
Mixed martial arts is structurally difficult to model. In team sports, individual variance is dampened by roster depth and system play. In MMA, a single fighter carries the entire outcome. One undisclosed injury, one opponent substitution, one weight-cut complication can invalidate weeks of analytical preparation.
Most MMA betting models run on historical fight records - win-loss ratios, finishing rates, and broad stylistic categories. This data is publicly available, widely used, and already priced into the market before a bettor acts on it. The edge, if one exists, lives in data the market has not yet absorbed: last-minute roster changes, training camp intelligence, physical condition signals, and contextual factors - cage size, altitude, travel fatigue - that shape fight dynamics in ways fight records cannot capture.
We built a predictive betting platform purpose-built for MMA’s specific constraints. The system ingests multi-source data in real time, engineers features that capture fighter condition, stylistic matchup dynamics, and environmental context, and deploys machine learning models gated on profitability rather than accuracy alone. The result is a 10-20% lift in long-term ROI on managed betting portfolios.
Why MMA resists standard models
Three characteristics of MMA guided every architecture decision we made:
- Sparse career data. A professional MMA fighter competes two to four times per year. Over a career, that produces 20 to 40 data points - a fraction of the sample available for modelling a basketball player across 82 regular season games. Our models had to extract meaningful signal from limited fight-level data, which drove our choice of feature engineering strategies and model architectures.
- Late-breaking disruptions. Opponent substitutions, injury disclosures, and weight-cut failures frequently surface within 48 hours of an event. A model trained on the announced matchup becomes unreliable when the opponent changes. We designed our ingestion pipelines to detect and respond to these shifts faster than the betting market reprices.
- Stylistic interaction effects. Fight outcomes depend heavily on how two specific fighting styles interact. A striker facing a grappler produces a fundamentally different contest than two strikers. Historical records capture outcomes but miss the stylistic nuances that produced them. Our feature engineering models the matchup interaction - two fighter profiles combining to produce probabilities that differ from what individual profiles would predict independently.
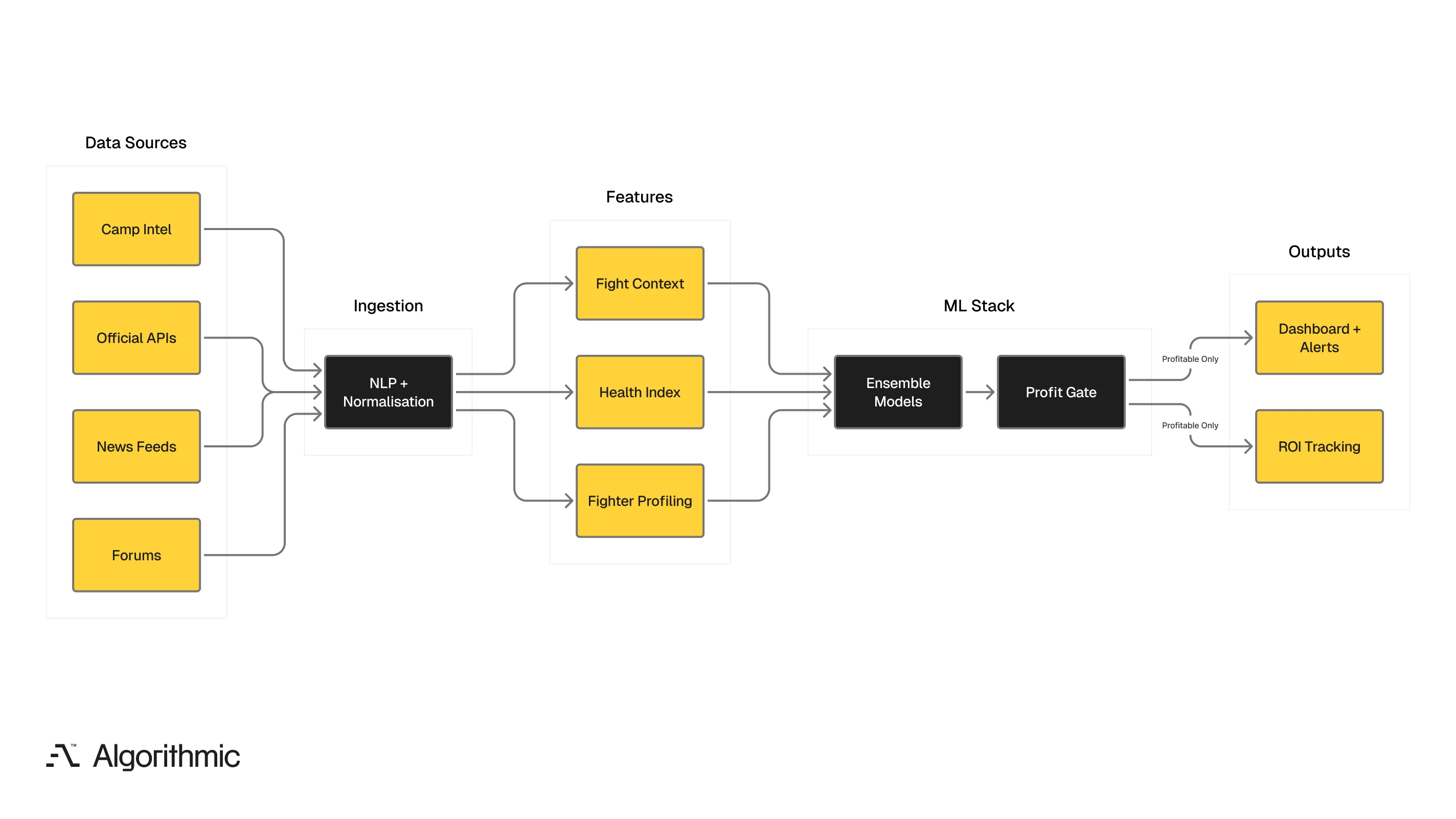
Data ingestion
We pull data from four distinct source categories, each contributing a different signal type that public fight statistics cannot provide. These included:
- Official fight data APIs deliver the structured baseline - results, round-by-round scoring, significant strike statistics, takedown rates, and control time. This data is necessary but insufficient alone, since it is publicly available and already reflected in market pricing.
- Sports news feeds provide reporting on injuries, training camp changes, coaching staff updates, and fighter statements. We built NLP extraction pipelines that pull structured signals from unstructured reporting - converting a news paragraph about a fighter’s knee rehab into a quantified injury recovery indicator.
