
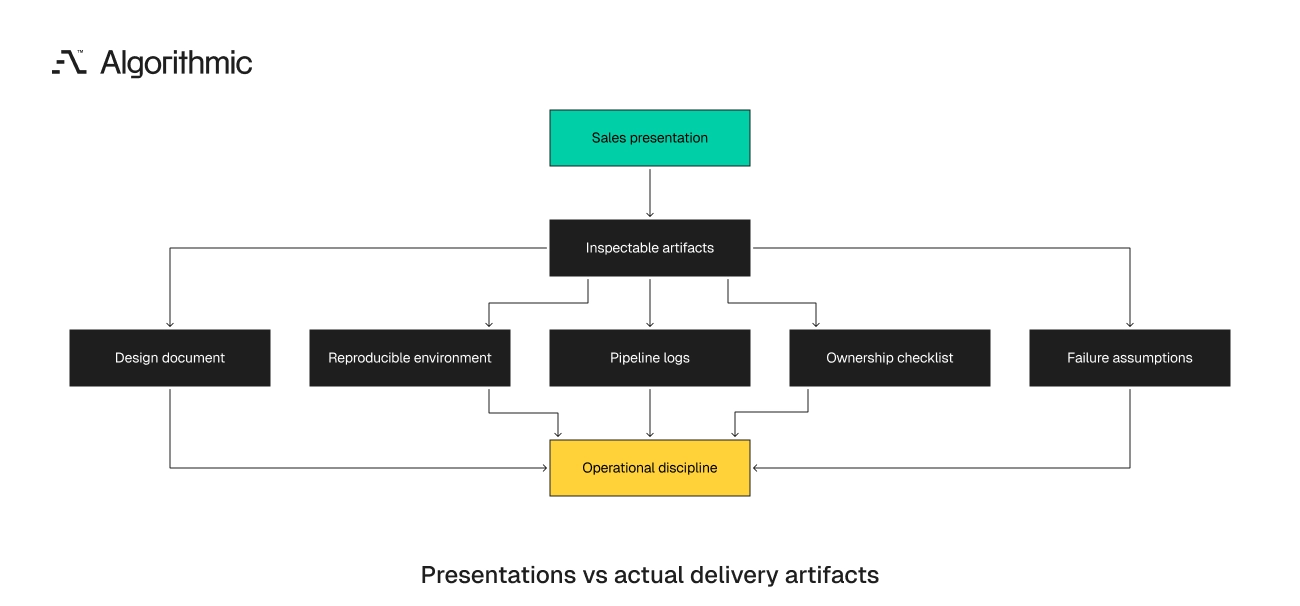
A $50K product build can lose 6 to 10 weeks when artifact gaps surface after kickoff. Common gaps include missing design history, no reproducible environment, no pipeline evidence, and unclear ownership. Those gaps convert a contained build into a recovery project. The outcome often starts during partner selection. The buyer reviewed presentations, timeline confidence, case studies, and executive presence. Those signals show sales discipline and provide weak evidence of engineering discipline.
Engineering partners should be judged by inspectable artifacts before contract signature. A senior software development team can show how it thinks, builds, tests, deploys, and transfers ownership before writing production code. The artifact trail gives the buyer evidence that survives the sales process.
Presentations state intent while artifacts show operating discipline
A sales deck can show sector experience, team structure, delivery phases, and staffing plans. Those items matter during procurement. They answer procurement questions more directly than operational questions. The operational test is specific. The buyer needs evidence that the team can work without constant verbal coordination. That evidence must exist outside workshops, Slack threads, and executive readouts.
A strong partner produces artifacts that survive outside a meeting. Design documents explain tradeoffs, and environment setup instructions reproduce the system on a clean machine.
 Click to expand
Click to expand CI/CD logs show the test suite running under version control. Architecture decision records show when the team chose PostgreSQL over DynamoDB. They also record Redis over an in-process cache, or a modular monolith over services. Those records matter when the product enters maintenance. Six months after launch, the client needs decision history more than polished kickoff slides. Maintenance work depends on knowing why the system was built in its current form.
Incident assumptions also matter, since they show what the team expects to fail, how it will detect failure, and when redesign starts. They expose whether the partner treats production as an engineering responsibility. Several partner evaluation guides focus on accountability, scope control, and vendor behavior. The next step is to request artifacts that make accountability inspectable.
