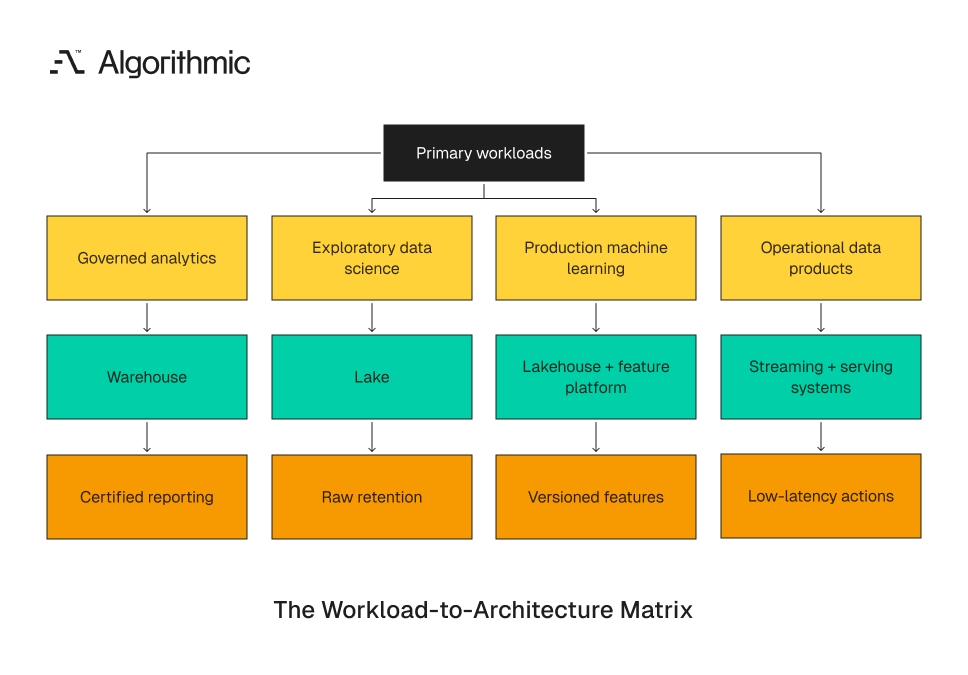
Segment workloads before choosing storage and compute
Workload segmentation turns architecture from a vendor preference into an engineering decision. The team should classify workloads into four categories: governed analytics, exploratory data science, production machine learning, and operational data products.
Each category has a different failure mode. Governed analytics fails through inconsistent definitions. Exploratory data science fails through poor discovery and weak access controls. Production machine learning fails through irreproducible features and unmonitored drift. Operational data products fail through latency breaches and unclear incident ownership. These failure modes should drive the reference architecture.
 Click to expand
Click to expand Governed analytics
Governed analytics includes finance reporting, executive dashboards, sales operations, and regulatory reporting. These workloads favor clear schemas, stable definitions, role-based access, and predictable SQL performance.
A data warehouse such as Snowflake, BigQuery, Redshift, or Azure Synapse often becomes the center of gravity. The schema should reflect business questions through dimensional modeling, semantic layers, and tested transformations. Latency is usually daily or hourly. Reliability carries more business weight than raw storage cost.
A finance dashboard that misses month-end close creates business risk beyond the compute bill. It can delay board reporting, revenue review, and sales compensation calculations. The engineering work is concrete. Teams define revenue recognition rules, customer identifiers, product hierarchies, and calendar logic.
They test transformations in dbt, monitor freshness, and publish definitions through a semantic layer or metric store. They also decide who approves metric changes before executives see them. A common failure pattern starts with a single revenue field. Sales defines it by signed contract value, finance defines it by recognized revenue, and product defines it by active subscription value.
The platform cannot fix that definition conflict after dashboards ship. The operating model must assign ownership before engineers encode the metric. Governed analytics also requires release management. A metric change should move through review, testing, approval, and communication before it reaches board reporting.
For example, a change to annual recurring revenue should identify affected dashboards, historical backfill rules, and the first reporting period. Finance should approve the definition before analysts rebuild reports.
