
[ Insights - Machine Learning ]
Building and Evaluating RAG Systems the Right Way
This article breaks down how RAG (Retrieval Augmented Generation) systems work and shows why most failures come from retrieval, ranking, or evaluation gaps rather than the model itself. It offers a clear framework that helps teams diagnose model drift, strengthen reliability, and scale enterprise-grade RAG systems.
Read time: 5 minutes
Retrieval-Augmented Generation has become a core strategy for organisations deploying large language models (LLMs) in production environments. Its value lies in enabling models to use trusted internal data, improving factual grounding, and reducing risk without the overhead of training specialised models. When implemented well, RAG systems allow enterprises to extend general-purpose LLMs into domain-specific tasks while controlling cost and complexity.
However, many organisations discover that initial performance does not hold once the system encounters real-world usage patterns. Answers fluctuate. Relevance decays. Confidence remains high even when accuracy decreases. These issues are often attributed to hallucinations, but hallucination is usually a symptom rather than the underlying cause. In practice, most failures arise from weaknesses in retrieval, ranking, context construction, or inconsistent operational processes. A common issue across organisations is the absence of structured evaluation frameworks, making it difficult to detect where the pipeline is drifting or why performance is unstable.
A RAG system is not a monolithic component. It is a sequence of interconnected decisions that must remain coherent for the system to behave reliably. Each stage introduces dependencies, potential failure modes, and opportunities for drift. Building robust RAG systems requires understanding these components not only in isolation but also in terms of how they interact over time.
The sections below present a comprehensive overview of the RAG architecture, describe where failures typically occur, and outline a rigorous evaluation methodology that organisations can apply to maintain system quality in production.
Core components of a RAG system
While RAG can be conceptually described as “retrieve relevant data, then generate an answer,” the operational reality is more complex. A well-structured RAG pipeline typically includes the following components:
Text-splitter
Embedder
Vector database
Retriever
Reranker
Generator (LLM)
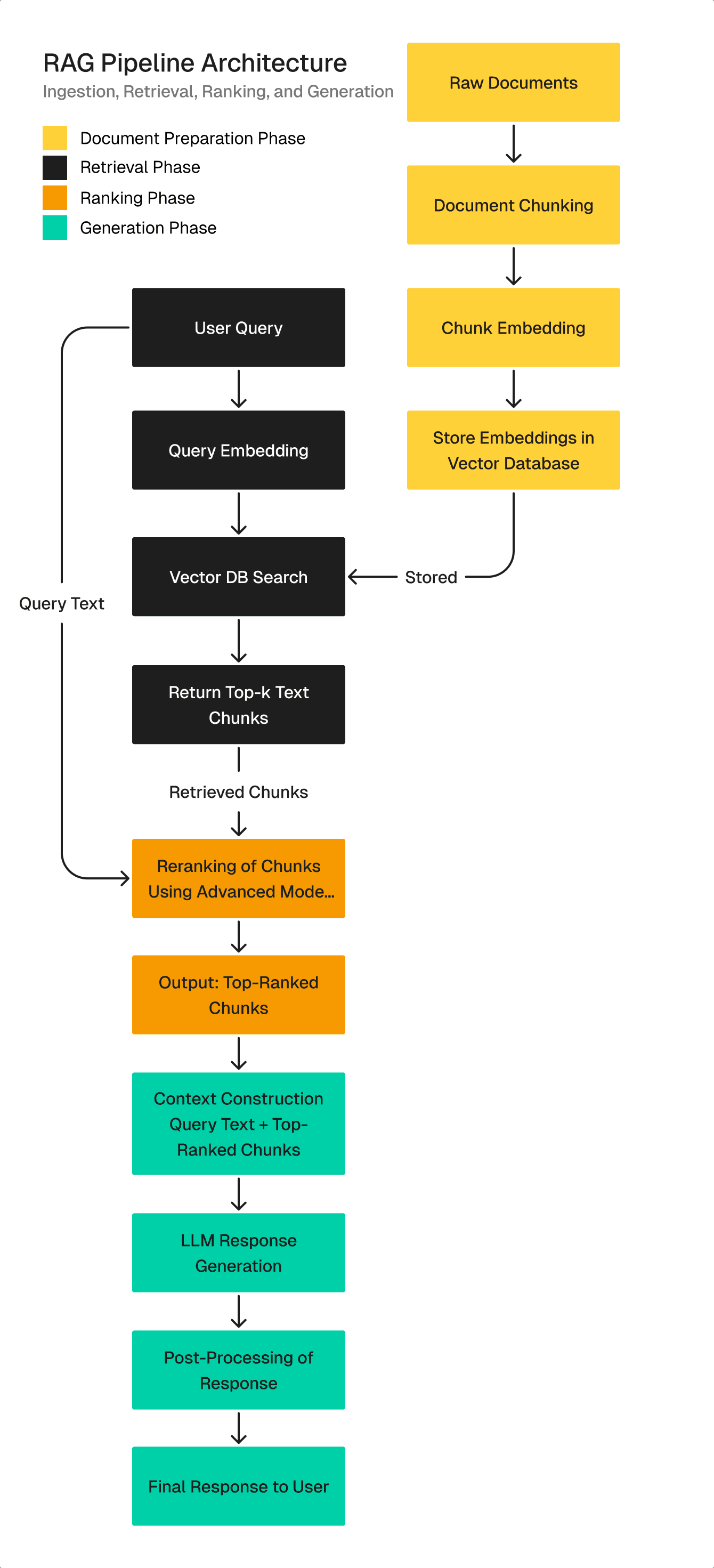
Each plays a specific role. Each introduces risks. And each requires clear performance expectations and evaluation metrics.
Text-splitter
Establishing the Structural Foundation
The pipeline begins with splitting documents into smaller segments. This step determines the structural granularity through which the model will perceive the corpus. Although the mechanics seem straightforward, this is often one of the earliest points where quality begins to degrade.