- Fan forums and fight breakdowns contribute community-sourced intelligence. Training camp sparring reports, informal injury mentions, and detailed stylistic analysis from experienced observers carry signal that official channels miss. We validate and weight this data against historical accuracy before it influences model inputs.
- Insider camp updates surface information on fighter preparation - weight-cut progress, sparring performance, strategic adjustments - with direct predictive value for fight outcomes.
All four source types feed into a unified pipeline that normalises, deduplicates, and validates incoming data before the feature engineering layer touches it.
Feature engineering
We translate raw data into predictive signals across three domains. Each domain captures a dimension of fight nuance that aggregate statistics miss.
Fighter profiling
Each fighter is modelled through several analytical dimensions:
- Style matchup analysis quantifies how a fighter’s offensive and defensive tendencies perform against specific opposing styles. We calculate performance records segmented by opponent style category - performance against grapplers, against counter-strikers, against pressure fighters - rather than using raw overall statistics.
- Signature technique and target mapping identifies each fighter’s most frequent offensive patterns and evaluates how those patterns interact with the specific opponent’s defensive tendencies. A fighter who relies on head kicks faces a different probability against an opponent with strong head movement than against one who tends to absorb strikes.
- Opponent-adjusted performance recalculates statistics relative to the quality and style of opposition faced. A fighter with a 70% takedown defence rate against low-level grapplers carries a different risk profile than one with 70% against elite wrestlers. Our adjustment model accounts for opposition quality at the individual technique level.
Health and durability indexes
Fighter condition is assessed through three indicators:
- Damage accumulation tracks cumulative strikes absorbed, knockdowns, and submission attempts survived across recent bouts. A fighter absorbing excessive damage in consecutive fights carries an increased risk regardless of win-loss outcomes. We weight recent damage more heavily, reflecting the medical reality of cumulative impact.
- Activity and rest balance models the relationship between fight frequency and performance. Too little activity introduces ring rust. Too much with insufficient recovery produces fatigue and injury risk. We identified optimal activity windows for different fighter profiles based on historical performance curves.
- Injury recovery indicators incorporate reported injuries, medical suspensions, and the gap between suspension expiry and return to competition. Fighters returning from layoffs show measurable performance patterns that our models capture.
Fight contextualisation
Environmental and logistical factors shape fight results in measurable ways:
- Venue factors include cage size and altitude. Smaller cages favour pressure fighters and reduce the space available for movement-based styles. Higher altitude affects cardio performance in later rounds. We quantified these effects across historical fight data and incorporated them as continuous features.