Exploratory data science
Exploratory data science needs access to raw and semi-structured data. Teams work with JSON logs, clickstream events, images, audio, or large feature sets with unclear value at ingestion time. A data lake on S3, ADLS, or Google Cloud Storage fits this usage when paired with cataloging, access control, and lifecycle policies. Open table formats matter when multiple engines read the same data.
The article on modern table formats and data architecture covers the technical role of Iceberg, Delta Lake, and Hudi in this pattern. These formats create transaction semantics, schema evolution, and time travel on object storage. The operating discipline still matters. Raw zones need retention rules, PII tagging, and ownership.
A bucket containing five years of clickstream data without a catalog is a storage liability. The monthly storage bill can look small while discovery cost grows across every model project. Exploratory work also needs guardrails for promotion. A notebook that proves a churn signal should not become the production pipeline.
The team should define the path from exploration to governed data product. That path should include code review, data quality tests, lineage registration, and owner assignment. Without that promotion path, successful research becomes unmaintained production logic. The first model release works, then the second release breaks because the feature source changed.
Research environments also need budget controls. A single cross join over raw events can consume more compute than a month of scheduled dashboard refreshes. Teams should cap warehouse sizes, limit Spark cluster lifetimes, and tag experiments by project. Those controls make research spending visible before it becomes a renewal issue.
Production machine learning
Production machine learning needs repeatable feature generation, versioned datasets, monitored inference, and retraining processes. Pandas and scikit-learn work for early analysis.
They reach limits as data volume, team size, and service reliability requirements increase. Notebook-based workflows create lineage gaps when models start driving product or revenue decisions. Organizations with 20 or more engineers should plan for Spark-based pipelines, managed ML platforms such as SageMaker, Azure ML, or Vertex AI, or a controlled feature platform. Refactoring notebooks into production pipelines after launch creates risk in lineage, reproducibility, and drift monitoring.
The platform selection must account for batch training, online inference, offline feature stores, and A/B testing for ML models. These workloads rarely fit cleanly into a pure warehouse or pure lake architecture. A churn model gives a practical example. Training runs weekly on two years of customer activity in object storage.
Batch scoring writes results into Snowflake for sales operations. Online inference needs Redis or DynamoDB when the product shows a retention offer during a user session. Each path needs a different failure policy. A delayed weekly score affects sales prioritization.
A delayed online inference call affects product latency. The architecture should separate those obligations, even when both use the same feature definitions. Feature ownership also matters. Product events, billing events, and support tickets come from different teams.
The model owner should not become the permanent maintainer for every upstream data issue. Contracts must define which producers fix missing fields, delayed records, and semantic changes. Production machine learning also needs reproducibility controls. Teams should record training data versions, feature code versions, model artifacts, and evaluation metrics for each release.
A model that changes pricing, credit risk, fraud routing, or customer messaging needs audit evidence. The evidence should show which data trained the model and which version served predictions.
Operational data products
Operational data products serve applications, customer-facing features, and internal workflows. Examples include fraud alerts, customer health scores, search ranking features, and inventory allocation.
These products require service-level objectives. A customer health score that updates every 24 hours is an analytics asset. A fraud score that updates in 300 milliseconds is part of the product architecture. It requires production support, fallback behavior, and release discipline.
This category usually needs streaming systems, serving databases, and incident response runbooks. Kafka, Flink, Redis, PostgreSQL, DynamoDB, and vector databases sit alongside the warehouse or lake. Operational data products also require product engineering discipline. Teams need deployment pipelines, alert thresholds, rollback plans, and load tests.
A data pipeline that feeds a customer-facing workflow should be treated like production software. It needs the same operational review as an API used by customers. The risk is highest when analytics prototypes become product dependencies without architectural review. A spreadsheet-fed customer score can become a workflow trigger inside customer success.
Once that happens, stale data turns into missed renewals, misrouted work, and disputed performance reports. The platform decision must account for those operating consequences. Operational products need ownership that spans data and application teams. A streaming feature failure affects both pipeline health and customer experience.
