
Your users have a catalog of hundreds, thousands, or millions of items in front of them. They need to find what they want, fast. If they can’t, they leave.
Netflix, Amazon, YouTube, and Spotify solved this problem with recommendation systems, algorithms that learn what each user prefers and surface the right content at the right time. Users feel understood, stay longer, and come back.
Recommendation systems are machine learning models trained on user behavior data. They identify patterns in how people interact with products and use those patterns to predict what a given user will want next. A user rates a movie positively, and the system offers similar titles. A shopper adds a sweater to their cart, and matching pants appear alongside it.
This guide covers how recommendation systems collect data, how their core algorithms work, where they create value across industries, and what you need to plan for before building one.
Two types of data your system needs
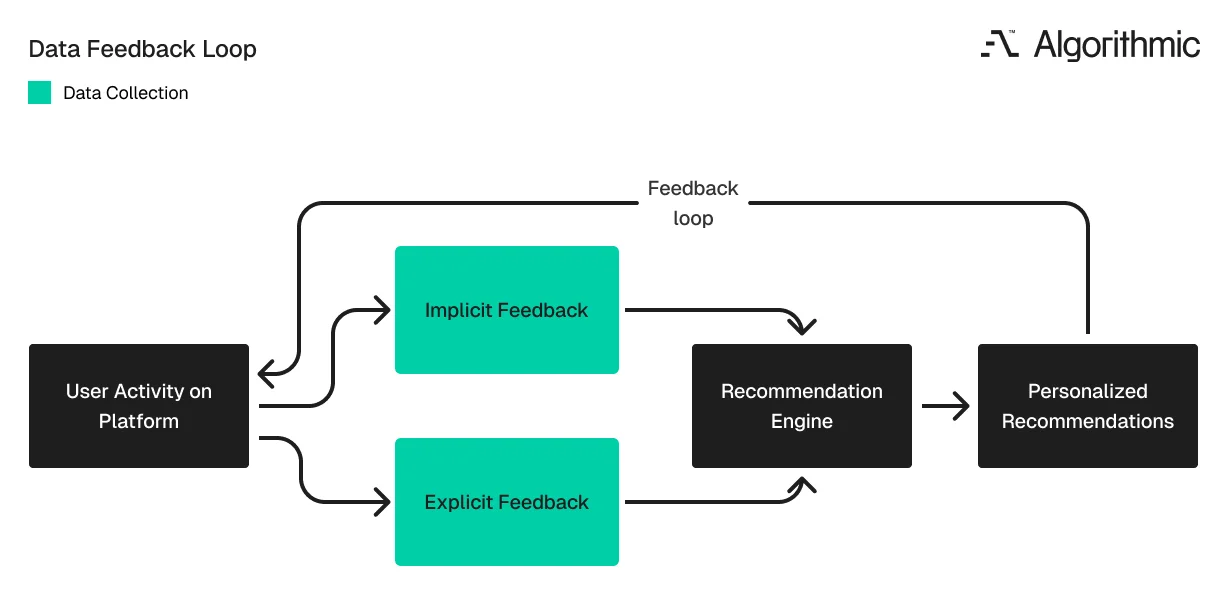
Recommendation systems learn from user behavior. That behavior shows up in two forms - explicit feedback and implicit feedback.
Explicit feedback
Explicit feedback is any direct signal a user provides about their preferences. Likes, dislikes, star ratings, written reviews, subscriptions, and saved items all fall into this category. Each signal carries specific information about what the user values.
A five-star rating leaves little room for misinterpretation. The challenge is that most users browse without rating, reviewing, or commenting. Datasets built entirely on explicit feedback tend to be sparse - too sparse for reliable recommendations on their own.
Implicit feedback
Implicit feedback captures the behavior the user generates naturally. Time spent on a product page, search queries, purchase history, scroll depth, repeat visits, and click patterns all qualify. This data contains more noise than explicit signals - a user spending three minutes on a product page might be interested, or they might have stepped away from their screen.
Implicit feedback is available in much higher volume. Every user generates it on every session without any extra effort. In most recommendation systems, implicit signals serve as the primary training data.
