
[ Insights - Machine Learning ]
The Machine Learning Checklist
Learn how to assess your organization or project's readiness for Machine Learning. In this guide we cover highly important aspects such as data quality, infrastructure, team setup, and ROI to help you derive deep business value. Ideal for leaders and teams planning to scale data-driven solutions responsibly and effectively. Can also be utilized by hobbiests for their solo projects.
Read time: 3 minutes
Over the past few years, machine learning has become the gold rush of modern business. Since ChatGPT’s public debut in 2022, nearly every organization has looked for ways to “bring AI into the workflow”. Some have built real value such as smarter chatbots, faster decisions, sharper customer insights. Others have poured time and money into projects that never made it past the pilot stage.
It’s not hard to see why.
Machine learning feels inevitable, the next step in digital maturity. But beneath the excitement lies a quiet truth that many companies simply aren’t ready.
Building and deploying intelligent systems demands commitments, and it calls for clean, reliable data, a resilient infrastructure, and a team that understands both the math and objective. Without these foundations, machine learning becomes a costly experiment that solves the wrong problem, or worse, no problem at all.
As Sam Altman, CEO of OpenAI, once noted, “the intelligence of an AI model roughly equals the log of the resources used to train and run it”. In other words, intelligence scales slowly, and expensively. You can throw people and capital at a project and still end up with a model that underperforms, misfires, or doesn’t fit your users’ needs.
So, before you start training models or drafting AI roadmaps, pause.
Ask the harder question: Is your organization ready for machine learning?
This article outlines the essentials, which are the data, infrastructure, and people you need in place before committing to the journey. It serves as a readiness checklist, helping leaders balance ambition with the practical realities of execution.
Clearly define the problem you are trying to solve.
One of the most common mistakes in machine learning adoption is starting with the model instead of the mission. Teams get excited about AI, assemble data, and only then ask what problem they’re trying to solve. By that point, it’s often late and the solution has outgrown the need.
A better starting point is questioning the problem we are trying to solve. What decision or process are you trying to improve? What’s broken within your system? Is it accuracy, speed, cost, or feedback loops? The clearer the question, the easier it is to see whether machine learning is the right tool.
Not every challenge necessitates a learning algorithm. Many issues can be resolved through improved logic, better workflow design, or automation. Machine learning is particularly valuable when the pattern space is large or unpredictable, when rules frequently fail, or when the data reveals a story that is too complex to be captured by simple if-then statements.
Consider fraud detection, customer churn prediction, or personalized recommendations. These are domains where human intuition or fixed rules fall short. But for stable, well-defined processes such as enforcing compliance checks or validating transactions, a deterministic system is often faster, cheaper, and more transparent.
The most resilient organizations know how to blend both worlds. They use rule-based systems as the backbone of reliability and machine learning as the brain that adapts. In other words, machine learning should extend human logic, not replace it.
What does “Data-Driven” mean for your problem?
Before investing in machine learning, it helps to understand what data-driven actually entails. The term is often used loosely, sometimes as a synonym for “modern” or “digital”. In reality, it signals a shift in how decisions and systems are designed. A data-driven solution learns from patterns hidden in information collected over time. It doesn’t just follow rules; it discovers them. By contrast, a rule-based system works through logic defined by humans - “if this, then that”. One is probabilistic, the other deterministic.
Neither approach is inherently better. The real question is which one fits the problem. Machine learning excels when patterns are too complex or fluid to be captured through fixed logic. For instance, in predicting demand, identifying anomalies, or tailoring user experiences. But when the problem space is stable and well understood, traditional rule-based software can be faster, cheaper, and more reliable.
The best systems often blend both - rules for structure, models for insight.
Think of a fraud detection engine - it might enforce strict rule-based limits for known risks, while machine learning models monitor behavior to catch the unexpected. Intelligence lies not in choosing one over the other, but in knowing where each belongs.
Define your margin for error
Every organization has a different appetite for risk, and machine learning can quietly test it. These systems analyze probabilities, which is both their strength and their limitation.
Traditional software gives you certainty. Feed it the same input, and you’ll always get the same output. Machine learning, on the other hand, deals in likelihoods. It predicts what’s most probable based on patterns in data. Sometimes that means it’s brilliantly right. Sometimes it’s wrong in unexpected ways.
That’s why the first question to ask isn’t “How accurate is the model?” but “How much inaccuracy can we tolerate?”.
A misclassified movie recommendation is harmless. A misread signal in an autonomous vehicle isn’t.
Tolerance for error sets the tone for everything downstream. These include how models are trained, how results are validated, and how human oversight is structured. In low-risk applications, autonomy can drive efficiency. In regulated or safety-critical domains, it demands rigorous controls and contingency design in place from the very beginning.
