
College basketball occupies a unique position in the sports betting landscape. Over 350 Division I programmes, each with distinct playing styles, coaching philosophies, recruiting pipelines, and competitive contexts. Rosters turn over annually as players graduate, transfer, or declare for the draft. Conference realignment reshapes schedules and the tournament format - single elimination across 67 games in three weeks - amplifies variance in ways that regular season data cannot fully account for.
For bettors, this creates opportunities since the market is less efficient than professional leagues because the sheer volume of teams and the pace of roster change make it difficult for oddsmakers to maintain precision across every matchup. Information asymmetry exists across the landscape in a way it does not in a 30-team professional league. The difficulty is engineering that information into structured, actionable signal before the market absorbs it.
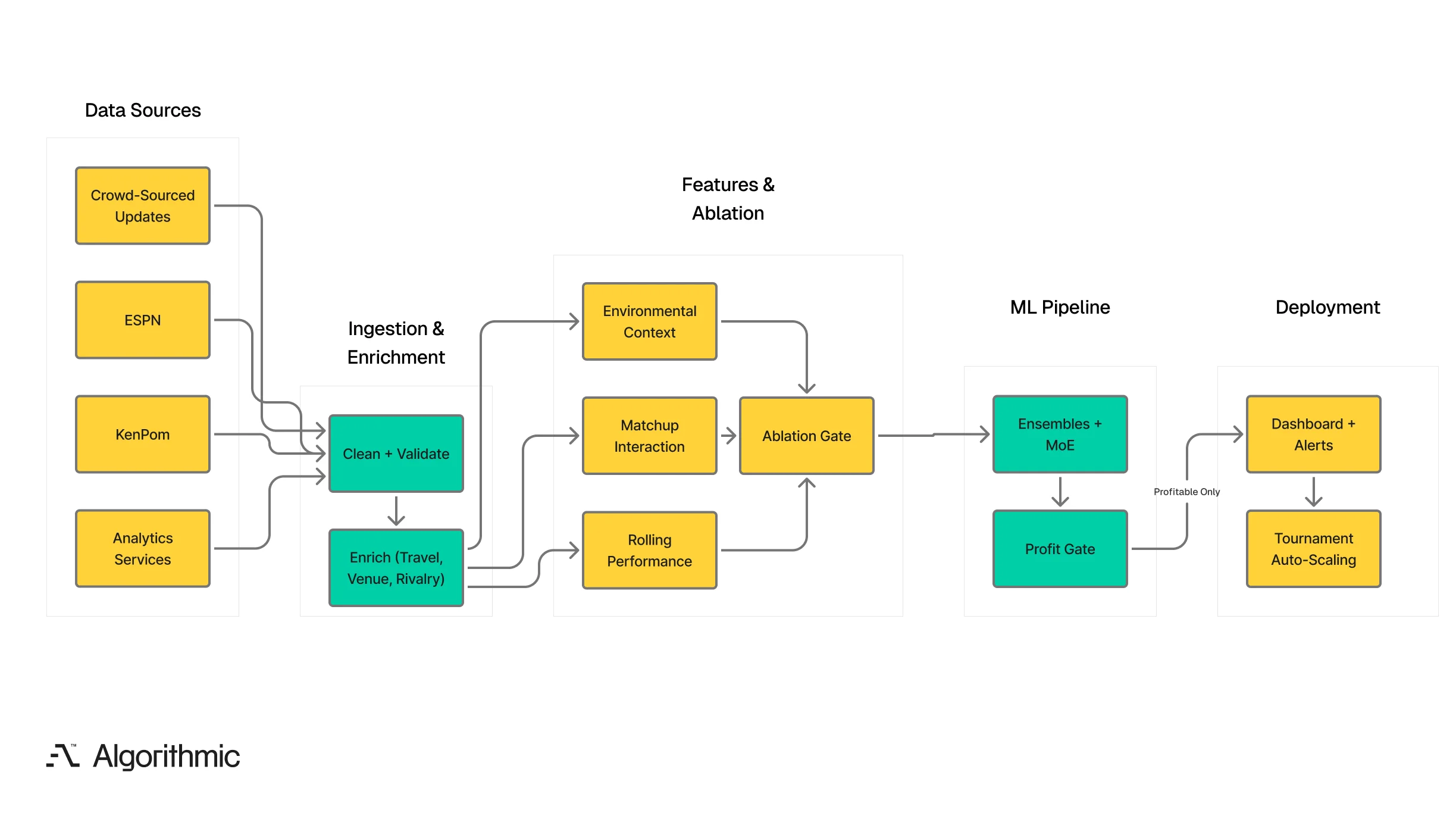
We built a predictive platform designed specifically for NCAA basketball’s constraints. The system ingests multi-source data in near real time, engineers features that capture context standard models miss - travel logistics, venue hostility, rivalry intensity, rolling form - and deploys models gated on profitability. The pipeline is modular, enabling the same architecture to adapt to other sports and non-sports prediction domains.