- Travel and time zone effects model the impact of cross-continental travel on fighter performance. Fighters competing outside their home time zone show measurable performance variation, weighted by distance, direction, and time zone differential.
- Weight class transitions track fighters moving between divisions. The severity of the weight cut, the direction of the move (up or down), and the recency of the transition all carry predictive signal that our features capture.
Machine Learning architecture
We built the modelling stack with a specific hierarchy - each model type serves a defined function, and deployment is gated on profitability. The architecture uses three model layers:
- Logistic regression serves as our validation baseline. Any model that cannot outperform logistic regression on held-out data does not justify its complexity. This baseline prevents us from deploying sophisticated models that add computational cost without adding predictive value.
- Gradient boosting and ensemble methods provide the primary prediction engine. These models handle heterogeneous feature types - continuous statistics, categorical style labels, temporal sequences - and produce calibrated probability estimates. We use ensemble stacking to combine multiple gradient boosting models trained on different feature subsets.
- Deep learning networks capture complex, nonlinear interactions between features that tree-based methods miss. These models are effective at learning matchup interaction effects - the ways two specific fighter profiles combine to produce outcome probabilities that differ from individual profile predictions.
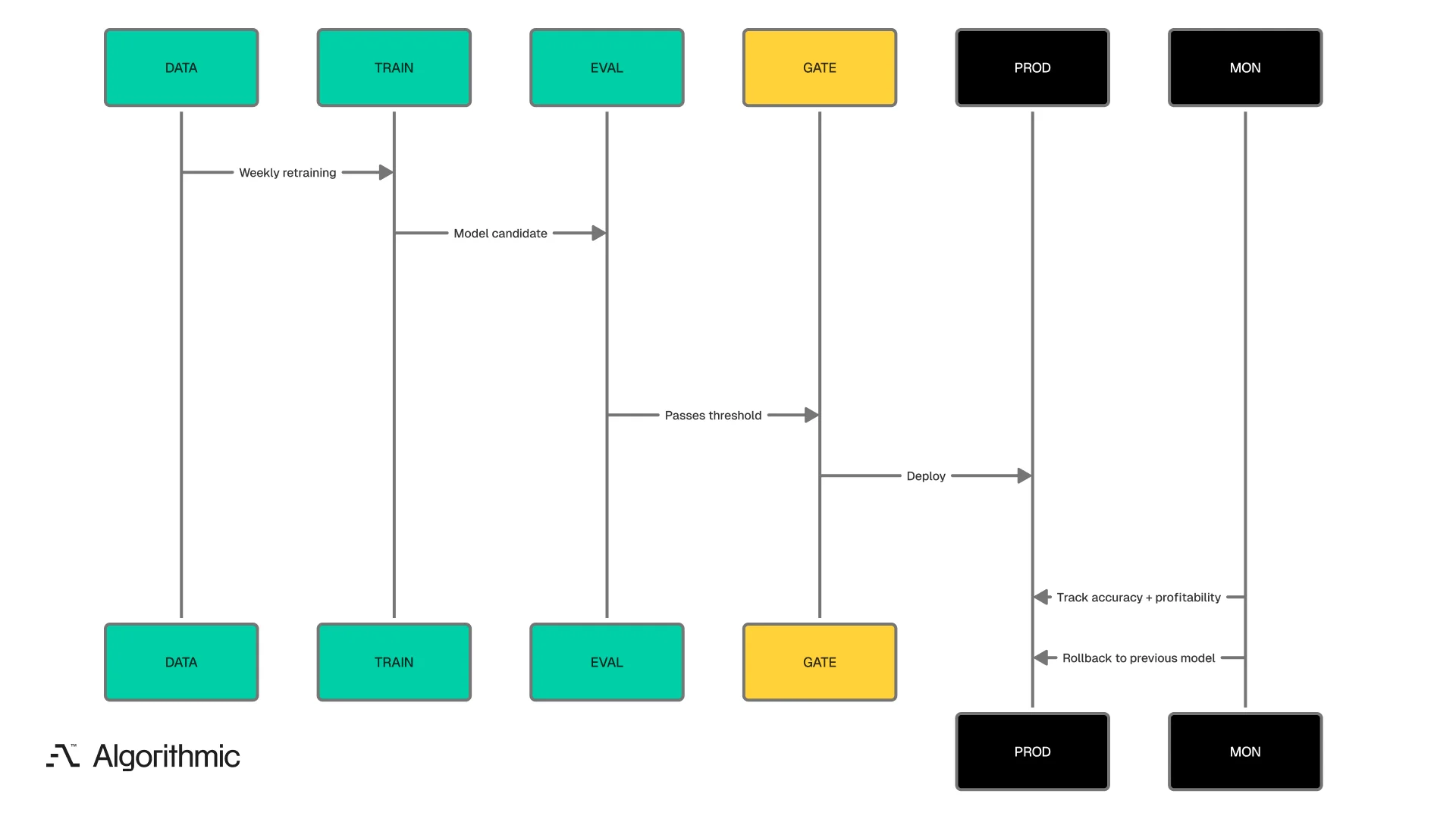
The retraining and deployment cycle follows a disciplined process. Models retrain weekly with fresh fight data, injury updates, and market movement. Fresh candidates are backtested against historical betting lines and paper-traded against current lines. We evaluate every candidate on its ability to generate positive expected value against live market odds.