This distinction becomes sharper in remote-heavy delivery. A team that depends on live explanation for every decision will struggle across time zones, staff changes, and post-launch maintenance. A team that writes durable artifacts can onboard engineers, brief executives, and transfer systems with less context loss. The same test applies to nearshore, offshore, and domestic teams. Distance changes meeting cadence, but it does not change the need for written engineering evidence.
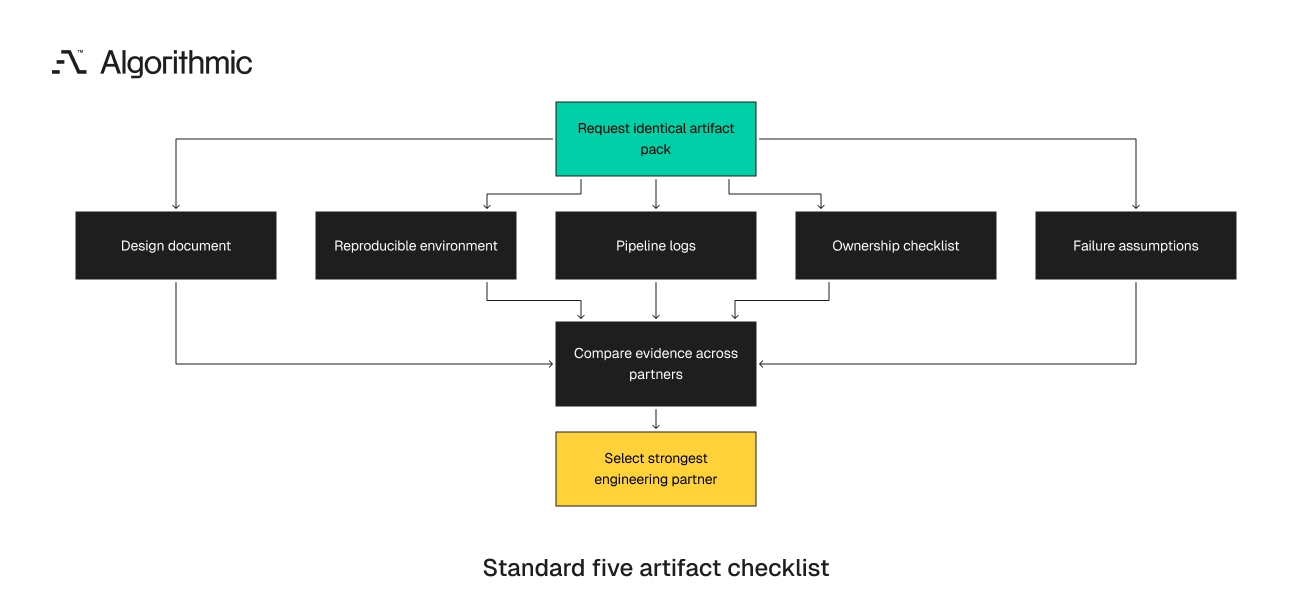
The pre-contract artifact set should contain five items
Before signing, the buyer should request evidence of how the partner creates artifacts with incomplete information. The partner has received limited context. That constraint is useful because production work always starts with unknowns. Ask each shortlisted partner for a small discovery artifact pack. It can be paid or unpaid, depending on project size and procurement rules. Limit the exercise to 3 to 5 business days.
The output should fit in a repository, a shared workspace, and a short readout. A 200-slide presentation is a warning sign. The buyer needs artifacts that an engineer can inspect, run, and challenge. The request should be identical for every shortlisted team. Identical inputs create comparable outputs. Procurement teams can then compare evidence instead of presentation style.
A consistent request also reduces post-selection disputes. If three partners receive the same context, differences in output quality become visible. The buyer can defend the decision with evidence instead of preference.
 Click to expand
Click to expand 1. A design document with explicit tradeoffs
A design document should state the target architecture, data model assumptions, API boundaries, and open decisions. It should name technologies where appropriate. Examples include PostgreSQL, Redis, S3, Terraform, and GitHub Actions. PostgreSQL may handle transactional storage. Redis may handle cached reads and rate-limited workflows. S3 may handle object storage, while Terraform records infrastructure changes under version control.
Low-quality design documents describe features. High-quality design documents explain the selected path, rejected options, and evidence that changes the decision. The difference is visible in one page. For a marketplace platform development project, the document should cover payments, identity, search, and notifications. It should state where those functions live in the first release. It should also explain how the team will move boundaries later if volume or ownership changes.