Smaller chunks reduce embedding cost, improve granularity, and reduce the risk of exceeding context limits. However, they may fragment cohesive ideas, weakening semantic coherence and reducing retrieval effectiveness. Larger chunks preserve context but dilute semantic clarity, increase computational overhead, and often reduce retriever precision because meaningful signals become harder to match. Overlapping windows help maintain continuity but increase disk usage, index size, and latency.
Poor chunking is one of the most common sources of weak retrieval, and its impact is usually misattributed to the model. A well-designed text-splitting strategy should reflect the document’s structure, domain, and intended retrieval patterns.
Embedder
Converting Text Into a Searchable Semantic Space
Embedding is the process of converting text into vector representations that encode latent semantic relationships. These embeddings form the backbone of similarity search and significantly influence retrieval quality. Three factors are especially important:
Dimensionality: Higher-dimensional models capture richer nuance but increase storage requirements and query latency. Organisations must balance representational power with operational cost.
Model consistency: When embedding models change, even slightly, the geometric structure of the vector space changes along with them. If the corpus is not re-embedded and re-indexed, retrieval precision drops due to misaligned vectors. This is often called embedding drift.
Query - document parity: Queries and documents must be embedded using the same model and configuration. Any deviation creates inconsistency, leading to unpredictable retrieval outcomes.
Embedding strategy requires clear versioning, careful change management, and coordination with downstream components.
Vector Database
Helping preserve semantic integrity at scale
Vector databases store embeddings and support efficient similarity search across large corpora. Their behaviour is shaped by both the volume and distribution of the data they index.
Key considerations include:
Index performance: Indexes degrade as corpus size and distribution change. Periodic rebuilds are required to maintain search accuracy and latency.
Latency and throughput: Query speed depends on dimensionality, index structure, hardware, and concurrency patterns.
Mixed-version embedding risks: Storing embeddings generated from different model versions within a single index reduces similarity scoring fidelity and significantly weakens recall.
A robust vector storage system must be monitored continuously and refreshed as data, models, and usage patterns evolve.
Retrieval
Determining What the Model Actually Sees
The retriever selects the top-k chunks most relevant to the user's query. This stage heavily influences system performance because it governs what information the LLM can base its answer on. Selecting k requires careful balance:
Too few items and essential information may be omitted.