Leading organizations think of this as calibrating trust. They build systems that fail safely, adapt quickly, and stay accountable. The goal is resilience in ensuring that when the model gets it wrong, it does not pose a significant business risk.
Assess your data readiness
Data is the raw material of machine learning and like every raw material, its quality determines what you can build. If the foundation is weak, no model can fix it. True readiness is about having the right data. It must be relevant, reliable, and responsibly managed. In most organizations, that’s where the first cracks appear.
Start with quality. Can your data be trusted to describe reality? Incomplete, inconsistent, or noisy records distort insights, or patterns as we mentioned earlier. Cleaning and validating that data is what creates robust machine learning systems. Next, look at balance. If your data skews toward one geography, customer type, or scenario, your model will learn that bias as truth. Finally, look at governance. Good data is also about how you manage it with clear ownership, secure storage, and well-defined access rules to help keep data safe and trustworthy. Think of the right sign-offs you need within your organization to access data. All stakeholders must be fully informed about what you are doing with the data to avoid internal misunderstandings/miscommunication within departments.
Before you start building models, make sure the foundation is sound. Most machine learning projects fail because the data behind them can’t be trusted. Data readiness should be looked at as a business safeguard.
Build the right team and toolset
Even with high quality data, machine learning initiatives rarely succeed without capable teams and the right tools. With machine learning execution determines value and outcomes.
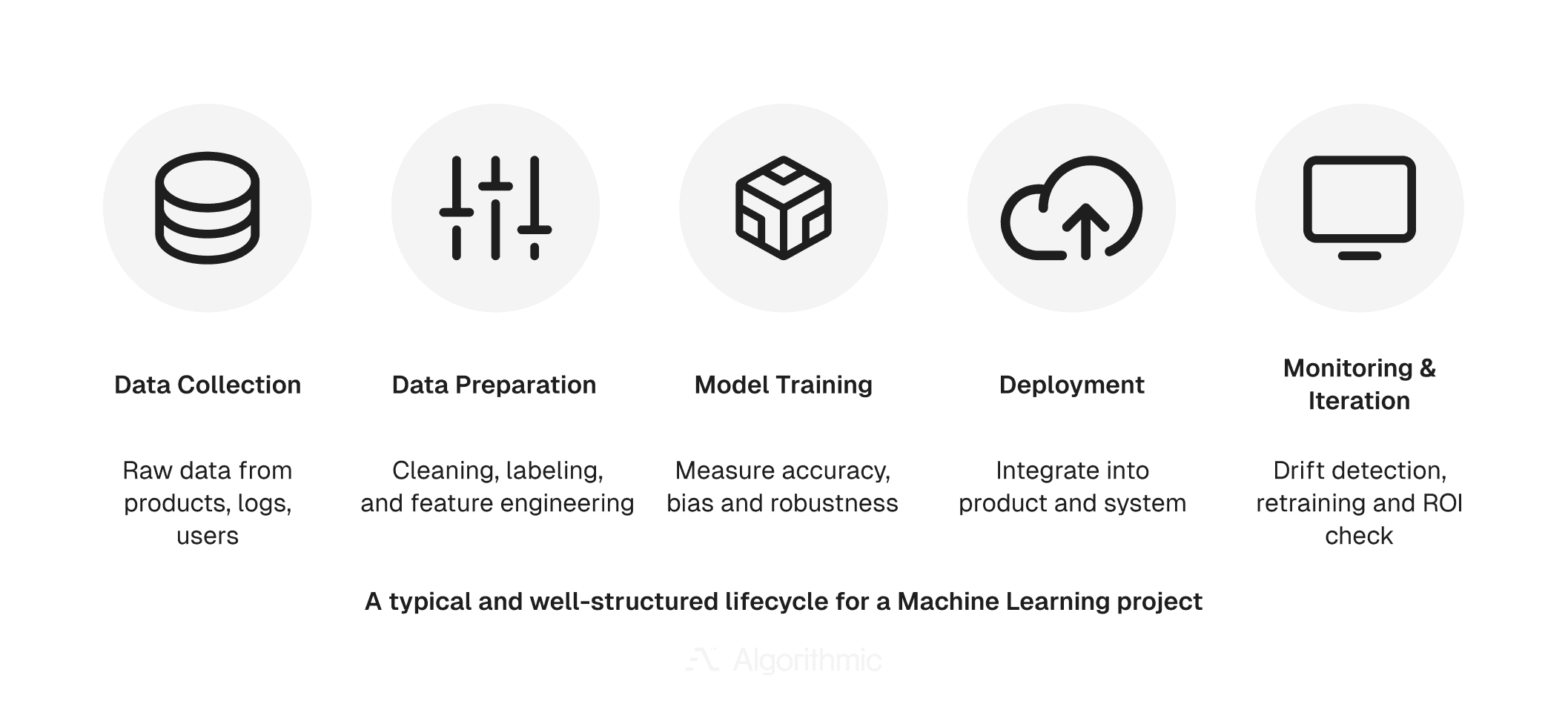
At its core, every ML system follows the same lifecycle:
Data collection: Gathering raw information from products, user interactions, and logs.