The document should identify the first scaling pressure. That pressure can come from database reads, background jobs, third-party payment callbacks, or search indexing. Each pressure leads to different tests and architecture decisions. A senior team will state deferred decisions with dates and triggers. For example: “Keep search in PostgreSQL until catalog size reaches 250,000 active records.” Add the second trigger: “Move earlier if p95 search latency exceeds 500 milliseconds.”
That pair of thresholds gives the buyer an engineering standard. It also prevents a vague debate about whether search should move to OpenSearch, Meilisearch, or Algolia. The team can test the current design against a stated boundary. The document should also expose data ownership. If orders, payments, invoices, and refunds share tables without a clear boundary, billing changes become expensive. If the design separates them early, the buyer gains room to adjust pricing and accounting rules.
A design document should also identify security boundaries. For example, tenant data should have a defined access path. Role checks should live in a policy layer, service layer, or database row-level security model. The reviewer should see where personal data enters the system. The document should name encryption points, retention rules, and audit log events. These decisions affect cost, compliance review, and incident response.
2. A reproducible development environment
A reproducible environment proves that the partner treats onboarding as engineering work. It should include a README, pinned runtime versions, local secrets guidance, database migration steps, and one command path for tests. The setup should work without private messages or undocumented credentials. Acceptable examples include Docker Compose for local services and mise or asdf for language versions. Strong examples include pnpm or uv lockfiles. Seed data should create known test states.
Seed data should cover standard users, edge cases, and permission boundaries. A B2B product should include an owner, admin, billing user, suspended user, and invited user. Those states reveal gaps in authorization and workflow design. The test is direct, since a new engineer should reach a working local environment in under 60 minutes on a clean laptop. The reviewer should time the setup and record every undocumented step.
This artifact exposes hidden process debt. If setup requires undocumented Slack messages, personal credentials, or private knowledge, the buyer inherits that fragility after launch. The first internal engineer will lose days reconstructing basic context. Environment quality also predicts handoff quality. Internal engineers cannot maintain a system they cannot run. A working local setup reduces dependency on the original vendor during the first 30 days after transfer.
The environment should include failure paths, in addition to the happy path. A billing service should include test cards, failed payments, webhook replay, and subscription cancellation states. A workflow product should include expired invites, revoked access, and partially completed approvals. A reproducible environment should also document external services. Stripe, Auth0, SendGrid, Twilio, and Sentry each require test credentials and configuration. The buyer should know which accounts exist and who controls them.
The environment should document local data reset. Engineers need a safe way to rebuild the database, reload seed data, and rerun migrations. Without this path, debugging becomes a manual process with inconsistent results.
3. Pipeline logs and release evidence
Pipeline logs show whether the team treats integration as daily engineering work. Ask for recent anonymized logs from GitHub Actions, GitLab CI, CircleCI, Buildkite, or Azure DevOps. The logs should come from a project with similar production demands. The logs should show linting, unit tests, integration tests, static analysis, build artifacts, deployment gates, and rollback steps. A screenshot of a green build is insufficient. The buyer needs raw evidence that ties code changes to test and release events.
The buyer should see commit hashes, timestamps, job names, failure history, and remediation patterns. Failure history matters because mature teams fix failed builds quickly and leave evidence. A failed build with a clear fix teaches more than ten polished screenshots. BlueOptima’s Q1 2026 Global Benchmark Report found throughput gains paired with lower maintainability in some segments. Those findings make release evidence more important during partner selection.
The implication for buyers is direct. Faster output without inspectable quality gates creates downstream cost. A buyer should verify release discipline before code volume increases. Pipeline evidence should include a recent failed build. A permanently green history often points to shallow testing, hidden manual steps, or selected screenshots. Production systems fail during integration, and the record should show how the team responds.
The pipeline should also show the deployment path. Reviewers should see how code moves from branch to staging to production. They should also see who approves the release and how rollback works when a migration fails. A release record should include version tags and deployment timestamps. It should show whether deployments are repeatable or performed through manual console changes. Manual release work creates risk during staff changes and incident response.
The reviewer should inspect test categories, not only total test count. Ten integration tests around billing can carry more value than 300 shallow component tests. The pipeline should show tests tied to business risk. Security checks belong in the pipeline as well. Examples include dependency scanning, secret detection, container image scanning, and static analysis. The buyer should see which failures block release and which failures generate warnings.