The runbook should name the first responder, escalation owner, rollback procedure, and customer communication path. That level of detail separates production systems from analytics support.
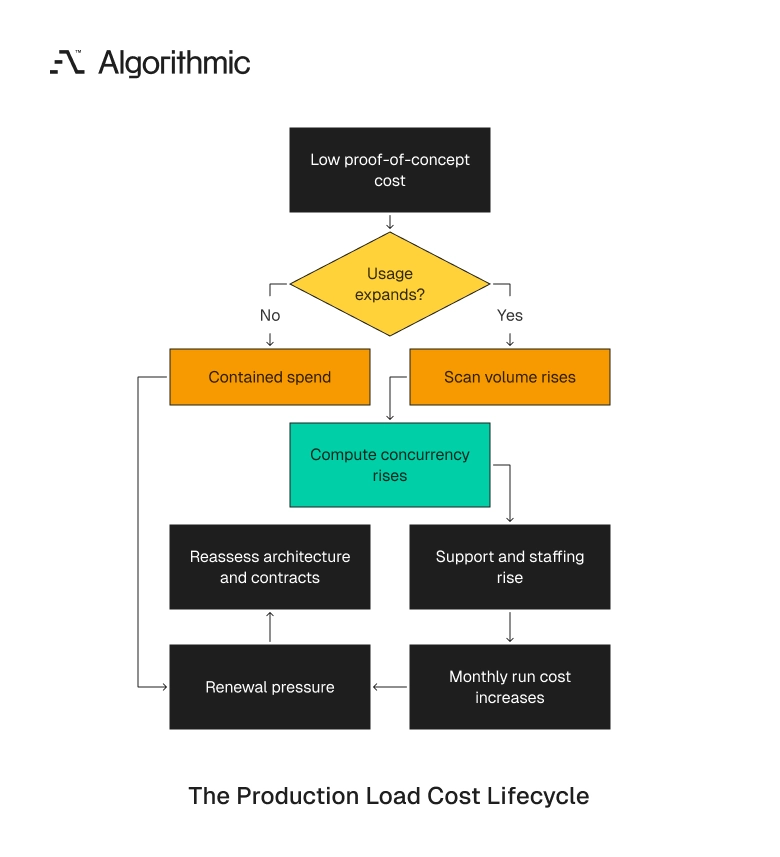
Model cost behavior at production load
Cost modeling must occur before vendor selection. Cloud data platforms have different cost curves across storage, compute, ingestion, metadata operations, egress, and support tiers.
An enterprise can add Snowflake for BI, Databricks for Spark, Fivetran for ingestion, dbt Cloud for transformations, Monte Carlo for observability, and another managed service for reverse ETL. Within 18 months, overlapping contracts can exceed $1.5 million annually before internal engineering cost. The risk grows when each tool is justified by a local team and no one models end-to-end cost at production load. A platform that costs $12,000 during a proof of concept can cost $80,000 per month after broad adoption.
 Click to expand
Click to expand A sound cost model includes five numbers:
- Stored data volume in TB by raw, curated, and serving zones.
- Daily scan volume by workload class.
- Compute concurrency by analyst, pipeline, and application usage.
- Data movement volume across regions, clouds, and vendors.
- Minimum contract commitments across managed services.
For a company storing 100 TB, scanning 25 TB daily, and running 1,000 scheduled transformations, platform choice must be tested against actual query patterns. Unit economics carry more weight than list prices. Managed services have clear value when they reduce operational burden, improve reliability, or shorten delivery time. The marginal value must be explicit.
Running Kafka on Kubernetes can be rational for a team with strong platform engineering skills and stable throughput. A managed Kafka service can be rational for a smaller team with strict uptime requirements and limited operations staff. The decision record should compare monthly service fees, incident cost, staffing needs, and recovery time objectives. It should also state which team owns upgrades, patches, capacity planning, and security reviews.