 Click to expand
Click to expand How the three core filtering methods work
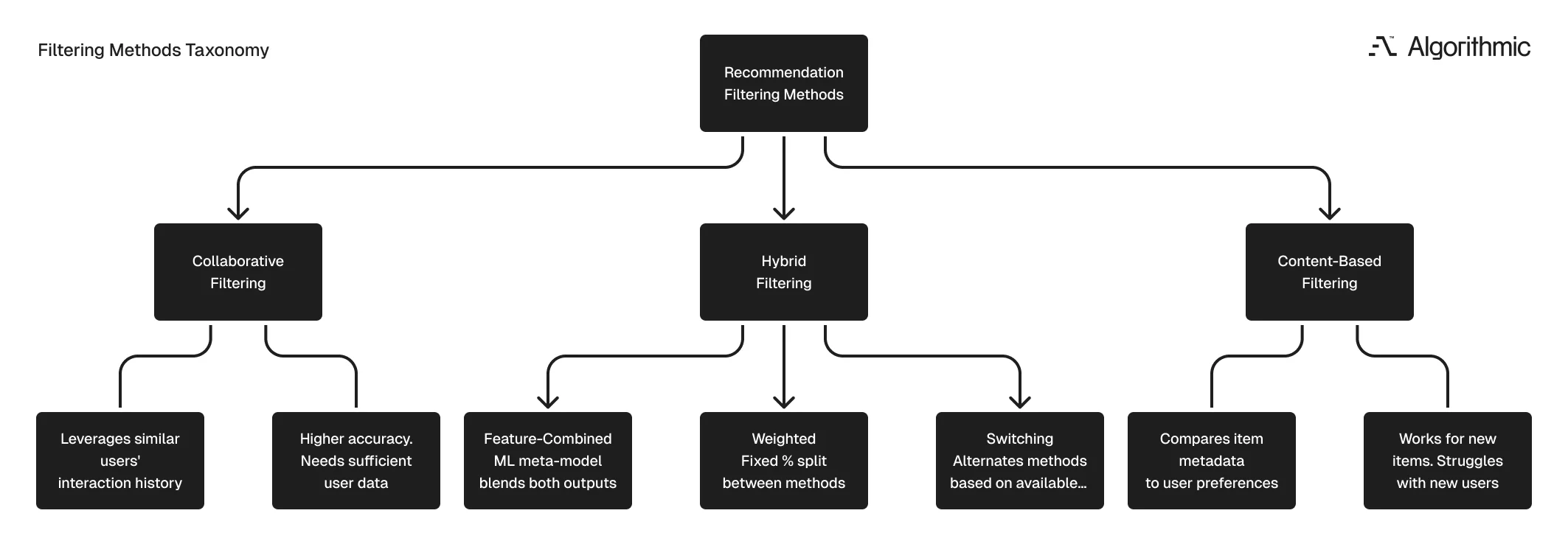
Recommendation systems filter a large catalog down to a small set of relevant suggestions. Three approaches power this filtering: content-based, collaborative, and hybrid.
 Click to expand
Click to expand Content-based filtering
Content-based filtering matches item attributes to user preferences. Every product in a catalog carries metadata - genre, category, price range, intended use, author, brand. The system builds a profile of what each user prefers based on items they have engaged with, then finds other items with similar attributes.
This approach handles new items well. A song added to Spotify today carries genre, tempo, and artist metadata from the start, so the system can recommend it to users with matching taste profiles immediately.
For new users, the system lacks a preference profile to match against. Without interaction history, content-based filtering has no foundation to build on.
Collaborative filtering
Collaborative filtering identifies patterns across the full base of user-item interactions, the approach Amazon pioneered at scale with item-to-item filtering. Instead of comparing item attributes, it compares user behavior. Users who interact with similar items get grouped together, and the system recommends items that one user in the group has engaged with to others in the same group.
This method draws from every interaction across every user, which gives it a larger training dataset and often produces more accurate recommendations. The limitation mirrors the one content-based filtering handles well: new items with no interaction history have no behavioral patterns to draw from.
Hybrid filtering
Most production systems combine content-based and collaborative filtering. Three common hybrid implementations exist.
Weighted hybrid filtering assigns a fixed percentage to each method’s output. A system might weight content-based recommendations at 60% and collaborative recommendations at 40%, then blend the results into a single ranked list.
Switching hybrid filtering alternates between methods based on available data. When a user has not interacted with enough items to build a reliable preference profile, the system leans on collaborative signals from similar users. As the user’s interaction history grows, content-based filtering contributes a larger share to the final recommendations.
Feature-combined hybrid filtering trains a machine learning meta-model - often using a technique called stacking - that takes outputs from both filtering methods as inputs. The meta-model learns the optimal way to combine those outputs for each recommendation scenario, adapting the blend automatically rather than relying on fixed weights or manual switching rules.