4. An ownership checklist
An ownership checklist describes who owns architecture decisions, environments, code review, security, release approvals, incident response, and documentation. It should include names or roles, decision rights, and handoff timing. It should also state which accounts the client owns on day one. This artifact prevents a common failure in MVP development to production. The client receives source code without operational control. That transfer leaves the client dependent on the partner for releases and incidents.
A repository transfer is incomplete without cloud access, runbooks, monitoring dashboards, secrets rotation procedures, and deployment permissions. The buyer should see those items before contract signature. Missing access becomes a commercial issue after the system has users.
A useful ownership checklist includes at least these items:
- Repository access and branch protection rules
- Cloud account ownership and billing control
- Infrastructure as code state location
- Secrets manager location and rotation process
- CI/CD permissions and deployment approval path
- Monitoring dashboards and alert recipients
- Production incident runbook
- Architecture decision records
- Data backup and restore test results
- Third-party vendor account ownership
The checklist should also define the handoff sequence. Cloud billing should move before launch. Secrets rotation should occur after transfer. Production access should follow the client’s access policy. If the client uses Okta, Azure AD, or Google Workspace, production access should align with that identity model. Shared accounts should be eliminated before launch.
Ownership also includes decision history. A client-owned repository without architecture records still leaves the client dependent on vendor memory. The checklist should state where architecture decision records live and how new decisions are added. The checklist should name operational contacts by role. For example, the client product owner may approve scope changes, while the partner engineering lead approves release readiness. The client security owner may approve production access.
Financial control belongs in the checklist as well. AWS, Azure, GCP, Vercel, Stripe, Datadog, and Sentry accounts affect cost and operations. The client should own billing authority before production traffic starts.
5. Failure assumptions and test plan
Senior engineers state assumptions, and they also state how those assumptions will be tested. That discipline separates engineering judgment from optimistic planning. A partner should be able to say: “We are assuming search traffic stays below 100 requests per second during the first release.” It should add: “We will load test the API at 3x that level before launch.” That statement carries more weight than a project plan with 40 generic tasks.
Failure assumptions should cover performance, data integrity, security, external APIs, user behavior, and operational ownership. They should also name the failure threshold that triggers redesign. Each threshold should connect to a test, metric, or release gate. For example, a billing workflow should test Stripe webhook replay, duplicate events, failed payments, and delayed subscription updates. A healthcare workflow should test audit logs, data retention, access revocation, and encrypted field handling. A logistics workflow should test delayed carrier updates, duplicate tracking events, and partial shipment states.
A team that cannot state failure assumptions before kickoff will discover them in production. The buyer will then pay for rework during the most expensive phase of the project. That rework often lands during launch, when executives expect user growth and customer feedback. The failure plan should include operational response. The buyer should know who receives alerts, who can pause releases, and who communicates with customers. Production readiness includes technical detection and management response.
The plan should define severity levels. A payment capture failure deserves a different response than a delayed notification. A production runbook should state response time, escalation path, and customer communication rules for each severity level. The plan should also state recovery tests. Backups matter after restore has been tested. The buyer should ask when the last restore test ran and who verified the result.
Artifact review matrix for selecting an engineering partner
Use a structured review, because it reduces the influence of presentation style and makes procurement decisions easier to defend. It also gives the buyer a consistent record when commercial proposals differ by rate, geography, or staffing model.
| Artifact | Strong signal | Weak signal | Buyer action |
|---|---|---|---|
| Design document | Names tradeoffs, rejected options, open risks, and test evidence | Describes features without architecture decisions | Ask for one rewritten section before selection |
| Development environment | Runs from documented steps in under 60 minutes | Requires live help, private knowledge, or manual database edits | Treat as a delivery risk |
| Pipeline logs | Shows tests, builds, failures, fixes, and deployment gates | Shows static screenshots or no failure history | Request raw logs from a recent project |
| Ownership checklist | Defines access, runbooks, billing, monitoring, and handoff timing | Treats handoff as a final meeting | Add ownership terms to the contract |
| Failure assumptions | States thresholds, tests, and redesign triggers | Presents estimates as facts | Require assumption log before kickoff |
This matrix works for software development for non-technical founders and for enterprise buyers with formal procurement processes. It helps CTOs compare a boutique software studio, an offshore team, and an internal staff augmentation proposal on the same evidence base. That evidence base matters when teams look similar on paper. Guides such as Technology Partner Evaluation Guide for 2026 Success address partner selection at a broad level. The matrix above narrows the review to proof that a team can build and operate production-ready software under real constraints. It turns general diligence into a repeatable engineering review.