Too many items and the LLM receives noisy context, weakening grounding and increasing hallucination likelihood.
This reflects the classical precision & recall tradeoff. Retrieval quality is also impacted by chunking strategy, embedding consistency, index performance, and corpus coverage.
Production RAG systems often employ hybrid retrieval, combining dense vector search with sparse keyword search or metadata filtering, to ensure more robust recall across varied query types.
Reranking
Refining the Candidate Set Before Generation
Once retrieved, candidate chunks are re-scored by a reranker model that evaluates query–document interactions more deeply. Cross-encoder rerankers often outperform dense retrieval by incorporating richer contextual signals. For accurate scoring, the reranker must receive both the chunks and the query. It then assigns relevance scores, and the highest-ranked items form the final context for the LLM. Reranking mitigates many issues that arise from imperfect retrieval. When configured well, it is one of the highest-leverage components in a RAG system.
Generation
Producing a Grounded and Accurate Response
The generation step uses the retrieved context and the query to produce a response. Model selection affects tone, reasoning depth, and structural capabilities, but grounding quality depends heavily on upstream components. Even with accurate retrieval, models may generate unsupported content if the prompts fail to emphasise context adherence or if the retrieved evidence is insufficient. Prompt design, refusal behaviour, and context formatting all play meaningful roles in generation reliability.
Connecting the Pipeline
The RAG pipeline consists of two parallel flows:
Document upload flow: When user provides a document to a chatbot or any other kind of RAG system first step is reading textual content on the page. This text is then chunked using text-splitter. Text chunks are then forwarded to embedder where they are embedded and turned into vectors. In the end those vectors are written in a vector database.
Query flow: When user asks a question related to the uploaded document this query is embedded using embedder in the same way as text from uploaded document. Embedded representation of the query is sent to the vector database where similarity-based search is performed. Only k most relevant context vectors are returned to the LLM along with the query so the LLM can generate an answer based on the retrieved context, though grounding quality still depends on retrieval accuracy.
Although RAG system capabilities may look simple or non-important it's impact on final decision making process is greater than simple providing information - it helps general-purpose LLMs answer even domain-specific questions.
This means that you don't have to retrain or fine-tune general-knowledge model on some domain-specific data every time this quest arises, although in highly specialised domains, light fine-tuning may still be necessary for reasoning or structured output tasks. You can only incorporate it in a high-quality RAG system.
Evaluating RAG Systems
A Structured Diagnostic Framework
To operate a RAG system reliably, teams must measure where and how the pipeline performs. Each component has associated metrics that reveal specific failure modes. Without these metrics, system degradation becomes difficult to diagnose. Evaluation metrics fall into two categories which are retrieval-based and generation-based.
Retrieval-Based Metrics
Contextual relevancy
This metric checks how much is context provided by the RAG system relevant to the sent query and LLM response. Since the main purpose of RAG system is to provide LLM with the most relative content from input data it's obvious why this metric takes such important place in the evaluation pipeline. The more relevant the context - the better quality of the answer.
How is this metric actually calculated?
Since natural language has many interpretations of the same thing, it is not easy for computers to calculate relevancy or similarity between two objects. Pure vector similarity is insufficient for evaluating semantic relevance at the level required for RAG evaluation. The other way to do this is using method known as LLM-as-a-judge. This method includes using external LLM models to decide about relevancy between provided context and user's query and LLMs output.
So, basically, the process includes three steps:
Extracting statements from provided contextual data pieces.
Calculating how relevant those statements are to the input query and LLMs response.
Computing contextual relevancy score as the ratio between number of relevant context pieces and total number of provided context pieces.
Providing the most relevant data to the LLM is the first step to successful answer generation.
Contextual precision
While contextual relevancy calculates how relevant the provided context is to user's query and generated answer, contextual precision checks in which order are those contextual pieces retrieved. Since the most important task of RAG system is to rank contextual pieces in the database and provide LLM with k most relevant ones - it is of crucial importance to check that those data points are ranked correctly.