Why NCAA basketball requires a different approach
Three structural characteristics guided our architecture decisions.
Over 350 programmes means thousands of potential matchups, many between teams that have played each other once in the last three years - or never. We cannot rely on head-to-head history the way models can in a 30-team professional league with repeated matchups across an 82-game season. Our feature engineering compensates by modelling stylistic similarity, conference-level patterns, and transferable performance metrics.
College rosters change substantially every year. A team’s identity - offensive system, defensive tendencies, depth, chemistry - resets with each incoming class and each transfer portal cycle. Historical team-level statistics carry forward imperfectly. Our system adapts its understanding of each team’s current profile continuously through the season rather than relying on preseason projections or prior-year data.
Rivalry games, hostile home venues, and tournament elimination pressure produce performance variation that standard box score statistics cannot capture. A team that performs consistently in conference play may behave differently in a rivalry game with a hostile crowd or in a tournament game with single-elimination stakes. We dedicated specific feature engineering to these contextual signals.
The platform follows a modular pipeline from multi-source acquisition through ablation-tested feature engineering, profit-gated deployment, and tournament-scalable monitoring.
 Click to expand
Click to expand Data acquisition
We built a multi-source ingestion engine pulling from four source types:
- ESPN provides scores, schedules, and box score statistics as the structured baseline.
- KenPom delivers tempo-adjusted efficiency metrics that normalise team performance across different paces of play and strengths of schedule.
- Specialised analytics services contribute advanced statistical models and proprietary ratings.
- Crowd-sourced updates surface injury reports, transfer portal activity, and roster changes that formal channels report with delay.
The pipeline cleans and validates incoming data in near real time, stores structured records in PostgreSQL, and enriches every game record with three categories of contextual data. Travel logistics include distance between venues, direction of travel, time zone changes, and days since last game. A team flying east coast to west coast for a weeknight game faces a different physical and scheduling context than one playing a Saturday home game.
Venue attributes include capacity, altitude, surface type, and historical home-away performance differentials. We computed venue hostility scores using historical upset rates and home team performance margins by venue, not by team. Rivalry context includes historical series data, conference rivalries, tournament matchup history, and regional proximity. Rivalry intensity is quantified as a continuous feature, not a binary flag.
Feature engineering
We engineered features across three categories. Every feature went through ablation testing - if it improved accuracy but did not improve profitability against historical lines, we removed it. This discipline is critical since an accurate model that loses money against market odds is worse than no model.
Rolling performance indicators
We compute offensive and defensive efficiency, pace, and shooting metrics on configurable rolling windows - 5-game, 10-game, and 20-game. A team’s recent 5-game offensive efficiency provides more current signal than season-long averages, particularly during stretches where roster adjustments, injuries, or coaching changes alter team identity mid-season. We also track divergence between rolling metrics and season averages. A team whose 5-game efficiency is declining while the season average remains high carries elevated risk that surface-level statistics do not reflect.
Synergy and matchup scores
We model how two specific teams’ stylistic tendencies interact. Rather than using categorical labels, we quantify interactions as continuous scores across four dimensions:
- Tempo compatibility measures how two teams’ preferred paces of play combine to shape the likely game environment.
- Rebounding style interaction evaluates offensive versus defensive rebounding tendencies in the specific matchup context.
- Turnover tendency versus defensive pressure models how a team’s ball security holds up against the opposing defence’s forcing style.
- Three-point reliance versus perimeter defence quality assesses the vulnerability created when a shooting-dependent offence faces a strong perimeter defence.
Each dimension produces a continuous interaction score reflecting how two specific teams’ profiles combine - capturing matchup dynamics that aggregate statistics miss.