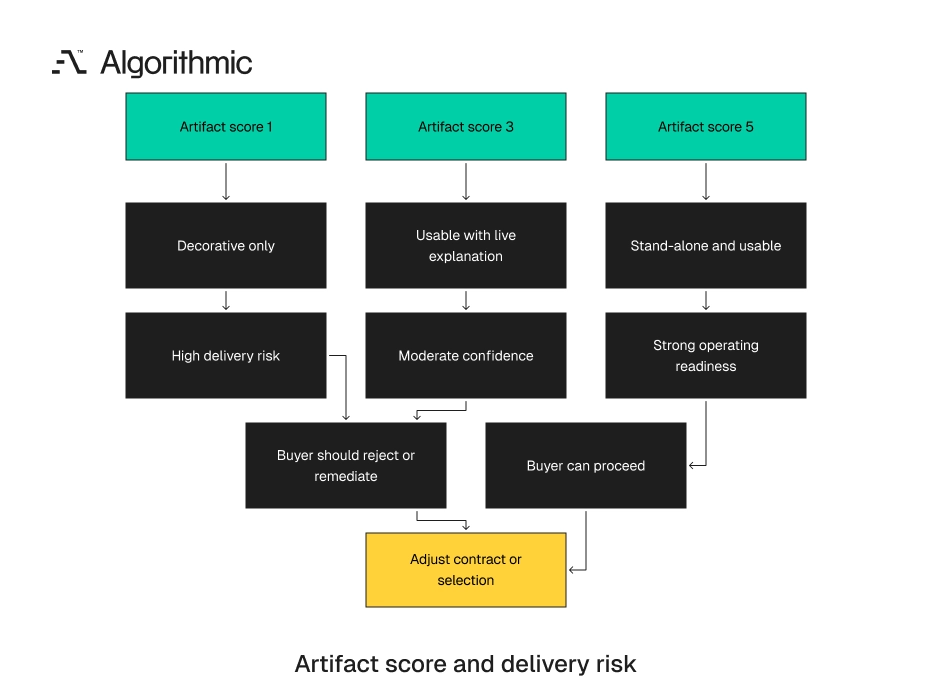
The matrix also creates a written decision trail. A CFO can understand why one proposal with a lower rate carries higher delivery risk. A CTO can explain why artifact maturity carries more weight than a polished workshop. The scoring process should stay simple. Rate each artifact from 1 to 5, record the evidence, and note the business risk. A one-page scoring memo is enough for most $50K to $250K product builds.
A score of 1 means the artifact exists for appearance. It cannot guide a new engineer. A score of 3 means the artifact is usable with live explanation. A score of 5 means the artifact stands on its own. A new engineer can act from it without asking the original author for context. That standard protects the buyer after staff changes, vendor rotation, and product growth.
 Click to expand
Click to expand The review should include at least one engineer and one commercial owner. The engineer evaluates technical evidence. The commercial owner connects gaps to budget, timeline, support cost, and contract terms.
Artifact quality predicts performance under ambiguity
Complex product builds contain incomplete information at kickoff. The buyer may lack final requirements. The market may change during the build. Third-party APIs may behave differently from documentation. Compliance requirements may become clearer after legal review. Customer workflows may expose edge cases that no workshop covered.
Artifact quality shows how a team handles uncertainty. The artifact trail reveals whether the team converts unknowns into engineering work. It also shows whether the team records decisions before memory becomes the project archive. A junior process converts uncertainty into optimistic tasks. A senior process converts uncertainty into assumptions, experiments, and decision records. That difference becomes visible in the first week.
For a SaaS product development project, a senior team separates known scope from discovery scope. Authentication, billing, tenancy, and audit logs can be specified early. Recommendation logic, workflow automation, and pricing experiments often need measured iteration. The 2026 Plandek Engineering Productivity Benchmarks analyzed delivery data from more than 2,000 software engineering teams. The report found that AI tools increased coding speed for many developers while delivery predictability varied by team. That finding changes how buyers should inspect partner work.