Cost models should include waste controls. Warehouses need query limits, warehouse sizing policies, and chargeback reporting. Lakes need lifecycle rules, partitioning standards, and file compaction. Streaming systems need retention limits and throughput alarms.
A cost model should also test user behavior. Analysts will run exploratory queries, product teams will request new event streams, and data scientists will scan large tables during feature discovery. Vendor calculators rarely account for those patterns with enough precision. A production model should use actual query history, scheduled job counts, and planned user growth.
Procurement should request pricing at three demand levels. The base case should reflect current usage, the growth case should reflect approved hiring, and the stress case should reflect peak concurrent workloads. This approach changes the vendor conversation. The team can negotiate on committed usage, support tiers, data egress, storage growth, and workload isolation.
It also reveals duplicate spend. A company should know when it pays three vendors for orchestration, two vendors for catalog features, and two vendors for data quality checks. Cost modeling should include internal labor. A platform that saves $20,000 per month in license fees loses money if it requires two additional senior engineers.
The model should include incident cost as well. A four-hour finance reporting outage during close can consume a full week across engineering, analytics, and finance.
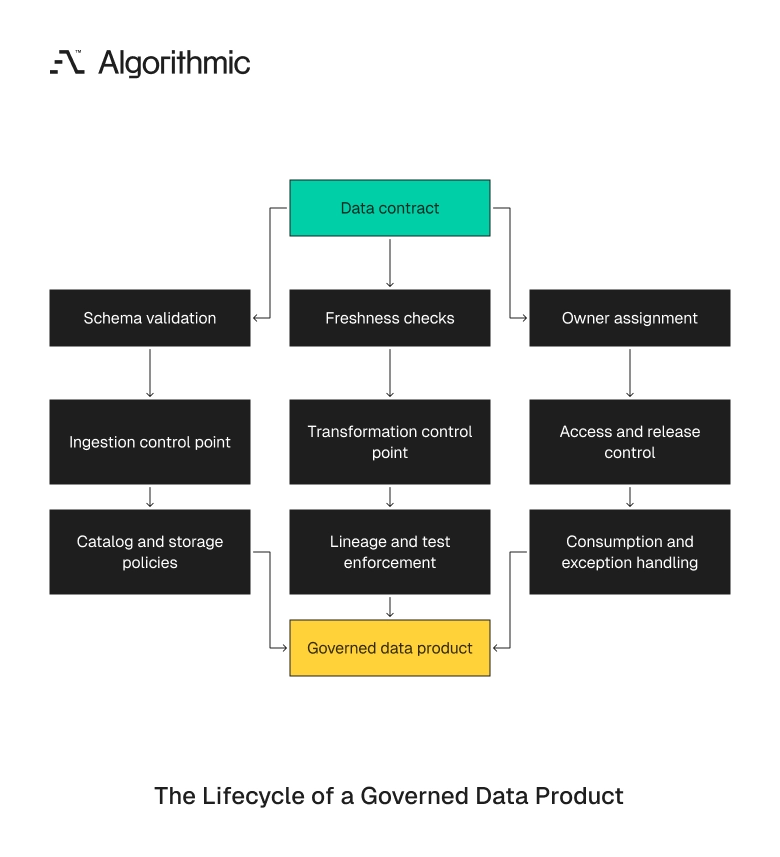
Enforce governance through contracts and control points
Governance fails when it is treated as a catalog project after ingestion. Governance must be engineered into data contracts, access policies, transformation tests, lineage tracking, and release processes.
A data contract defines the schema, semantics, freshness, quality checks, and owner for a dataset. It creates an interface between producers and consumers.
The contract can be enforced through schema registries, CI tests, dbt checks, table constraints, or catalog policies. The enforcement point should sit where the breakage starts.
The LatentView comparison of data warehouses and data lakes frames the decision around how enterprises turn data into decisions, accountability, and action. That framing is useful because governance is an accountability design embedded in the operating model.
Governance control points should be explicit:
- At ingestion: schema validation, PII tagging, and event contract checks.
- At storage: encryption, lifecycle policy, table permissions, and retention rules.