Environmental factors
We incorporate six contextual variables that capture performance variation invisible to standard box scores:
- Travel distance and direction weighted by recency and cumulative load over recent games.
- Altitude at the game venue, affecting late-game cardio performance.
- Venue hostility computed from historical upset rates and home team margins by specific venue.
- Days of rest between games, capturing both freshness advantage and rust risk.
- Rivalry intensity quantified from historical series data, conference context, and regional proximity.
- Tournament stage capturing the distinct performance patterns that emerge under single-elimination pressure.
Machine Learning pipeline
The modelling pipeline starts with a validated baseline and adds complexity only where it shows measurable value. This includes:
- Random forests established our performance baseline. Every subsequent model was benchmarked against this baseline with a requirement for statistically verifiable improvement in both prediction accuracy and profitability against historical betting lines. We do not deploy complexity without demonstrated value.
- Ensemble stacking combines gradient boosting and neural network models. The gradient boosting models handle the heterogeneous feature space effectively - continuous efficiency metrics alongside categorical conference labels alongside temporal rolling windows. Neural components capture nonlinear interaction effects between contextual features and performance metrics that tree-based methods miss.
- Mixture of Experts (MoE) deploys specialist models trained on different prediction targets - spread, over/under, moneyline. A gating network learns which specialist to weight more heavily based on each matchup’s characteristics. For a game with high travel load and rivalry intensity, the contextual specialist receives higher weighting. For a matchup between stylistic opposites, the synergy specialist dominates.
- Parallelised hyperparameter tuning runs across distributed compute infrastructure, evaluating thousands of configurations. The tuning process optimises against profitability metrics - configurations that produce double-digit ROI in backtests, not marginal accuracy improvements.
- Automated model selection gates all production deployments on dual thresholds. A model must show positive expected value against actual betting lines across a statistically significant sample on both accuracy and profitability dimensions before it reaches production.
Deployment and monitoring
Containerised architecture
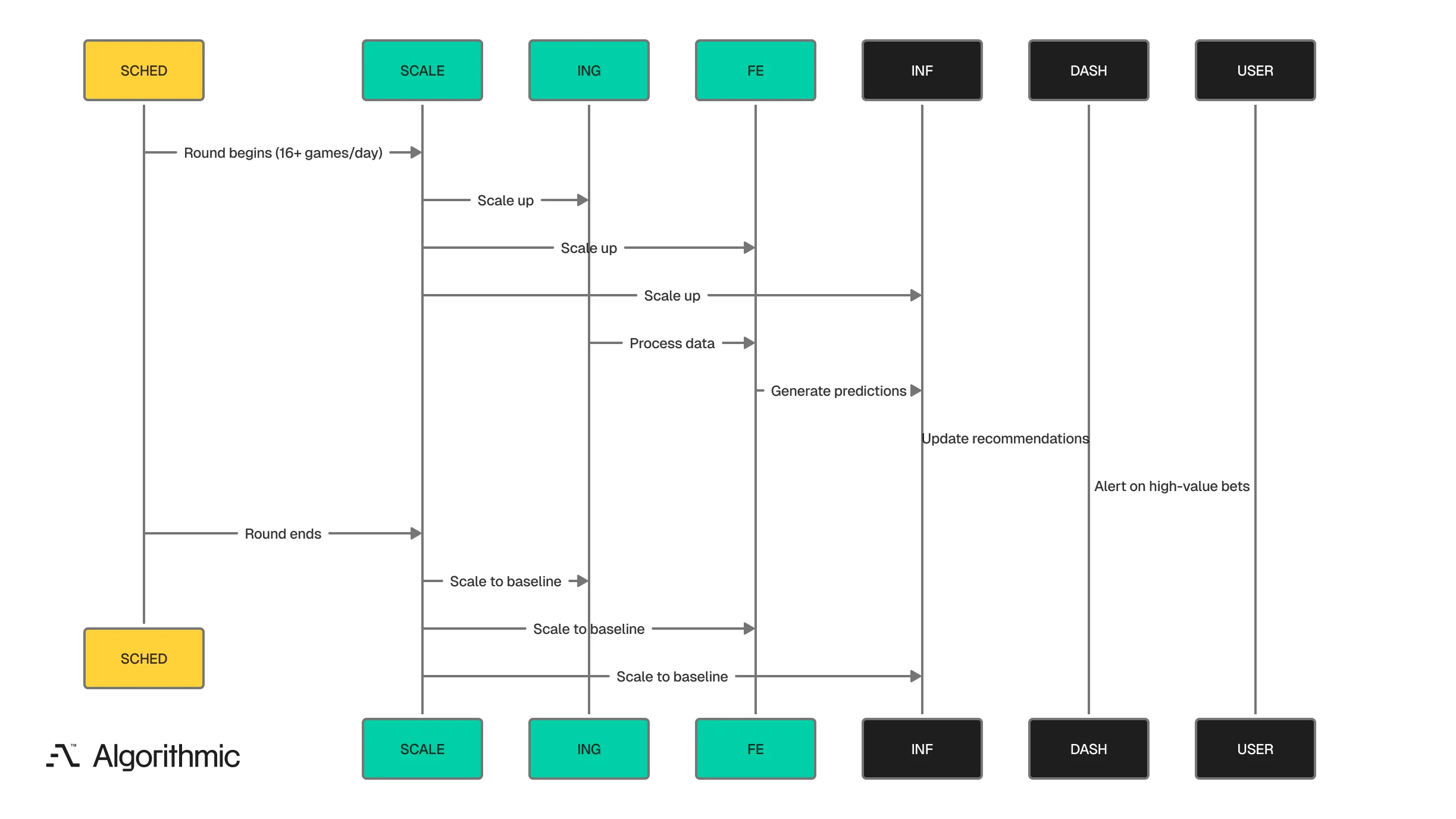
Each pipeline stage - ingestion, feature engineering, training, inference, dashboard serving - runs as an independent containerised service. We update, scale, and roll back any component without affecting the others. During tournament periods, inference capacity scales independently of training infrastructure.
Live dashboard
The dashboard provides three primary views for professional bettors:
- Profit over time as a line chart with configurable date ranges and segmentation by bet type, conference, and team. Cumulative profit curves show whether profitability is sustained or concentrated in narrow winning streaks.
- Bet distribution showing allocation across spread, moneyline, and over/under markets, with visibility into which market segments drive returns.
- Team-level drill-downs with per-team profitability, model confidence, and historical prediction accuracy. Consistently unprofitable teams or conferences are flagged for exclusion from the recommendation set.
Automated performance alerts
When profits drop below configurable thresholds, the system alerts operators and can automatically reduce exposure to underperforming segments. We calibrated these thresholds against historical variance patterns to distinguish normal fluctuation from genuine model degradation.
Tournament scalability
March Madness produces a volume spike - 67 games across three weeks, concentrated in intense multi-game days. Our cloud-native architecture scales compute resources automatically during tournament rounds and scales back when the round concludes.
March Madness produces 67 games across three weeks. The architecture scales compute automatically for tournament rounds and returns to baseline when each round concludes.
 Click to expand
Click to expand What we delivered
| Metric | Result |
|---|---|
| ROI | Double-digit returns in backtested and live environments |
| Feature discipline | Ablation-tested - only features improving both accuracy and profitability retained |
| Model selection | Automated - dual accuracy/profitability thresholds gating all production deployments |
| Architecture | Modular - each pipeline stage independently deployable and rollback-capable |
| Tournament handling | Cloud-native auto-scaling for March Madness demand spikes |
| Adaptability | Pipeline portable to NBA, MMA, soccer, and non-sports domains |
What this work represents
College basketball prediction sits at an intersection of sparse historical data, extreme team heterogeneity, and contextual factors that resist quantification. We built a system that handles all three - ingesting multi-source data continuously, engineering features that capture context standard models ignore, and deploying predictions gated on the only metric that matters, which is profitability.
The pipeline’s modular design means the architecture adapts to other prediction domains by swapping data sources and feature engineering while preserving the ingestion, training, deployment, and monitoring infrastructure. We have applied the same structural approach to NBA, MMA, and non-sports prediction problems.
We build prediction systems for domains where the market is efficient, the data is complex, and the success criterion is financial return. If that describes the problem you are solving, we should have a conversation.
This platform was delivered through Algorithmic’s predictive analytics and data infrastructure practices - the same engineering disciplines we apply across sports, finance, and demand forecasting domains.