The buyer’s conclusion is practical. Code generation tools raise output volume, so artifact review becomes more important. Reviewers need evidence of architecture control before generated code enters the main branch. A partner using AI coding tools without design discipline can produce more code than the client can safely inspect. A partner with architecture decision records, test gates, and reproducible environments can use AI tools inside a controlled engineering process. The second pattern leaves a trail that reviewers can audit.
This matters for review workload. A small client team can inspect five design decisions and ten pipeline runs. It cannot inspect 80,000 generated lines after the architecture has already drifted. Artifact quality also predicts how the team handles product changes. A documented API boundary makes a pricing change contained. An undocumented boundary turns the same change into a multi-week search through controllers, jobs, and database migrations.
The same principle applies to security changes. If access rules live in one policy layer, a new enterprise role can be added with bounded risk. If authorization checks are scattered across views and background jobs, every release becomes a manual audit. Ambiguity also appears in customer data. A workflow may support three approval states during design and nine states after customer interviews. A clean state model absorbs that change better than scattered conditionals.
The artifact record should show how the team changes its mind. A decision log that records rejected options is a sign of disciplined learning. A silent rewrite is a sign that project memory is held by individuals.
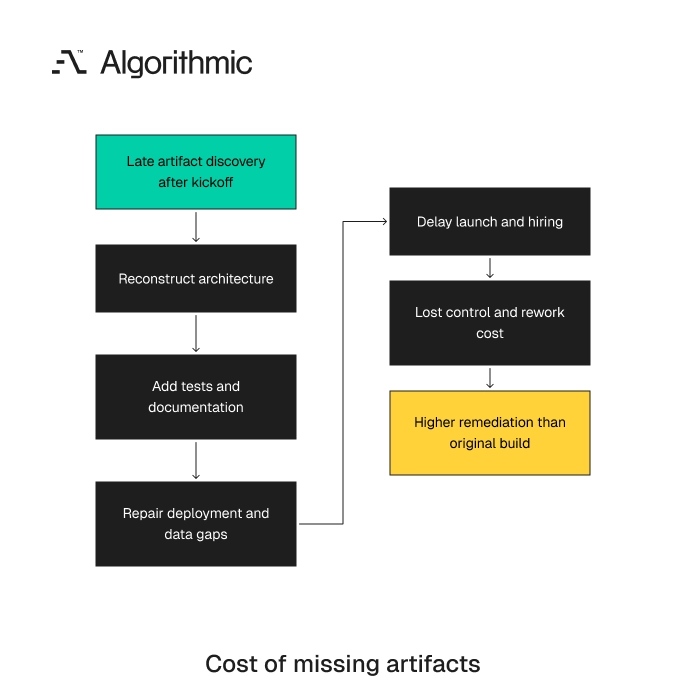
The cost of late discovery is measured in rework and lost control
The most expensive partner failures often surface after enough code exists to create switching cost. At that point, the buyer faces three unattractive options. Continue with weak process, pause for remediation, or hire a new team to assess the codebase. Industry hiring data puts US senior developers at $120K to $200K in base salary, 8 to 12 weeks to hire, and 1.5x to 2x annual salary for an unsuccessful hire. Those numbers create a useful reference point for external partner risk.
A $50K build with weak artifacts can create a larger remediation bill than the original contract. A rescue team may need 2 to 4 weeks to reconstruct architecture, document deployment, add tests, repair data migrations, and identify security gaps. That review often starts before any new feature work can resume.
 Click to expand
Click to expand That work delays market release. It also consumes the attention of the founder, CTO, product owner, and finance lead. Those hours rarely appear in the vendor invoice, but they are real costs. The risk increases when the client plans to hire internal engineers after launch. New employees need code history, environment setup, runbooks, and decision records. Without those artifacts, onboarding becomes reverse engineering.
Reverse engineering also weakens retention. Senior internal engineers will not stay long when their first month is spent recovering basic delivery history from commit messages and Slack threads. A poor artifact trail turns a promising hire into a recovery lead. Industry guides on evaluating development firms correctly warn buyers about proposal similarities. Artifact review gives those warnings an operating test. It separates firms that sell process from firms that record engineering work.
Late discovery also reduces negotiation power. Before signature, the buyer can require stronger artifacts, clearer access terms, and tighter acceptance standards. After kickoff, every missing artifact becomes a schedule discussion. Late discovery also changes the emotional temperature of the project. A missing runbook before signature is a solvable procurement issue. A missing runbook during a production incident becomes an executive escalation.