Data preparation: Cleaning, labeling, and shaping that data through feature engineering.
Model training: Measuring accuracy, bias, and robustness before moving into production.
Deployment: Integrating the model into live systems and workflows.
Monitoring and iteration: Detecting drift, retraining, and checking if the model requires fine tuning.
Each stage requires a mix of technical skill, business judgment, and continuous iteration. And as the diagram below shows, it’s only worth the effort if your data, infrastructure, and people are ready.
The challenge for most organizations is operationalizing these steps. Teams often underestimate the ongoing work such as cleaning and labeling data, building robust pipelines, monitoring performance drift, or integrating retraining loops into product cycles.
At Algorithmic we have supported startups, small and medium business and large organizations to establish this end-to-end capability which includes building data pipelines, setting up experimentation frameworks, and designing governance models that make ML sustainable. Our role is to make machine learning operationally ready and technically possible. You come with a problem and leave with a solution.
With the right people and tools in place, ML shifts from a research experiment to a repeatable, value-generating system.
Build the right infrastructure
Infrastructure is often where machine-learning projects succeed, or could quietly stall. The issue is efficiency. Many teams over-engineer their environments, spending heavily on compute and storage that add little real value.
A sound setup has to be fit for the purpose with a keen attention to costs. The goal is to create an environment that supports experimentation, scales when required, and remains cost-efficient under real workloads. At Algorithmic, we take a pragmatic view. Our teams design lean servers that balance performance and cost discipline. Drawing on deep MLOps experience, we focus on using the right stack rather than the largest one. In several client engagements, this approach has reduced monthly cloud spend from multiple five-figure levels to a few hundred dollars, without compromising capability. Rather in some cases we have made the entire pipeline a lot more efficient because we have ended up improving the technical stack.
The principle must be simple, which is to make sure that the infrastructure should serve the model, not the other way around. By selecting appropriate frameworks, optimizing data pipelines, and automating deployment and monitoring, organizations can achieve reliability and scalability without costly mistakes.
Evaluate financial readiness and ROI
Sound infrastructure and capable teams make machine learning possible, but financial readiness determines whether it’s sustainable. Every initiative, no matter how promising, eventually meets the same question - does it create more value than it consumes?
Machine learning carries costs such as infrastructure, compute, data storage, and the ongoing work of monitoring and retraining. We’ve covered a few of these pointers earlier, and to add to it, from our experience, we have seen teams that initially thought it would be affordable at launch, and then find it expensive to maintain when it moves into production. Financial discipline is key and it means being intentional about the investment.
Well-run teams design for efficiency from the start. These include some basics such as selecting the right model that fits the problem, automating where possible, and linking performance metrics directly to business outcomes. In practice, the organizations that succeed spend less over time because they learn to measure value, not just accuracy.
The right operational frameworks can often cut recurring costs dramatically, and sometimes by an order of magnitude. We must be careful about preemptively understanding where our costs are going to be going and creating provisions for them.
Last few words
Machine learning is becoming part of the core architecture of forward-looking businesses. Success in this domain is rarely a function of business objectives alone. It depends on readiness - the discipline to align data, infrastructure, people, and finances before scale.
The organizations that succeed understand this. They resist the temptation to chase capability for its own sake and instead build the conditions that make capability useful. They treat machine learning as a managed system which combines technical, operational and financial discipline. Readiness, in that sense, becomes a strategic posture for organizations and determines whether AI becomes a cost center or a source of enduring advantage for founders, leadership teams, and teams. You can also take a look at the following relevant articles where we have applied Machine Learning to niche use cases such as Sports Betting and Quality Assurance in production plants.
Algorithmic is a software engineering studio that partners with founders and teams across the full product lifecycle. Our core areas of focus include end-to-end product development, applied machine learning & AI, and data analytics & infrastructure.
We continue to study and support this evolution by helping teams move from experimentation to execution, from isolated use cases to scalable capability. If you’d like to follow our research, perspectives, and case insights, connect with us on LinkedIn, Instagram, Facebook, X or simply write to us at info@algorithmic.co