Core idea of contextual precision is to check if retrieved chunks are the ones labeled in the ground truth and than if those vectors are ranked correctly. Final score shows if vectors are ranked in the correct order - from most relevant to least relevant.
Contextual recall
Contextual recall describes one more aspect of RAG evaluation. It calculates how many relevant vectors are retrieved from the database out of all relevant vectors. Total number of retrieved vectors will always be less or equal to the predefined value of k. Yes. But not all retrieved vectors will be really relevant to the asked question. So, determining how many of retrieved vectors are actually labeled as relevant in the ground truth will tell you if your ranker and retriever have desired performance.
Unlike contextual relevancy, contextual precision and contextual recall are metrics that usually require ground truth information. But, in real-world scenarios ground truth is not always available as it requires investing additional working hours to provide all reliable context. Since large documents can contain great number of vectors this job can take hours or even days.
So, to escape this kind of grind you can calculate contextual precision and recall using LLM-as-a-judge methods which will compare retrieved vectors and user's input to calculate their relevancy. And there are few tools that can help such as DeepEval, Ragas, RagaAI etc.
Generation-based evaluation metrics
Evaluating a RAG system requires more than assessing retrieval quality. The final outputs must also be examined to determine whether the large language model is using the retrieved context effectively and responding in a manner that is factual, safe, and consistent with organisational requirements. Five metrics matter most for assessing generation behaviour, which are faithfulness, correctness, hallucination, toxicity, and bias. Each highlights a distinct dimension of model reliability.
Faithfulness
Faithfulness measures the degree to which the generated answer remains grounded in the retrieved context. A response is considered faithful when all claims, explanations, and references can be traced directly to the supporting evidence supplied by the RAG pipeline.
In practice, teams often use an LLM-as-a-judge mechanism to evaluate faithfulness. The judge model reviews the answer alongside the retrieved context and determines whether the generated statements are substantiated. High faithfulness signals that the model is adhering to the information provided, whereas low faithfulness typically indicates issues upstream - most commonly retrieval noise, incomplete context, or ineffective ranking. Faithfulness is foundational and without strong grounding, no amount of model sophistication can compensate for weak evidence.
Correctness
Correctness measures whether the answer is factually accurate, independent of the provided context. This distinction is important as a model may produce a response that is entirely faithful to the retrieved documents, yet those documents may themselves be outdated, incomplete, or incorrect. As a result, correctness must be evaluated separately from faithfulness. High correctness indicates not only that the model respects the context, but that the underlying data is accurate and the model’s reasoning aligns with truth. When correctness is low but faithfulness is high, the responsibility typically shifts to data quality and knowledge governance rather than model behaviour. Correctness and faithfulness complement one another, and both are essential for dependable RAG performance.
Hallucination
Hallucination captures the extent to which a model introduces unsupported or fabricated content. It occurs when the model generates statements that are not grounded in the retrieved evidence, or when it extrapolates beyond what the context can justify. Hallucination reflects the statistical nature of language models, which predict the most likely continuation given a set of tokens, even when information is incomplete. This metric evaluates how frequently and how severely the model departs from verifiable facts. Modern approaches increasingly rely on verifier models that review generated statements and compare them to the retrieved context or external authoritative sources. These verification layers can identify fabricated claims and reduce the operational risk of deploying LLMs in high-stakes environments. Hallucination remains one of the most challenging issues in production systems. Reducing it meaningfully enhances user trust and overall system reliability.
Toxicity
Toxicity measures whether the generated content includes harmful, offensive, or unsafe language. Because many foundation models are trained on large public corpora, they may inadvertently reproduce undesirable patterns from the underlying data. Monitoring toxicity is essential for any organisation deploying LLMs at scale, particularly in customer-facing applications. High toxicity scores can create reputational risk, compromise user safety, and raise regulatory concerns. While toxicity does not measure accuracy, it defines whether the system behaves responsibly and aligns with organisational values. Toxicity evaluation should therefore be integrated into routine testing, particularly after model upgrades or prompt changes.