The same pattern appears in data migrations. A partner can document migration assumptions during discovery. If those assumptions surface after import failures, the client pays for cleanup, delay, and customer support. Security gaps follow the same cost curve. A missing threat model before contract signature can be addressed in scope. A missing threat model after an enterprise security review can block the first customer contract.
A five-day artifact review before signature
A serious buyer can run an artifact review in one work week. This process requires discipline and access to one senior reviewer. It does not require a full technical due diligence engagement. The reviewer should have production experience. A staff engineer, fractional CTO, or senior engineering manager can run the process. A product manager can coordinate it, but engineering judgment must lead the scoring.
The buyer should treat the review as a procurement gate. A partner that refuses to show artifact evidence before signature is asking the buyer to accept process risk without proof. That is a poor trade for any production system. The review does not need a large committee. One technical reviewer, one commercial decision maker, and one business owner are enough for most early builds. More reviewers often add delay without improving the signal.
Day 1 request the artifact pack
Send the same request to each shortlisted partner. Ask for a design sample, anonymized pipeline evidence, a reproducible environment example, an ownership checklist, and a failure assumption log. Give each partner the same deadline and format. Give the partner a narrow context if the project is new. For example: “We are building a B2B SaaS workflow tool with role-based access control, Stripe billing, PostgreSQL, and a React front end.” Add the request: “Show how your team would structure the first release.”
Set a clear response format. Ask for repository links, documents, screenshots as supporting material, and a 30-minute readout. The format reduces theater and increases comparability. The request should also state that the buyer will test the artifacts. This prevents the partner from sending decorative documentation. It also sets the expectation that engineering evidence will influence the final award.
The request should define confidentiality rules. Anonymized materials can remove client names, secrets, and proprietary logic. The remaining artifact should still show decision quality, pipeline shape, and ownership discipline. A partner should have an artifact pack ready within a few business days. A firm that builds production systems accumulates this evidence through normal work. It should not need to invent process during sales.
Days 2 and 3 test for reproducibility and specificity
Have a senior engineer review the artifacts. The reviewer should run the environment, inspect the design document, and read the pipeline logs. The review should produce written notes, not only a meeting summary. Score each artifact from 1 to 5. A score of 1 means the artifact is decorative. A score of 5 means a new engineer can act from it without live explanation.
Record evidence for every score. For example, “Local setup required undocumented database credentials” is stronger than “environment quality was poor.” A written scoring note supports the final vendor decision. The reviewer should also check internal consistency. The design document should match the pipeline, and the ownership checklist should match the deployment model. Mismatches reveal sales material assembled after the request.
The reviewer should ask one practical question for each mismatch. If the partner claims Terraform-managed infrastructure, the reviewer should ask where state lives and who owns it. If the partner claims automated deployment, the reviewer should ask for the last rollback record. The reviewer should also look for date freshness. A strong artifact pack includes recent material from current toolchains and delivery practices. A five-year-old sample shows history, not current operating discipline.
Specificity matters during this step. “We use automated testing” is weak evidence. “This GitHub Actions workflow runs 418 tests, blocks merge on failure, and deploys to staging after approval” is inspectable.
Day 4 run a 45-minute assumption review
Ask the partner to walk through the failure assumption log. The strongest answers will name uncertainty, define tests, and state what triggers an architecture change. The weakest answers will convert assumptions into assurances. Listen for precision, because “We will monitor performance” is weak. “We will load test checkout at 50 concurrent users and hold p95 latency under 400 milliseconds” is strong.
The buyer should ask who makes the redesign decision. Technical thresholds without decision rights create delay. A 15-minute approval path can save a week during the final release window. The reviewer should also ask for one past example. A senior partner can explain a production issue, the artifact that exposed it, and the change made afterward. The example should include a date, system type, failure mode, and correction.
The assumption review should end with a written risk note. That note should state which assumptions the partner handled well and which need contract language. This note becomes useful during statement-of-work negotiation. The meeting should also test executive communication. A senior engineering partner can explain risk without drama and without hiding uncertainty. The buyer should leave with clearer decisions, not a list of vague concerns.
The reviewer should document unanswered questions. Unanswered questions do not disqualify a partner when the partner states a test path and owner. They become risk when the partner treats uncertainty as settled fact.