A model with 62% accuracy but negative expected value does not deploy. Only models demonstrating sustained profitability reach production. Models that degrade in live performance trigger automated rollback to the previous stable version.
The platform follows a five-stage pipeline from multi-source ingestion through profit-gated deployment.
 Click to expand
Click to expand Dashboard and decision support
We designed the dashboard for betting professionals who make multiple decisions per event card. The interface provides four primary capabilities:
- Recommended bets with confidence scores rank available opportunities by expected value, with full transparency into the features driving each recommendation. Users see which signal domains - fighter profiling, health indexes, contextual factors - contribute most to each prediction.
- ROI tracking segments performance by bet type (moneyline, prop bets, round totals), weight class, event, and rolling time horizon. This granularity allows users to identify which model segments produce the strongest returns and allocate accordingly.
- Filtering and drill-down isolates performance by weight class, fight type, venue, and style matchup category. A user can evaluate the model’s track record specifically on grappler-versus-striker matchups at flyweight, for example.
- Real-time alerts fire when high-value matchups emerge - either from updated model predictions or from market line movements that create expected-value opportunities against model probabilities.
Infrastructure
The platform runs on AWS with infrastructure shaped around MMA’s event-driven scheduling. Four operational capabilities support production reliability:
- Dynamic scaling increases compute during major fight weeks when data volume, retraining frequency, and user activity spike simultaneously. Between events, resources scale down to baseline.
- Continuous monitoring tracks model performance, data pipeline health, and prediction calibration in real time. Drift detection flags when model behaviour shifts outside expected bounds.
- Automated rollback reverts to the previous production model if the current deployment shows anomalous behaviour - unexpected accuracy drops, calibration drift, or profitability degradation.
- Data lineage maintains a complete audit trail from raw source data through feature engineering to final prediction, enabling investigation when model behaviour requires explanation.
Models retrain weekly and pass through a multi-stage evaluation before reaching production. Automated monitoring triggers rollback if live performance degrades.
 Click to expand
Click to expand What we delivered
| Metric | Result |
|---|---|
| Long-term ROI lift | 10-20% on managed betting portfolios |
| Time-to-bet | From hours of manual research to automated alerts within minutes |
| Risk management | Bankroll allocation and loss flagging integrated into decision workflow |
| Market coverage | UFC, Bellator, and regional promotions |
| Model discipline | Profit-gated: only demonstrably profitable models reach production |
| Rollback capability | Automated reversion on performance anomaly detection |
The platform serves professional sports bettors managing personal portfolios, betting syndicates and quantitative funds operating at scale, and sports data companies integrating predictive signals into their own products.
What this work represents
Combat sports prediction sits at the intersection of sparse data modelling, real-time information processing, and profit-driven deployment discipline. The platform we built for MMA shows that even in domains where data is limited and volatility is high, structured engineering and rigorous model evaluation produce measurable, sustained returns.
The same architectural pattern - multi-source real-time ingestion, contextual feature engineering across multiple signal domains, profit-gated model deployment, and event-driven infrastructure - applies to any domain where predictions must generate financial value. Team sports. Financial markets. Demand forecasting. Risk analytics.
We design and build predictive systems where the standard for success is measured returns, and where the data availability is complex enough to reward serious engineering. If that describes your problem, we should talk.
This platform was built through Algorithmic’s predictive analytics and data infrastructure practices - combining domain-specific feature engineering with production-grade ingestion, training, and deployment pipelines.