Bias
Bias measures the degree to which a model produces uneven or systematically skewed responses across demographic groups, topics, or scenarios. It reflects how well a system generalises across diverse populations and whether it exhibits preferential behaviour based on sensitive attributes.
For example, a model trained on unrepresentative medical images may perform well on one population but poorly on others. Such behaviour undermines fairness, reliability, and operational performance. Biased models often fail when exposed to real-world diversity, even if they perform strongly in controlled tests. Bias evaluation is not only a technical requirement but a governance expectation. Addressing it proactively strengthens trust, reduces downstream risk, and supports responsible AI deployment.
Mapping Metrics to Failure Modes
Below are a list of metrics that we have mapped to their failure modes. This should help engineering leaders as a quick checklist to know what could possibly be the reason behind the metrics not being desirable.
Low contextual relevancy = poor chunking, embedding drift, indexing issues
Low precision = retriever is including irrelevant items
Low recall = retriever or index missing relevant items
Good retrieval metrics but weak answers = ranking or generation issue
High hallucination with good retrieval = prompt misconfiguration or model limitations
Low faithfulness = reranker or retriever passing noisy context
Low correctness with high faithfulness = incorrect or outdated source data
Reliable online tools for RAG evaluation
There are many tools that can help you in this process by providing functions for described methods and automating evaluation pipelines. Some of the most popular ones are:
Open-source evaluation framework designed to simplify building and iterating on LLM applications. It allows you to unit test LLM output, while offering more than 30 LLM evaluation metrics that can be used out of the box. DeepEval supports both end-to-end and component-level evaluation across RAG systems, agents, chatbots, and virtually any LLM use case. It also includes advanced synthetic dataset generation, highly customizable metrics, and tools for red teaming and safety scanning to identify vulnerabilities of your product.
Ragas is designed for systematic evaluation process of LLM applications. The library supports workflow in which you can run evaluations, observe outcomes, and iterate based on consistent evidence. Ragas also allows you to define custom metrics or use the built-in ones, and includes convenient tools for dataset management and result tracking. With integrations for frameworks like LangChain and LlamaIndex, it can be easily incorporated into existing development pipelines.
TruLens is an open-source evaluation and monitoring library for Large Language Model (LLM) applications and AI agents. It is especially useful for building and evaluating RAG systems, agents, chatbots or summarizers. It offers variety of built-in feedback functions such as context relevance, groundedness, answer relevance, coherence, toxicity, sentiment or bias to systematically score and trace every run. It can also be integrated with telemetry standards for production-ready tracing, and it supports popular stacks like LangChain and LlamaIndex.
Evaluation process has never been easier to implement and use in all types of LLM applications. Evaluating all kinds of different metrics leads to more stable and production ready pipelines and many tools today offer great variety of metrics and tracking frameworks which allow you access to the best possible results and user satisfaction.
The Path to Dependable RAG Systems
Building a reliable RAG system is ultimately a question of engineering coherence. Every stage, splitting, embedding, retrieval, ranking, and generation, contributes to the fidelity of the final answer. When even one component drifts, the entire pipeline reflects that drift. And without structured evaluation in place, this degradation remains invisible until it affects end users.
Organisations that approach RAG with discipline, treating retrieval as a measurable subsystem, embeddings as versioned assets, and evaluation as an ongoing operational requirement, unlock far more than incremental accuracy gains. They establish predictability. They build resilience. And they create the confidence needed to scale AI across critical workflows. These systems are sensitive by design, which means they must be governed with rigor, monitored continuously, and improved systematically. When implemented with this mindset, RAG becomes a durable capability that strengthens decision-making and creates measurable strategic advantage.
At Algorithmic, we support startups, scaleups, and enterprises in deploying RAG systems that meet these standards. We work across the full product lifecycle and bring deep expertise in three areas, which are end-to-end product development, applied machine learning & AI, and data analytics & infrastructure engineering. Our teams have implemented RAG solutions in environments that require both precision and scale, and we understand what it takes to operationalise these systems reliably.
If you’d like to follow our research, perspectives, and case insights, connect with us on LinkedIn, Instagram, Facebook, X or simply write to us at info@algorithmic.co