- At transformation: dbt tests, lineage capture, owner approval, and semantic definitions.
- At consumption: row-level security, masking, audit logging, and usage monitoring.
- At release: versioning, change notices, rollback plans, and incident ownership.
 Click to expand
Click to expand A warehouse supports strong governance if data arrives clean and ownership is clear. A lakehouse supports strong governance if table formats, catalogs, and policy engines are configured with discipline. A data lake without control points becomes a storage account with unclear trust boundaries. It also becomes a place where sensitive fields spread faster than the security team can classify them.
Governance also needs exception handling. A research team needs temporary access to raw events for model development. That access should have an owner, an expiration date, an audit trail, and a documented business purpose. The approval record should reference the project, data classes, and retention period.
The same rule applies to production break-glass access. Emergency permissions should expire automatically and create a review record. Without that process, temporary access becomes permanent access within one quarter. The platform then accumulates privilege through exceptions instead of design.
Governance should also cover deletion and retention. Customer deletion requests, contract retention rules, and regulatory holds need defined paths through raw, curated, and serving zones. A platform that cannot trace data copies cannot satisfy deletion obligations with confidence. That weakness becomes expensive during security reviews, enterprise sales cycles, and audits.
Governance should also include metric certification. A certified metric should have an owner, definition, lineage record, test coverage, and approved consumption paths. Uncertified metrics can still exist for research and local analysis. They should not feed executive reporting, sales compensation, regulatory reports, or customer-facing commitments.
A decision matrix for warehouse, lake, lakehouse, and hybrid patterns
The following matrix gives leaders a practical starting point. It should be calibrated with actual workloads, team skills, and commercial constraints.
| Pattern | Strong fit | Weak fit | Operating requirement |
|---|---|---|---|
| Data warehouse | BI, finance reporting, governed SQL analytics | Raw unstructured data, large-scale feature engineering | Analytics engineering, semantic modeling, cost controls |
| Data lake | Raw retention, exploratory ML, lower storage cost | High-trust dashboards without curation | Catalog, lifecycle policy, ownership model |
| Lakehouse | Mixed SQL and ML workloads on open storage | Teams without platform engineering depth | Table format discipline, catalog governance, engine selection |
| Hybrid | Enterprises with distinct analytics, ML, and operational workloads | Organizations seeking one tool for all use cases | Clear boundaries, integration contracts, cost governance |
Hybrid architectures are common for mature organizations. A warehouse often serves governed business intelligence. A lakehouse often serves feature engineering and large-scale batch processing. Kafka and Flink often support operational events.
The design risk sits at the seams. Duplicate transformations, inconsistent customer identifiers, and unclear ownership erode trust faster than any single tool limitation. A customer identifier illustrates the issue. Sales uses Salesforce account IDs, the product uses workspace IDs, and billing uses Stripe customer IDs.
Without a governed mapping, every downstream team creates its own join logic. Each version then produces a different customer count. That duplication becomes expensive during incidents. When revenue differs between the executive dashboard and the finance export, engineers must trace definitions across pipelines.
The remediation work often consumes more time than the original platform build. It also pulls senior engineers away from product delivery. The decision matrix should therefore include seam design. Each boundary needs an owner, a data contract, an integration pattern, and a failure policy.
For example, the boundary between Kafka and the warehouse should define event schema rules, replay behavior, ordering guarantees, and late-arriving event handling. The boundary between the lakehouse and BI layer should define curated tables, semantic metrics, and access rules. Seam design should also include reconciliation rules. If the warehouse and lakehouse both store customer activity, one system must serve as the source for certified reporting.
The other system can support research, feature generation, or operational access. The architecture record should state that division in plain language.
Procurement discipline means avoiding paying twice for the same layer
Procurement teams should examine overlap across ingestion, orchestration, transformation, catalog, governance, observability, and compute. Vendor proposals often bundle adjacent features that already exist elsewhere in the stack.
A one-platform story deserves careful review. The selection team should ask whether components can be replaced independently. It should also verify whether data remains accessible through open formats. Workloads should move without a multi-quarter migration when the commercial terms change.