The cold-start problem
Every recommendation system faces the same challenge early on: what do you recommend when you have little or no data about a user or item?
This is the cold-start problem. It shows up in two forms.
New users have no interaction history. The system has nothing to build a preference profile from. Collaborative filtering can partially address this by finding users with similar demographics or initial behavior. Onboarding surveys (“Pick five genres you enjoy”) and selection prompts also generate enough signal for a starting profile.
New items have no user interactions. No one has clicked on them, purchased them, or rated them. Content-based filtering handles this by using the item’s metadata (genre, attributes, category) to place it in front of users whose existing preferences match.
Popularity-based fallbacks serve as a practical baseline for both cases. Showing a new user the most popular items in their region or category outperforms random suggestions by a wide margin and buys time for the system to collect enough interaction data for personalized results.
Where recommendation systems create measurable value
Recommendation systems are standard infrastructure across any industry where users face a large catalog and limited time.
E-commerce is the most visible application. A user adds a sweater to their cart, and the platform suggests matching pants, a matching scarf, or a similar item at a different price point. Platforms like Luigi’s Box Recommender and Algolia provide recommendation engines that help e-commerce products surface relevant items from catalogs with millions of SKUs.
Fitness and health platforms use recommendation systems to personalize training plans. Apps like Strava and Freeletics learn from user attributes - age, fitness level, mobility, training history - and recommend exercises tailored to individual capabilities and goals. In clinical settings, recommendation systems support diagnostic workflows by suggesting possible conditions based on symptom patterns and patient medical records.
Education platforms depend on recommendations to match learners with the right content. Coursera, Udemy, and Preply suggest courses based on a user’s existing skills, available time, and stated learning goals. The result is a personalized curriculum that keeps learners engaged and progressing.
Travel, finance, gaming, real estate, recruitment, and media all use recommendation systems in similar ways - helping users move through large option sets and find what fits them.
Three ways recommendation systems pay for themselves
They build user trust and retention
Users stay with products that feel tailored to them. A recommendation feed that consistently surfaces relevant content signals that the product understands what the user needs. This trust compounds over time into higher retention rates, more subscription renewals, and stronger word-of-mouth referrals.
They increase revenue
Recommendations surface products users would not have found through manual browsing. Cross-sell suggestions, premium subscription nudges, and longer engagement sessions each contribute to higher revenue per user. Every additional minute a user spends on your platform - watching, shopping, learning - is an opportunity to convert.
They reduce operational costs
Automated product discovery replaces manual curation. Editorial teams that once hand-picked featured items can focus on higher-value work while the recommendation engine handles catalog navigation at scale. Users who find what they want faster convert at higher rates per session, which reduces the cost of each acquisition.
What to plan for before you build
These are the readiness questions to settle before you write model code, the recommendation-specific version of a broader machine learning readiness checklist.
Data collection infrastructure
Recommendation systems need a steady stream of interaction data. Start collecting behavioral signals - clicks, views, search queries, time-on-page, purchases - before you begin building the recommendation engine itself. The earlier you start capturing this data, the more training material you will have when you are ready to deploy.
Evaluation and measurement
Track recommendation quality with a defined set of metrics. Click-through rate and conversion rate measure direct business impact. Precision and recall measure algorithmic accuracy. Catalog coverage - what percentage of your items get recommended - and diversity - how varied the recommendations are - help detect filter bubbles and check that the system surfaces a healthy range of products.
Data privacy and compliance
Behavioral tracking requires transparent data collection policies and informed user consent. Regulations like GDPR and CCPA define how interaction data must be collected, stored, processed, and shared. Building privacy-compliant data pipelines from day one avoids costly retrofitting later.
Where to start
Recommendation systems are among the most practical applications of machine learning for product teams. The path to implementation starts simple. You first launch with popularity-based recommendations as your baseline, add collaborative filtering as your interaction data grows, and layer in content-based filtering to handle new items and new users. Each step compounds into a better user experience, higher engagement, and stronger revenue.
Algorithmic builds recommendation systems from data collection through production serving, including collaborative filtering, content-based models, and hybrid approaches tuned to your product’s engagement patterns and growth stage. Start a conversation if a large catalog is getting between your users and what they came for.
If you’d like to follow our research, and case studies, connect with us on LinkedIn, Instagram, Facebook, X or simply write to us at info@algorithmic.co