Day 5 put artifact obligations into the contract
The contract should name artifacts as required work products. Include design documents, architecture decision records, CI/CD evidence, test coverage reports, deployment runbooks, monitoring dashboards, and ownership transfer steps. Treat those items as part of delivery, not administrative add-ons. Tie payment milestones to inspectable artifacts as well as feature completion. This protects both sides, since the client receives a system it can inherit, and the partner has clear evidence of completed engineering work.
The statement of work should define acceptance standards. For example, “Local setup must complete from documented steps in under 60 minutes” is measurable. “Documentation must be good” is not. The contract should also state where artifacts live. A client-owned GitHub organization, cloud account, and documentation workspace reduce transfer risk. Vendor-owned accounts create avoidable dependency.
Payment language should match the artifact review matrix. A milestone can require a passing pipeline, updated architecture records, tested deployment steps, and confirmed access transfer. That structure keeps engineering control visible through the project. The contract should include access timing. Repository ownership, cloud billing, monitoring access, and vendor account control should move on a defined schedule. The schedule should not wait until the final invoice.
Acceptance language should include test evidence. For example, a release milestone can require a passing pipeline, staging deployment, smoke test record, and rollback test. Those requirements create proof without adding bureaucracy. The contract should also state documentation ownership. Architecture records, runbooks, and environment instructions should be client property. They should remain available after the partner relationship ends.
What senior partners disclose early
Senior partners do not present every plan as certain. They disclose what they know, what they assume, and what they will test. They also explain which decisions deserve early commitment and which decisions require measured evidence. At Algorithmic, we have seen this pattern across 35+ complex full product builds, including platforms serving 14M+ end users with 0 production outages across delivered systems. The artifact trail is the operating system for production engineering.
For a full product build from scratch, early artifacts should show the path from concept to production. They should also show how the team preserves control of technical decisions. Architecture history matters when the product enters maintenance. For ML systems in production, the same principle applies to model training pipelines, feature stores, model versioning, drift detection, and inference monitoring. A model artifact without training history creates audit and rollback risk. A production model also needs clear ownership for retraining, evaluation, and incident response.
For data platform development, it applies to data lineage tracking, dbt transformations, data quality monitoring, and warehouse access controls. A dashboard without lineage forces analysts to trust outputs they cannot trace. A warehouse without access records turns every permission change into a security review. For mobile applications, the artifact set shifts again. The buyer should inspect build signing, release tracks, crash reporting, analytics events, privacy disclosures, and store submission history. App Store and Google Play release evidence matters because mobile rollback options differ from web deployments.
For embedded or IoT systems, artifact review should include firmware build steps, device logs, over-the-air update procedures, and hardware test records. A firmware defect can require field replacement if release controls are weak. That risk belongs in the pre-contract review. The specific artifact changes by discipline. The judgment standard remains the same: can another qualified engineer inspect the work, reproduce the result, and operate the system? If the answer is no, the buyer is purchasing dependence.
Senior partners also disclose constraints early. They name unavailable client decisions, third-party dependencies, security requirements, and data migration risks. They do this before those constraints become schedule pressure. They also disclose where client participation is required. Access to subject matter experts, legal review, security review, and payment account setup can block progress. A serious partner records these dependencies before the project plan becomes fiction.
Senior partners also show how they handle scope change. They connect each change to architecture, testing, release timing, and ownership. The client can then decide with a full view of cost and risk. The same discipline applies after launch. A production system needs alert review, dependency updates, backup tests, and release hygiene. Early artifacts should show whether the partner has designed for that operating model.
Direct action for the next partner selection
Before selecting a senior software development team, require a five-item artifact pack. The pack should include a design document, reproducible environment, pipeline logs, ownership checklist, and failure assumption log. Each item should be inspectable by an engineer before the final commercial discussion. Review those artifacts before the final pricing conversation. Score them in writing, and add artifact obligations to the statement of work and payment schedule.
Do not award a $50K product build on presentation confidence alone. Select the partner whose artifacts prove they can build, explain, transfer, and operate the system under production conditions. The best partner leaves the buyer with working software and the evidence needed to own it. Algorithmic delivers full product builds backed by the design records, pipeline logs, and rollback runbooks that prove production discipline. Bring us into your partner shortlist if you want an engineering team whose artifacts hold up before you sign.