Prefer replaceable components where possible. Libraries, open formats, and narrow services preserve optionality. Opinionated platforms can be the right choice when they reduce operational burden enough to justify lock-in and cost. The justification should appear in the architecture record, not only in the business case.
A serious evaluation includes exit cost. If leaving a vendor requires rewriting 400 pipelines, retraining 60 analysts, and exporting 500 TB from a proprietary format, the commercial risk belongs in the decision record. Procurement should require a feature overlap map. The map should identify which tool handles ingestion, transformation, scheduling, metadata, permissions, observability, and serving.
Each layer should have one accountable system unless the architecture record states a reason. Duplicate systems need explicit boundaries and cost owners. Contract terms should match workload reality. A three-year commitment can make sense after query patterns, growth rates, and staffing plans are documented.
The same commitment creates risk when it precedes workload segmentation and cost modeling. Cloud credits cannot compensate for the wrong operating model. Procurement should also ask for workload-specific pricing. BI dashboards, Spark jobs, streaming pipelines, and model training runs should have separate cost views.
A blended monthly estimate hides the workloads that will drive the renewal. The strongest negotiation position comes from measured demand, clear alternatives, and known exit cost. Procurement should also review support terms by workload. A finance platform with month-end obligations needs different escalation rights from an exploratory research environment.
Security terms deserve the same discipline. The contract should define audit support, data residency, breach notification, encryption controls, and subcontractor access.
The 30-day architecture process before vendor selection
A disciplined architecture process can run in 30 days before a major RFP or proof of concept. It reduces vendor bias and gives procurement a sharper basis for negotiation.
Days 1 to 5: Should cover inventory decisions and workloads. Capture the highest-value business and technical decisions the platform must support. Group workloads by latency, reliability, and consumption pattern.
Days 6 to 10: Should include mapping ownership and contracts. Assign owners to critical datasets. Define data contracts for the highest-value events, tables, and derived models.
Days 11 to 15: The team must build the cost model which should cover estimating storage, scan volume, compute concurrency, orchestration frequency, and data movement. Include current spend and projected spend at 12, 24, and 36 months.
Days 16 to 20: You must define governance control points. Decide where PII tagging, masking, lineage, quality tests, and approval workflows occur. Tie each control to a named system and owner.
Days 21 to 25: You must compare architecture patterns. Evaluate warehouse, lake, lakehouse, and hybrid options against the same workload and ownership model. Record tradeoffs in architecture decision records.
Days 26 to 30: You must run a narrow proof of concept. Test representative workloads such as month-end revenue reporting, churn feature generation, and near-real-time event processing. Measure latency, cost, operational burden, and developer workflow.
This process creates a defensible platform decision. It also gives procurement concrete negotiation points: committed usage, redundant features, data portability, support requirements, and migration risk. The final architecture record should fit on 10 to 15 pages. It should include the decision inventory, workload segmentation, ownership map, cost model, governance control points, and vendor comparison.
It should also state which workloads sit outside the platform boundary. Payment authorization, user-facing recommendation serving, and high-frequency operational decisions often belong in product systems. The architecture record should include one page for executive decisions. That page should state the selected pattern, expected annual cost, main risks, owner assignments, and renewal triggers.
It should also include a one-page rejection log. The log should explain why the team rejected other patterns, which assumptions would change that decision, and which workloads need review later. Select the platform after those artifacts exist. Assemble the inventory this week, assign owners by Friday, and build the first cost model from actual query logs.
Then use those artifacts in every vendor conversation, architecture review, and procurement decision. A warehouse, lake, lakehouse, or hybrid pattern should follow the operating model, cost profile, and production obligations the organization has already documented. Teams already running a warehouse and facing cost growth should read our guide on how to reduce data warehouse costs with workload-level attribution.
Algorithmic runs data infrastructure and integration engagements that start with the operating model, not the vendor. If your team is facing a platform decision or a renewal review, start a conversation.


